在当今的互联网世界中,Linux凭借其稳定、高效的网络协议栈实现,成为服务器、云计算和网络设备领域的基石。理解Linux网络层的核心原理,是每一位希望深入掌握现代网络通信、优化应用性能的开发者和运维工程师的必修课。它不仅揭示了数据如何在网络中流转,更是排查复杂网络问题、进行深度性能调优的理论基础。
1. 网络层的基础概念与核心作用
1.1 网络层的核心定位
网络层位于TCP/IP协议栈的第三层,介于传输层和数据链路层之间。一个生动的比喻是现实世界的邮政系统:传输层如同寄信人,负责准备信件内容并写好信封;数据链路层如同社区邮递员,负责在邻里间传递信件;而网络层就是城市间的邮局系统,其核心职责是在不同网络间进行信件的路由和转发。
Linux网络层承担着几项关键任务:
- 跨网络透明传输:屏蔽不同底层网络(如以太网、Wi-Fi)的硬件差异,为上层应用提供统一的逻辑网络访问接口。
- 路由选择:在网络节点(路由器)间为数据包选择一条最优的传输路径。
- 拥塞控制:协调整个网络的数据流,避免局部或全局的网络过载。
- 网际互连:通过统一的IP协议,将各种异构的物理网络连接成一个逻辑上统一的全球互联网。
1.2 IP协议的基础概念
在深入Linux内核实现之前,必须首先掌握其实现的蓝本——IP协议的基础概念。IP(Internet Protocol)是网络层最核心的协议,它定义了数据在网络中传输的基本格式和寻址规则。
关键术语解析:
- 主机 (Host):配置了IP地址但不进行路由控制(即不转发其他主机的数据包)的设备,如我们的个人电脑、服务器。
- 路由器 (Router):既能配置IP地址,又能根据IP地址进行路由控制(转发)的设备,是网络互联的枢纽。
- 节点 (Node):主机和路由器的统称。
一个常见的误解是:同一局域网内的两台主机通信不经过网络层。理论上,它们可以通过数据链路层(如MAC地址)直接通信。但在现代操作系统中,即使是同一网段的通信,通常也会“经过”IP层处理,因为协议栈设计统一,且主机本身也具有本机路由表。
2. IP协议头结构深度解析
2.1 IP头结构:网络通信的“信封格式”
每个IP数据包都像一个加了标准化信封的信件,IP头就是这个信封的格式规范。在Linux内核源码中,IP头由 iphdr 结构体精确定义,位于 include/uapi/linux/ip.h 文件中。
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD) // 小端字节序模式
__u8 ihl:4, // 首部长度(4位)
version:4; // IP协议版本(4位)
#elif defined(__BIG_ENDIAN_BITFIELD) // 大端字节序模式
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos; // 服务类型字段(8位)
__be16 tot_len; // 16位IP数据报总长度
__be16 id; // 16位标识字段
__be16 frag_off; // 分片标志和偏移(3位标志+13位偏移)
__u8 ttl; // 8位生存时间
__u8 protocol; // 上层协议类型(8位)
__be16 check; // 16位首部校验和
__be32 saddr; // 源IP地址
__be32 daddr; // 目的IP地址
/* 选项字段从这里开始 */
};
该结构体的设计巧妙处理了字节序问题,并通过位域精确匹配协议规范。为了直观展示其内存布局,可以参考下图:
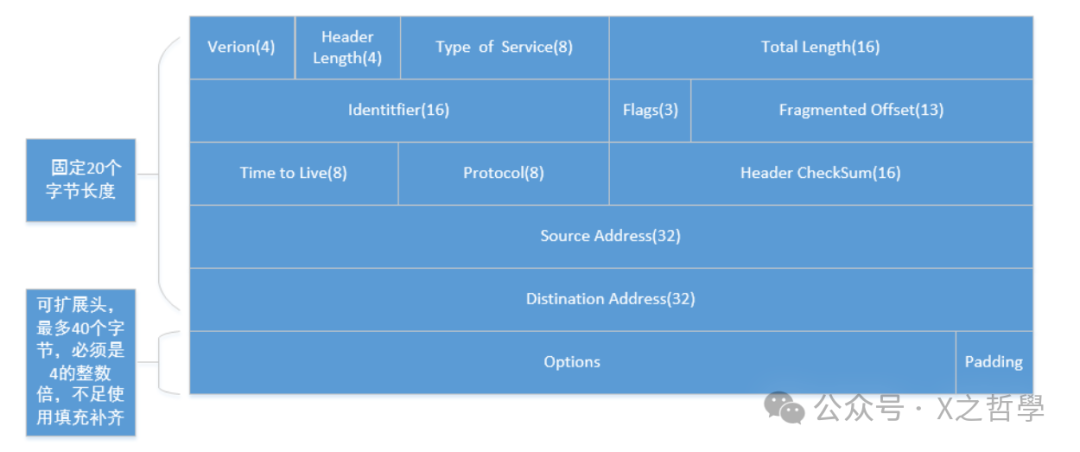
2.2 核心字段详解
版本与首部长度:
- 版本 (Version, 4位):标识IP协议版本,IPv4值为4,IPv6值为6。
- 首部长度 (IHL, 4位):以4字节为单位表示IP头长度。最小值为5(即20字节标准头),最大值为15(即60字节,包含最多40字节选项)。
服务类型 (TOS):
这个字段相当于邮件的优先级和加急标签。它包含3个优先权位(已基本弃用)和4个TOS位,分别代表:最小延时、最大吞吐量、最高可靠性和最小成本。这些特性是互斥的,通常根据应用类型选择其一。
- SSH、Telnet等交互式应用会选择最小延时。
- FTP、大文件下载等应用会选择最大吞吐量。
标识与分片控制:
- 标识 (Identification, 16位):唯一标识主机发送的每一个数据报。若数据报被分片,则所有分片共享同一个标识符,便于接收端重组。
- 分片标志 (Flags, 3位):
- 第一位:保留。
- 第二位:禁止分片 (DF)。若置1,则路由器发现数据包超过出口MTU时会丢弃它并返回ICMP错误。
- 第三位:更多分片 (MF)。除最后一个分片外,其他分片此位置1,告知接收端还有后续分片。
- 分片偏移 (Fragment Offset, 13位):指示当前分片在原始数据报中的位置,以8字节为单位。这决定了分片必须按8字节边界对齐。
生存时间 (TTL):
TTL就像邮件的有效期限。数据包每经过一个路由器(一跳),该值就减1。当TTL减至0时,数据包被丢弃,并通常产生一个ICMP超时消息返回给源主机。其主要目的是防止因路由环路导致的数据包无限循环。Linux系统的默认初始值通常为64。
协议字段 (Protocol):
指示承载的上层协议类型,使接收方能将数据正确交付给相应的传输层或网络层协议处理。常见值:ICMP=1, TCP=6, UDP=17。
2.3 校验和机制
IP头的校验和用于检测头部在传输过程中是否因噪声等原因出错。它只校验IP头部,不包含数据部分。发送方计算校验和填入该字段,接收方重新计算并比对,若不一致则丢弃该包。这种机制类似于信件封口处的防拆标记,确保了“信封”本身的完整性。
3. IP层核心机制详解
3.1 分片与重组:大件物品的拆装运输
当需要发送的数据大小超过数据链路层的传输能力上限(MTU)时,IP层需要执行分片。这好比运输大型家具时需要拆分成部件分别运输,到达目的地后再重新组装。
MTU与MSS:
- MTU (最大传输单元):数据链路层一帧所能承载的最大数据量。以太网标准MTU通常为1500字节。
- MSS (最大报文段长度):TCP协议能发送的单个报文段的最大数据量。通常为 MTU 减去 IP头(20) 和 TCP头(20),即 1460 字节。
分片规则:
- 除了最后一个分片,其他所有分片的长度必须是8字节的整数倍。
- 所有属于同一原始数据报的分片共享相同的标识符。
- 除最后一个分片外,其他分片的MF标志都置1。
- 接收端根据标识符、偏移量和MF标志将所有分片正确排序并重组。
分片重组是一个复杂的状态管理过程。Linux内核使用分片缓存 (fragment cache) 来管理属于同一个数据报的各个分片。每个等待重组的IP数据报对应一个 ipq 数据结构,只有所有分片都到达后,才进行重组并传递给上层协议。
3.2 路径MTU发现:智能选择包装尺寸
分片和重组会消耗路由器与主机的CPU和内存资源,并可能增加丢包率。为了避免分片,现代网络广泛使用路径MTU发现 (PMTUD) 机制。这就像快递公司提前探查整条运输路线上最窄的桥梁,然后一次性选用合适的包装尺寸。
应用程序可以通过设置套接字选项 IP_MTU_DISCOVER 来启用此功能:
- 内核会自动探测从源到目的路径上的最小MTU。
- 后续发送的数据包大小将不超过这个PMTU。
- 如果应用尝试发送超过PMTU的数据(且不允许分片),系统调用(如
sendto)将返回EMSGSIZE错误,提示应用应减小数据量。
3.3 路由选择:网络中的导航系统
路由选择是IP层的核心智能所在。Linux内核中的路由子系统如同一个复杂的汽车导航系统,根据路由表、策略、实时状态等信息为每个数据包选择最佳出口路径。
Linux的路由系统非常强大,包括:
- 路由表:存储网络前缀、下一跳、出口设备等核心路径信息。可以通过
ip route 命令查看和管理。
- 路由缓存:为最近使用过的路由建立快速缓存,加速查找(现代内核中已被更高级的机制替代)。
- 策略路由:基于源地址、服务类型(TOS)、防火墙标记等条件,选择不同的路由表,实现灵活流量调度。
- 多路径路由:支持到同一目的地的多条等价路径,可以实现负载均衡和故障自动转移。
理解Linux路由是掌握网络协议栈和进行高级Linux运维的关键。
4. Linux内核实现深度剖析
4.1 核心数据结构:网络数据的载体
sk_buff 结构体
sk_buff (socket buffer) 是Linux网络协议栈中最重要的数据结构,没有之一。它贯穿从网卡驱动到应用套接字的整个数据传输过程。可以把它想象成物流系统中的标准集装箱,无论运输什么货物(TCP段、UDP包、原始数据),都用相同规格的集装箱装载,便于各环节(协议层)高效处理。
struct sk_buff {
/* 这两个字段必须在开头,用于链表管理 */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk; // 所属的套接字
ktime_t tstamp; // 时间戳
struct net_device *dev; // 当前所在的网络设备
/* 数据区指针 - 设计的精髓 */
char *head; // 分配的数据缓冲区起始地址
char *data; // 当前协议层有效数据的起始地址
char *tail; // 当前协议层有效数据的结束地址
char *end; // 分配的数据缓冲区结束地址
unsigned int len; // 当前有效数据长度 (data到tail)
unsigned int data_len; // 分片数据的长度
__u16 mac_len; // MAC头长度
__u16 hdr_len; // 可写的头空间
/* 其他重要字段省略... */
};
四个关键指针 (head, data, tail, end) 的关系是其设计核心,如下图所示:
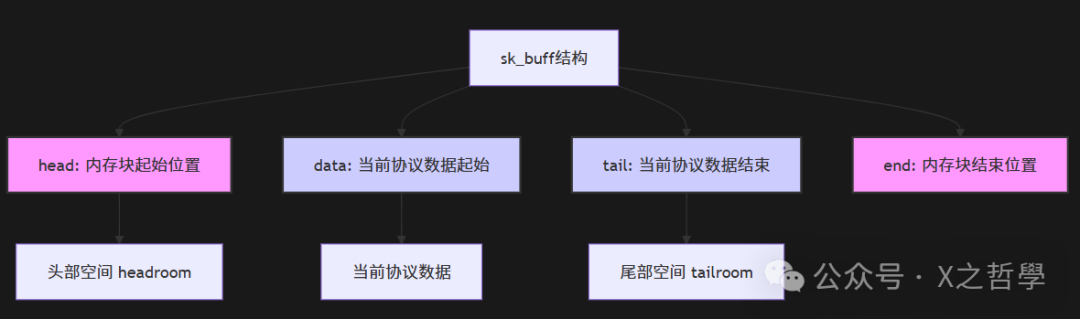
这种设计允许协议层在不进行昂贵的内存复制(拷贝)的情况下添加或移除头部信息。例如,当数据从传输层(TCP)传递到网络层(IP)时,IP层只需要在 head 和 data 之间的空闲区域(head room)填入IP头,然后将 data 指针向上移动即可。这极大地提升了协议栈处理性能。
网络设备结构体
net_device 结构体代表系统中的一个网络接口,无论是物理网卡(eth0)还是虚拟设备(tun0, docker0)。
struct net_device {
char name[IFNAMSIZ]; // 设备名如 "eth0"
unsigned long mem_end;
unsigned long mem_start;
unsigned long base_addr; // 设备I/O地址
unsigned int irq; // 设备中断号
unsigned int mtu; // 最大传输单元
unsigned short type; // 硬件类型(ARPHRD_ETHER等)
/* 操作函数指针 - 设备驱动的“接口” */
int (*open)(struct net_device *dev);
int (*stop)(struct net_device *dev);
netdev_tx_t (*hard_start_xmit)(struct sk_buff *skb,
struct net_device *dev);
/* 统计信息 */
struct net_device_stats stats;
/* 设备私有数据,供驱动使用 */
void *priv;
/* 更多字段省略... */
};
4.2 数据包发送流程:从应用到网络
让我们跟踪一个UDP数据包的发送过程,直观了解IP层如何处理出站数据:
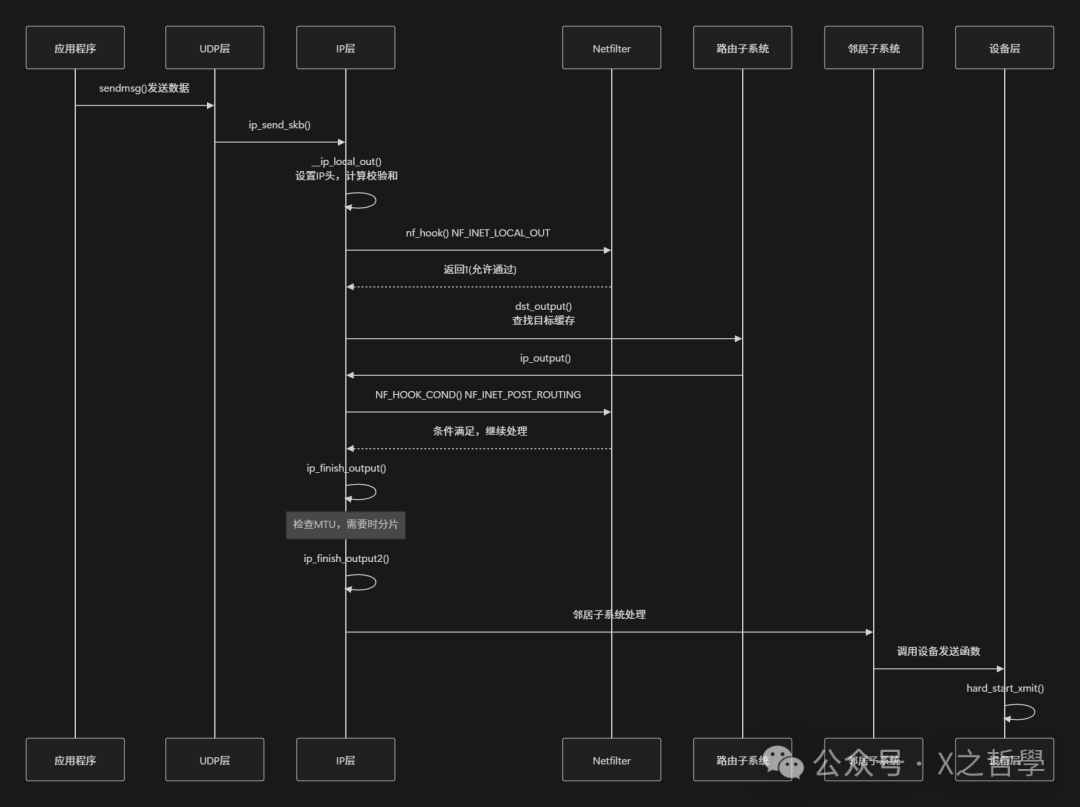
关键函数分析
- ip_send_skb():UDP层调用此函数将skb交给IP层。
int ip_send_skb(struct net *net, struct sk_buff *skb)
{
int err;
err = ip_local_out(skb);
if (err) {
if (err > 0)
err = net_xmit_errno(err);
if (err)
IP_INC_STATS(net, IPSTATS_MIB_OUTDISCARDS);
}
return err;
}
- __ip_local_out():设置IP头基本信息并计算校验和。
int __ip_local_out(struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len); // 设置总长度
ip_send_check(iph); // 计算并填充校验和
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT, skb, NULL,
skb_dst(skb)->dev, dst_output);
}
- ip_finish_output():检查是否需要分片,然后进入发送环节。
static int ip_finish_output(struct sk_buff *skb)
{
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb))
return ip_fragment(skb, ip_finish_output2); // 需要分片
else
return ip_finish_output2(skb); // 直接发送
}
4.3 数据包接收流程:从网络到应用
接收流程与发送流程方向相反,同样会经过IP层的关键处理:
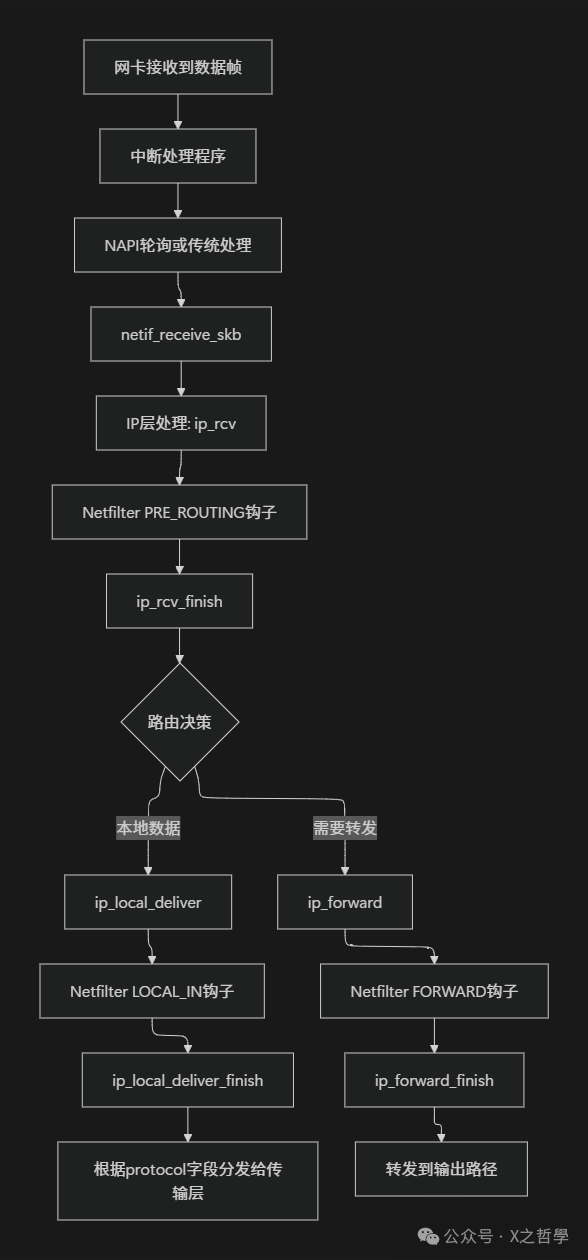
关键处理函数
- ip_rcv():IP层的入口函数,进行基本的有效性检查。
int ip_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
// 基本校验:版本、长度、校验和...
// ...
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
- ip_rcv_finish():完成主要处理,包括早期解复用(用于分片重组)和最重要的路由查找。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// ... 路由查找逻辑 (ip_route_input_noref) ...
// 路由结果决定了数据包去向:本地?转发?
if (skb_dst(skb)->input == ip_local_deliver)
return ip_local_deliver(skb); // 传递给本机上层协议
else
return dst_input(skb); // 转发给其他主机
}
-
ip_local_deliver_finish():根据IP头的protocol字段,将数据包分发给注册的传输层处理函数(如TCP或UDP)。
static int ip_local_deliver_finish(struct net *net, struct sock *sk,
struct sk_buff *skb)
{
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot)
return ipprot->handler(skb); // 例如调用 tcp_v4_rcv 或 udp_rcv
// ... 如果未注册,则可能发送ICMP协议不可达...
}
4.4 Netfilter框架:内核级的防火墙与包处理
Netfilter是Linux内核中一个功能强大的包过滤和修改框架。它在协议栈的关键路径上预设了一系列钩子点 (hook points),允许内核模块(如iptables、连接跟踪)在这些点上拦截、检查、修改或丢弃数据包。可以把它想象成邮局系统中的一系列安全检查站和分拣机,在信件处理的各个阶段进行审查和操作。
IP层中定义的5个Netfilter钩子点至关重要:
- NF_INET_PRE_ROUTING:数据包进入IP层,完成完整性检查后立即执行。常用于目的地址转换(DNAT)和连接跟踪的首次处理。
- NF_INET_LOCAL_IN:经过路由判断,目的地是本机的数据包,在传递给传输层之前执行。常用于防火墙的INPUT链过滤。
- NF_INET_FORWARD:经过路由判断,需要被转发(非本机)的数据包,在执行转发前执行。常用于防火墙的FORWARD链过滤。
- NF_INET_LOCAL_OUT:由本机进程产生的出站数据包,在进入IP层处理后、路由决策之前执行。常用于防火墙的OUTPUT链和源地址转换(SNAT)的准备。
- NF_INET_POST_ROUTING:所有即将离开IP层(无论是本地产生还是转发)的数据包,在发送到网卡驱动之前执行。这是进行SNAT的最后时机。
5. 性能优化与高级特性
5.1 零拷贝与分散/聚集I/O
为了减少数据在内核态和用户态之间不必要的复制,Linux实现了多种优化:
- 零拷贝 (Zero-copy):通过
sendfile() 系统调用,数据可以直接从磁盘文件描述符传输到网络套接字,无需经过用户空间缓冲区。这对Web服务器(发送静态文件)等场景性能提升巨大。
- 分散/聚集 I/O (Scatter/Gather I/O):使用
readv()/writev() 或支持 MSG_SPLICE_PAGES 标志的 sendmsg(),允许单个系统调用处理多个不连续的内存缓冲区,减少了系统调用次数和内存整理开销。
5.2 GSO/GRO:卸载处理到硬件
现代高速网络环境下,每包处理开销成为瓶颈。GSO/GRO通过聚合处理来提升效率。
- GSO (Generic Segmentation Offload, 通用分段卸载):在发送端,将大数据块的分段操作(TCP为分段,UDP/IP为分片)尽可能推迟,直到数据即将交付给网卡驱动时。如果网卡支持TSO (TCP Segmentation Offload),则甚至可以将分段工作完全卸载到网卡硬件执行。
- GRO (Generic Receive Offload, 通用接收卸载):在接收端,将属于同一个流(如TCP连接)的多个小数据包在底层(网卡驱动或协议栈入口)合并成一个大的数据包,再提交给上层协议处理,显著减少协议栈的处理次数。
5.3 多队列与RPS/RFS
为充分利用多核CPU性能,Linux网络栈支持多队列并行处理:
- 多队列网卡:现代网卡硬件支持多个独立的发送和接收队列,每个队列可以绑定到不同的CPU核心上,实现硬中断的并行处理。
- RPS (Receive Packet Steering, 接收包引导):一种软件方案,在单队列网卡或仍需软件处理时,根据数据包的哈希值(如IP和端口四元组)将其分配到不同的CPU核心上进行后续处理(在软中断层面)。
- RFS (Receive Flow Steering, 接收流引导):RPS的增强版,它不仅考虑数据包哈希,还考虑应用线程所在的CPU。目标是让处理某个连接的应用线程和该连接的数据包软中断在同一个CPU核心上执行,从而提高CPU缓存命中率。
6. 实用工具与调试技巧
6.1 网络配置与诊断工具
Linux提供了从基础到高级的丰富网络工具链。
| 工具类别 |
工具名称 |
主要功能与说明 |
| 传统工具 |
ifconfig, route, netstat |
经典的配置与查看工具,逐渐被 iproute2 套件替代。 |
| 现代工具 |
ip (来自iproute2) |
全能选手。ip addr, ip route, ip link 分别管理地址、路由、链路。 |
|
ss (来自iproute2) |
替代 netstat,更快速、更详细地显示套接字统计信息。ss -tlnp 常用。 |
|
ethtool |
查询和设置网卡驱动与硬件参数,如速度、双工、卸载功能、统计信息等。 |
| 诊断工具 |
tcpdump |
命令行抓包分析利器,功能强大,配合过滤表达式精准捕获流量。 |
|
wireshark (或 tshark) |
图形化/命令行深度协议分析工具,拥有强大的解析和可视化能力。 |
|
traceroute / mtr |
跟踪数据包路径,排查网络延迟和路由问题。mtr 是动态持续跟踪。 |
|
nmap |
端口扫描和网络探测,用于安全审计和网络发现。 |
6.2 内核参数调优
通过 /proc 文件系统和 sysctl 命令可以动态调整网络栈行为,优化性能或适应特定场景。
# 1. 查看IP层统计信息(有助于发现丢包、错误)
cat /proc/net/snmp | grep -A 1 Ip:
# 2. 调整核心参数
sysctl -w net.ipv4.ip_forward=1 # 启用IP转发(路由器/容器宿主机需要)
sysctl -w net.ipv4.tcp_window_scaling=1 # 启用TCP窗口缩放,支持大带宽高延迟网络
sysctl -w net.core.rmem_max=16777216 # 增大最大接收缓冲区大小
sysctl -w net.core.wmem_max=16777216 # 增大最大发送缓冲区大小
sysctl -w net.ipv4.tcp_congestion_control=bbr # 更改TCP拥塞控制算法为BBR
# 3. 查看网络设备统计信息(观察丢包、错包)
cat /proc/net/dev
# 或使用更易读的方式
ip -s link show eth0
6.3 性能监控指标
监控以下关键指标有助于评估网络栈健康度和定位瓶颈。
| 监控点 |
关键指标 |
说明与可能问题 |
IP层 (/proc/net/snmp) |
OutDiscards |
出站数据包丢弃数。可能由于缓冲区满、路由问题。 |
|
InHdrErrors |
IP头错误计数。可能由校验和错误、版本不符等引起。 |
|
ReasmFails |
分片重组失败计数。分片丢失或超时导致。 |
网络设备 (ethtool -S) |
rx/tx_dropped |
接收/发送丢包数。驱动或队列问题。 |
|
rx/tx_errors |
接收/发送错误数。物理链路或硬件问题。 |
|
队列长度 |
发送/接收队列的积压长度。持续过高意味着处理不过来。 |
系统级 (top, /proc/interrupts, mpstat) |
软中断 (si) |
观察 NET_RX 和 NET_TX 的CPU占用。单核过高可考虑RPS。 |
|
网络中断分布 |
检查中断是否均匀分配到多个CPU核心。 |
|
上下文切换率 |
过高的网络IO可能导致频繁的上下文切换。 |
7. 实际应用与代码示例
7.1 原始套接字示例:构造IP数据包
以下C程序演示了如何使用原始套接字 (Raw Socket) 自行构造并发送一个IP数据包。这常用于网络工具开发或协议学习。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/ip.h>
#include <netinet/tcp.h>
#include <arpa/inet.h>
// 简单的IP校验和计算函数 (RFC 1071)
unsigned short checksum(void *b, int len) {
unsigned short *buf = b;
unsigned int sum = 0;
unsigned short result;
for (sum = 0; len > 1; len -= 2)
sum += *buf++;
if (len == 1)
sum += *(unsigned char *)buf;
sum = (sum >> 16) + (sum & 0xFFFF);
sum += (sum >> 16);
result = ~sum;
return result;
}
int main() {
int sockfd;
struct sockaddr_in dest;
char packet[4096];
// 1. 创建原始套接字,指定协议为IPPROTO_RAW(我们提供IP头)
if ((sockfd = socket(AF_INET, SOCK_RAW, IPPROTO_RAW)) < 0) {
perror("socket() error");
exit(1);
}
// 2. 设置IP_HDRINCL选项,告诉内核我们不希望它自动添加IP头
int one = 1;
const int *val = &one;
if (setsockopt(sockfd, IPPROTO_IP, IP_HDRINCL, val, sizeof(one)) < 0) {
perror("setsockopt() error");
exit(1);
}
memset(packet, 0, 4096);
// 3. 构造IP头
struct iphdr *ip = (struct iphdr *)packet;
ip->version = 4; // IPv4
ip->ihl = 5; // 首部长度:5 * 4 = 20字节 (无选项)
ip->tos = 0; // 普通服务类型
ip->tot_len = htons(40); // 总长度:IP头20 + TCP头20 = 40字节
ip->id = htons(54321); // 数据包标识
ip->frag_off = 0; // 不分片
ip->ttl = 64; // 生存时间
ip->protocol = IPPROTO_TCP; // 上层协议:TCP
ip->saddr = inet_addr("192.168.1.100"); // 源IP(可伪造,但出路由可能有问题)
ip->daddr = inet_addr("192.168.1.1"); // 目的IP
// 注意:校验和初始为0
ip->check = checksum((unsigned short *)ip, ip->ihl * 4);
// 4. 构造一个简单的TCP头(仅示例,无有效载荷,校验和也未规范计算)
struct tcphdr *tcp = (struct tcphdr *)(packet + (ip->ihl * 4));
tcp->source = htons(12345); // 源端口
tcp->dest = htons(80); // 目的端口(HTTP)
tcp->seq = htonl(1); // 序列号
tcp->ack_seq = 0; // 确认号
tcp->doff = 5; // TCP数据偏移:5 * 4 = 20字节
tcp->fin = 0;
tcp->syn = 1; // SYN标志(发起连接)
tcp->rst = 0;
tcp->psh = 0;
tcp->ack = 0;
tcp->urg = 0;
tcp->window = htons(5840); // 窗口大小
tcp->check = 0; // TCP校验和需要计算伪头部,此处省略
tcp->urg_ptr = 0;
// 5. 设置目的地址结构
memset(&dest, 0, sizeof(dest));
dest.sin_family = AF_INET;
dest.sin_addr.s_addr = ip->daddr;
// 6. 发送数据包
if (sendto(sockfd, packet, ntohs(ip->tot_len), 0,
(struct sockaddr *)&dest, sizeof(dest)) < 0) {
perror("sendto() error");
exit(1);
}
printf("Raw IP packet sent. Size: %d bytes\n", ntohs(ip->tot_len));
close(sockfd);
return 0;
}
注意:运行此程序通常需要root权限。构造的SYN包可能触发目标主机的响应。
7.2 内核模块示例:注册IP协议处理程序
这个简单的内核模块示例展示了如何在内核中注册一个自定义的IP协议号处理程序,用于处理特定协议类型的数据包。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/netdevice.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <net/protocol.h>
#define MY_PROTOCOL 250 // 选择一个实验性协议号 (范围 143-252)
// 自定义协议处理函数
static int my_protocol_handler(struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
printk(KERN_INFO "MyProtocol: Received packet for protocol %d\n", iph->protocol);
printk(KERN_INFO "MyProtocol: From: %pI4, To: %pI4\n", &iph->saddr, &iph->daddr);
printk(KERN_INFO "MyProtocol: Packet length: %d\n", ntohs(iph->tot_len));
// 这里可以添加对自定义协议数据的解析和处理逻辑
// ...
// 消费掉这个skb(因为我们“处理”了它)
kfree_skb(skb);
return 0;
}
// 错误处理函数(可选)
static void my_protocol_err(struct sk_buff *skb, u32 info)
{
printk(KERN_INFO "MyProtocol: Error in packet processing\n");
}
// 定义协议操作结构体
static struct net_protocol my_protocol = {
.handler = my_protocol_handler,
.err_handler = my_protocol_err,
.no_policy = 1,
};
static int __init my_module_init(void)
{
int ret;
printk(KERN_INFO "MyProtocol: Registering custom IP protocol %d\n", MY_PROTOCOL);
// 向内核注册协议处理程序
ret = inet_add_protocol(&my_protocol, MY_PROTOCOL);
if (ret < 0) {
printk(KERN_ERR "MyProtocol: Failed to register protocol: %d\n", ret);
return ret;
}
printk(KERN_INFO "MyProtocol: Custom protocol registered successfully\n");
return 0;
}
static void __exit my_module_exit(void)
{
// 注销协议
inet_del_protocol(&my_protocol, MY_PROTOCOL);
printk(KERN_INFO "MyProtocol: Custom protocol unregistered\n");
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("Example: Custom IP Protocol Handler");
MODULE_VERSION("1.0");
编译并加载此模块后,所有到达本机且IP头部protocol字段为250的数据包,都会由my_protocol_handler函数处理,而不会被其他标准协议(如TCP/UDP)接收。
8. 总结
通过本文从理论到实现、从用户态到内核态的梳理,我们对Linux网络层(IP层)有了一个系统而深入的认识:
- 分层与抽象:IP层成功地在复杂的物理网络之上构建了一个统一的、基于目的地址的逻辑网络,这是互联网得以互联互通的基石。
- 协议是规范,内核是实现:
iphdr结构体是RFC 791中IPv4协议规范在Linux内核中的精确映射,其设计考虑了内存效率与跨平台兼容性。
- 核心机制保障可靠性与效率:分片/重组处理了大包传输问题,TTL防止了路由环路,路由选择算法是网络的智能导航,校验和保障了头部完整性。
- 数据结构与流程是内核的灵魂:
sk_buff作为贯穿始终的载体,其精妙的指针设计是实现高性能零拷贝操作的关键。清晰的发送与接收流程是理解数据包生命周期的路线图。
- 可扩展性与控制力:Netfilter框架提供了无与伦比的灵活性和控制能力,使得Linux可以轻松扮演防火墙、路由器、网关、VPN端点等多种角色。
- 性能优化永无止境:从零拷贝到GSO/GRO,从多队列到RPS/RFS,Linux内核持续演进,以应对日益增长的网络速度和复杂性挑战。
- 强大的工具生态:成熟的命令行工具、可调的内核参数和丰富的性能指标,使得监控、调试和优化Linux网络栈成为一个可操作、可深度介入的过程。
掌握Linux网络层,意味着你不仅理解了网络通信的基本原理,更获得了在复杂系统中定位问题、优化性能、甚至定制功能的底层能力。这正是深入系统编程和网络工程的核心价值所在。
 发表于 2025-12-16 22:53:45
|
查看: 178|
回复: 0
发表于 2025-12-16 22:53:45
|
查看: 178|
回复: 0
