2025年12月,在CUDA发布近二十年后,NVIDIA推出了全新CUDA Tile(简称cuTile)编程模型。作为CUDA 13.1的核心更新,cuTile通过“Tile-based”的编程模型重构了GPU内核的编写方式,旨在让开发者无需深入CUDA C++底层即可编写高性能Kernel。这一变化迅速在开发者社区中引发了关于自定义算子开发、与开源项目Triton的竞争关系,以及其能否成为Python生态下默认GPU编程入口的热烈讨论。
尽管cuTile仍处于早期阶段,但从其设计理念和社区初步反馈来看,它已展现出成为新一代GPU编程范式的潜力。随着相关探索与实践的增多,其未来定位也逐渐清晰。
cuTile:让开发者回归算法逻辑的GPU编程新范式
长期以来,CUDA的SIMT(单指令多线程)模型要求开发者以“线程”为粒度进行思考,将计算任务分解为成千上万的线程,并深入理解内存合并、Warp调度等硬件细节。随着AI训练等复杂工作负载的指数级增长,这种方式的开发门槛和优化成本日益增高。
cuTile的推出正是对这一挑战的回应。它允许开发者聚焦于算法本身,而将硬件性能的极致挖掘交给框架和编译器。本质上,cuTile是一种面向NVIDIA GPU的并行编程模型,也是一个基于Python的领域专用语言。它能够自动利用Tensor Core等先进硬件特性,并在不同架构的GPU间保持良好的可移植性。

Tile 模型(左图)将数据划分为块,由编译器映射到线程;SIMT 模型(右图)则将数据同时映射到块和线程
其技术核心在于CUDA Tile IR(中间表示),它引入了一套虚拟指令集,使得硬件能够原生支持以“Tile”(数据块)为单位的操作。开发者只需编写高层次、以Tile为中心的代码,编译器便会自动处理其在底层线程、内存层次及张量核心上的映射与优化。
二十年后再推新范式:NVIDIA的生态攻防战
在CUDA发布近二十年后,NVIDIA选择推出全新的编程范式,这不仅是技术演进,更是对行业格局变化的战略回应。
一方面,爆炸式增长的AI工作负载催生了海量的自定义算子需求,传统CUDA C++开发周期长、调试复杂、人才稀缺的问题日益凸显。cuTile的目标便是在不牺牲性能的前提下,提供一个对Python友好的高层接口,显著降低GPU编程门槛,加速算法迭代。
另一方面,外部竞争环境也在倒逼NVIDIA加固其软件生态护城河。AMD ROCm、Intel oneAPI等跨平台方案试图打破CUDA的垄断,而OpenAI Triton等由顶尖AI公司推出的开源DSL,则从算子开发层面向CUDA生态发起了直接挑战。有行业分析指出,cuTile是NVIDIA“试图加深CUDA护城河的重要举措”,通过其闭源工具链重新掌握编译器优化通道,以保持性能领先优势。
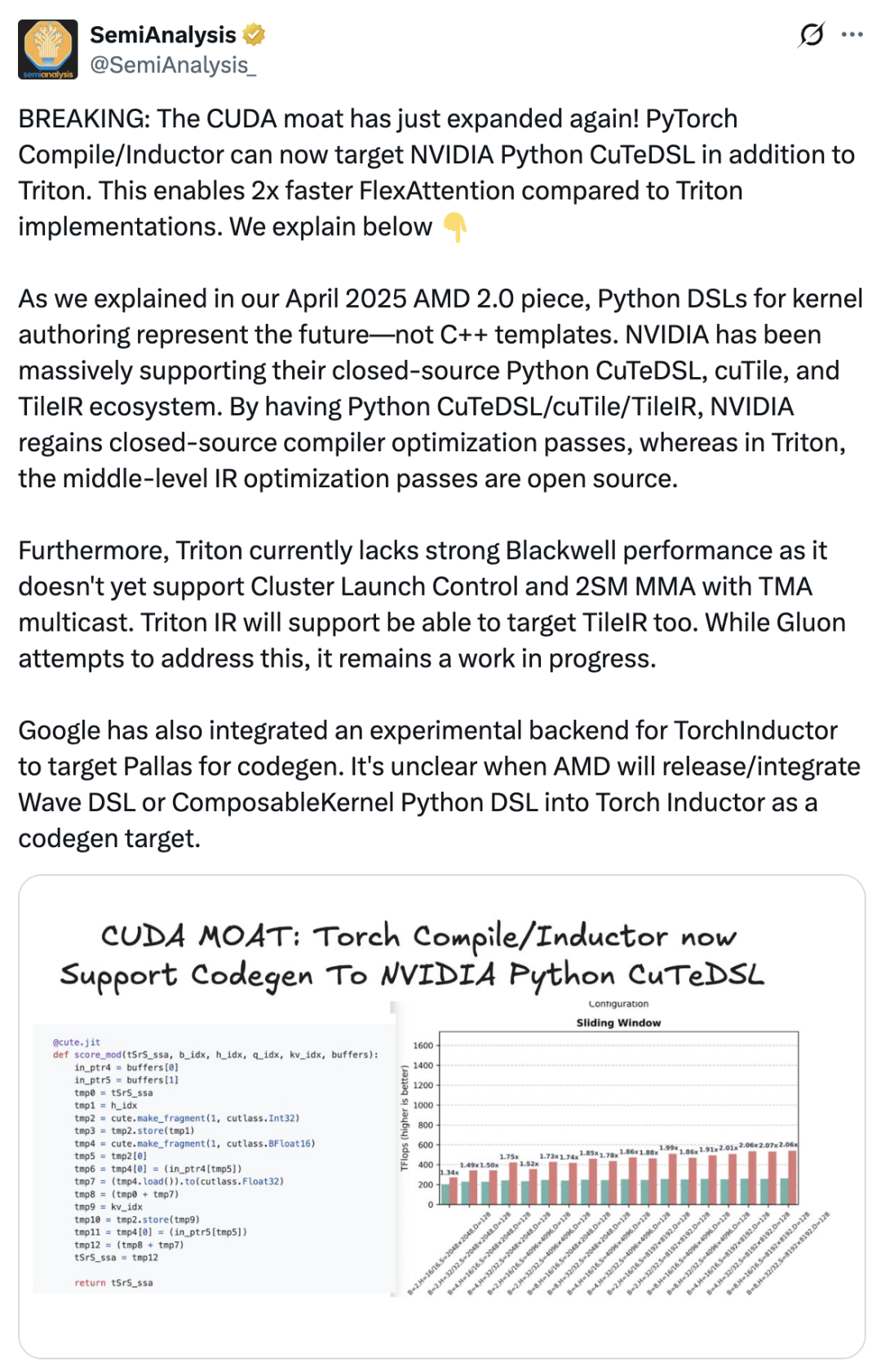
Tile思维是创新还是模仿?开发者社区怎么看
cuTile问世后,市场反响毁誉参半。一部分开发者对其引入的新DSL(领域特定语言)表达了疑虑,认为增加了学习成本。更有观点质疑其原创性,认为cuTile像是Triton、Mojo等现有技术的整合体。CUDA初始团队成员Nicholas Wilt也公开评论,怀疑cuTile是直接针对Triton而开发的。
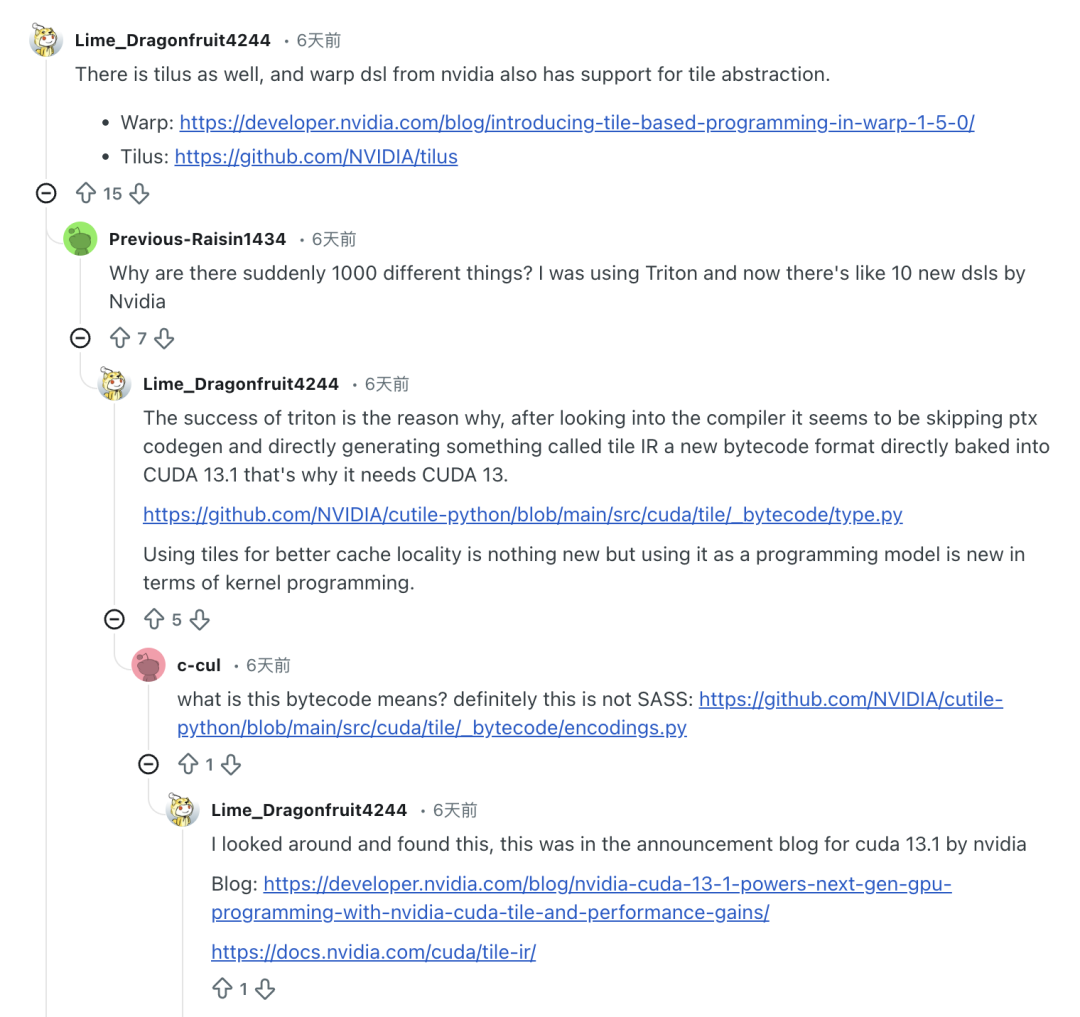
然而,更多深入体验后的开发者给出了积极评价。他们认为cuTile的核心魅力在于其“Tile思维”所带来的高层次抽象。开发者不再需要显式管理线程协作、数据搬运与同步,只需定义数据块(Tile)及块上的操作,编译器即可自动生成高效内核。这种范式被许多用户赞为“颠覆性的”,让人能真正专注于算法本身。
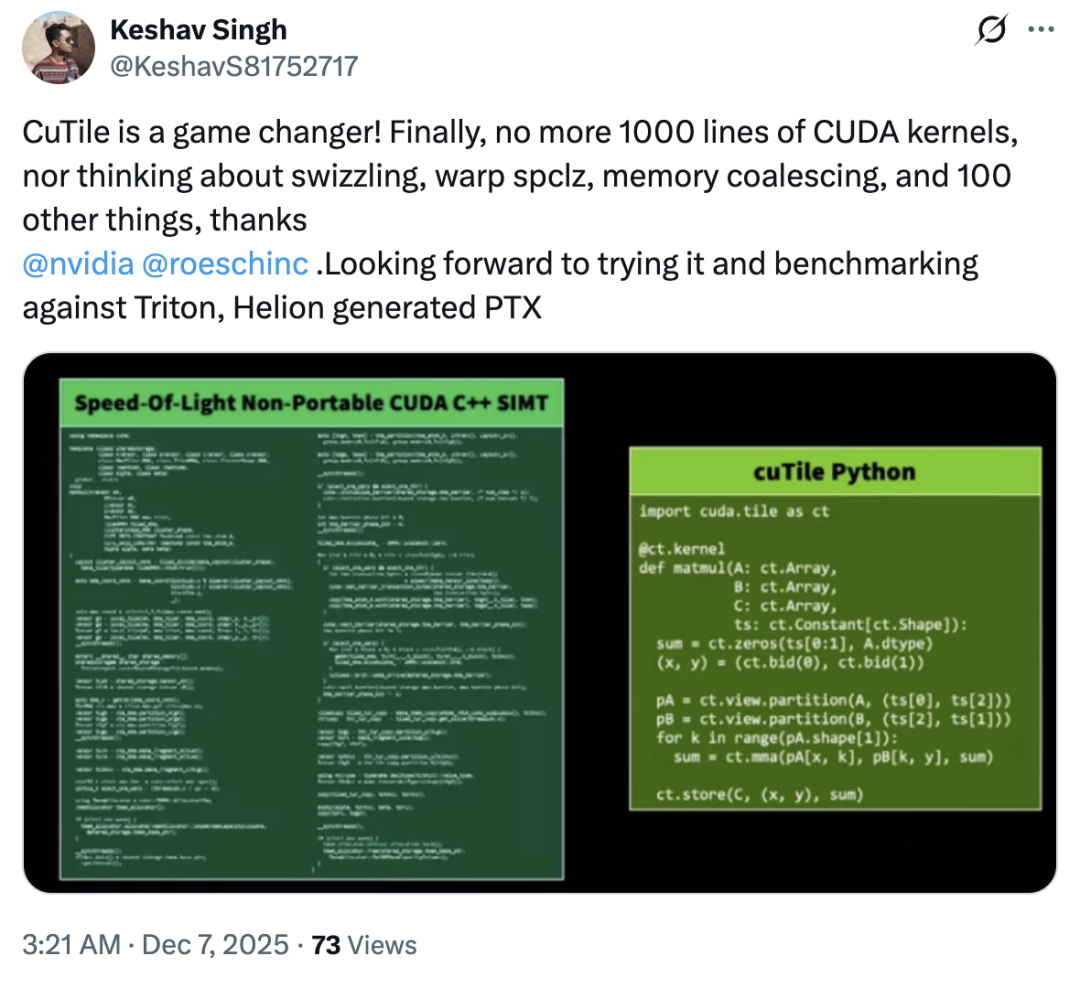
尽管尚处早期,社区已开始积极探索cuTile的实践路径。例如,有开发者在Reddit上发起了开源项目,尝试将部分现有的CUDA Kernel自动转换为基于Tile的形式,为潜在的大规模迁移提供工具支持。
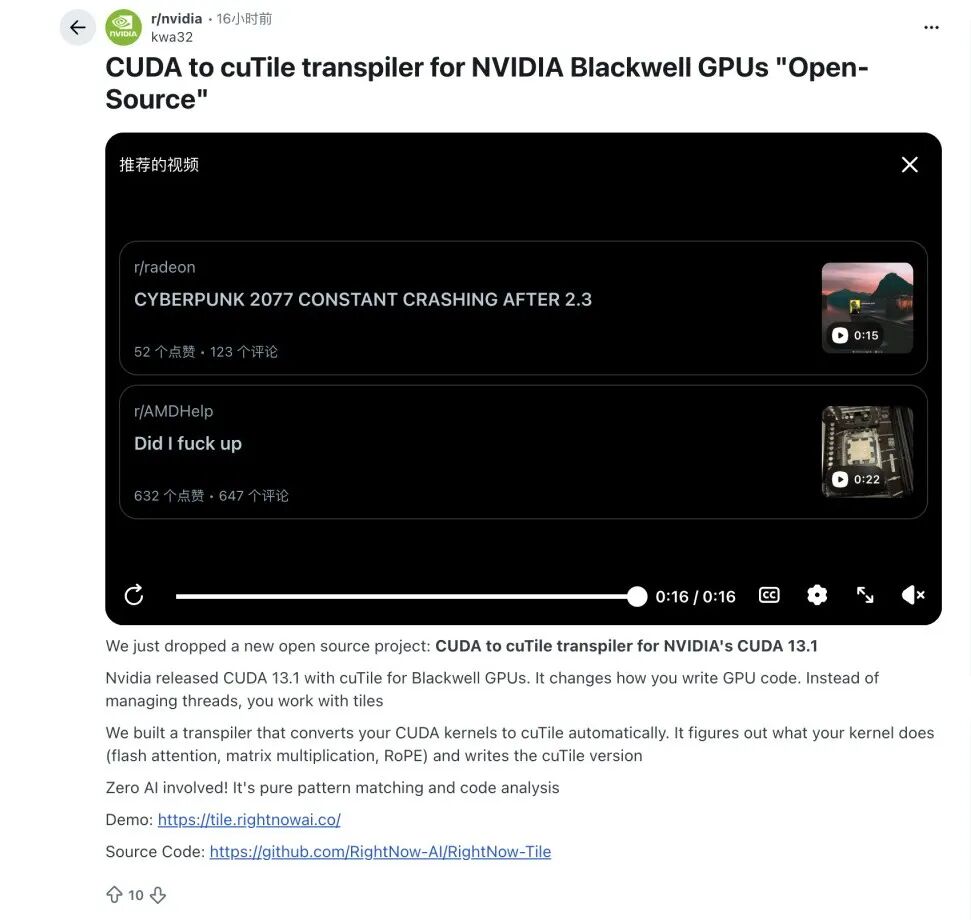
未来展望:生态、迁移与性能的终极考验
cuTile的最终成功,仍面临几大关键考验。首先,从CUDA到cuTile的迁移工具链需要足够成熟,以降低现有项目的转换成本。其次,需要形成活跃的开发者社区,围绕cuTile构建起丰富的示例、教程和最佳实践。最后,也是最根本的,cuTile必须在其宣称的复杂算子场景下,持续提供显著且不可替代的性能优势。
cuTile能否成为GPU编程的主流新范式,抑或只是CUDA漫长发展史中的一次实验,答案将取决于未来几年其在真实工作负载中的表现以及生态的成熟速度。 |  发表于 2025-12-17 23:17:55
|
查看: 294|
回复: 0
发表于 2025-12-17 23:17:55
|
查看: 294|
回复: 0
