OpenAI已推出新版ChatGPT Images,其核心是全新的旗舰图像模型GPT Image 1.5。该模型在图像编辑能力上显著提升,主打“按意图精准修改”——在修改图片时,它能严格遵循用户指令,只改动要求的部分,同时努力保持原始图像的光照、构图、人物外观(特别是脸部相似度)在多轮编辑中的一致性。这使得修图、虚拟试穿/试发型、风格迁移等操作的结果更加可信,更贴近原图。

该模型的指令遵循能力更加稳定,不仅提升了精细化编辑效果,也能支持更复杂的原创构图与元素关系控制。其文字渲染能力也得到加强,能够处理更密集、更小的文本并保持排版可用性。整体输出在实用维度上更显自然,例如在处理复杂人群、小脸等场景时表现更佳,图像“直接可用性”更高。
产品形态上,ChatGPT内新增了专门的Images创作空间(侧边栏入口),提供了预设滤镜与灵感模板以加速尝试与迭代,并支持一次性上传人物相貌以便后续复用。用户还可以在一张图片的生成过程中,随时发起新的生成任务,减少等待时间。
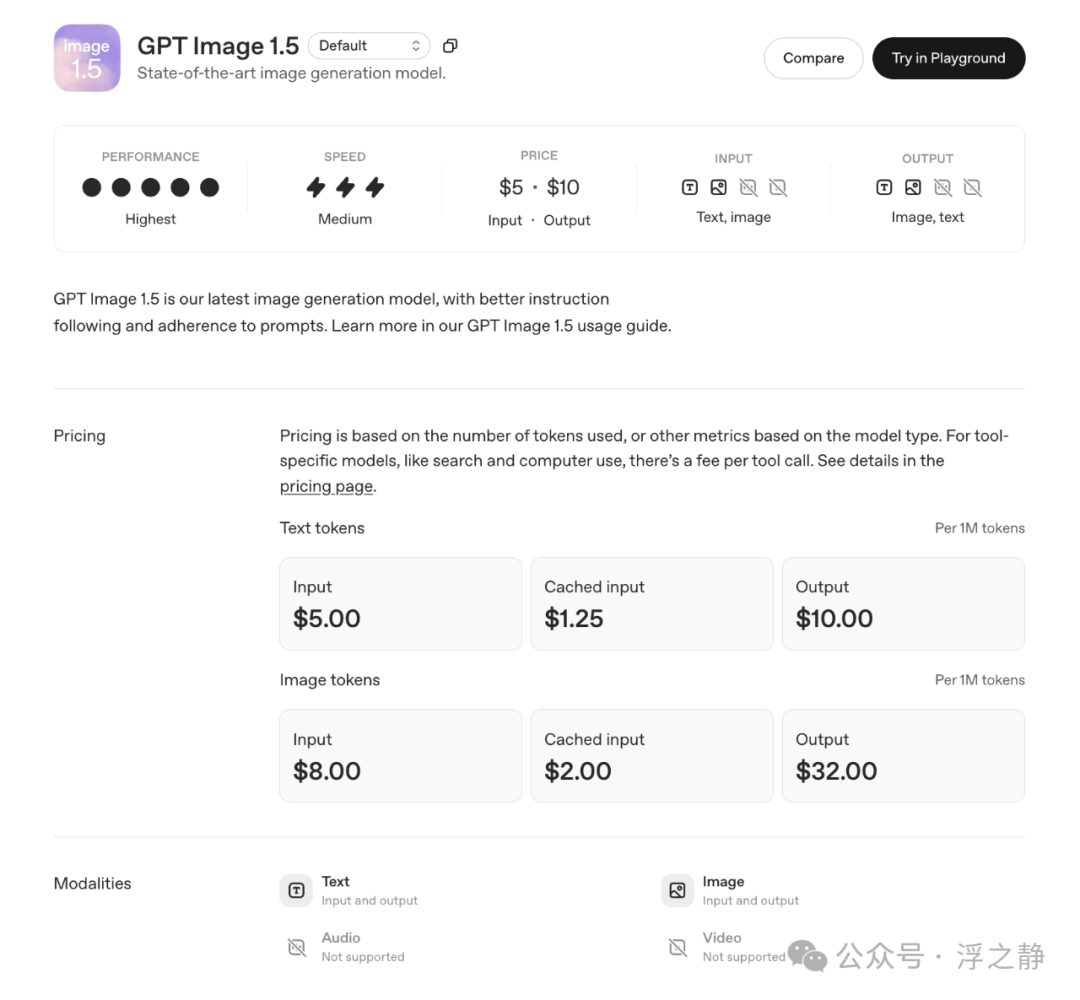
可用性方面:新模型已对所有ChatGPT用户逐步开放;其API以GPT-Image-1.5的名义提供。ChatGPT的新Images体验正对大多数用户开放,Business/Enterprise版本稍晚。API侧特别强调其更适合品牌、电商等需要跨编辑保持Logo与关键视觉一致性的工作流。相较于GPT Image 1,其图像输入/输出成本降低了20%。官方也坦诚表示,模型虽有明显进步,但仍存不足,后续将持续改进。
第三方测评概览
Artificial Analysis
在Artificial Analysis Image Arena的测评中,GPT Image 1.5在文生图与图像编辑两项任务上均位列第一,超越了Nano Banana Pro。作为OpenAI最新的旗舰人工智能图像生成模型,它在画质与提示词还原度上较前代均有提升。其API采用按token计费模式,价格随分辨率与质量档位变化:以1MP(百万像素)图像为例,高质量模式下约$133/千张,低质量模式下约$9/千张。

GenAI
GenAI的图像编辑测评榜专注于对比各顶尖模型在“纯文本指令驱动的图像修改”上的表现。测评规则严格:不允许多轮补救提示,必须在单次尝试中完成目标;且仅允许基于文本指令进行编辑,禁止使用img2img或手动遮罩进行局部重绘。为保证公平,会对每个模型的提示词进行必要的微调。
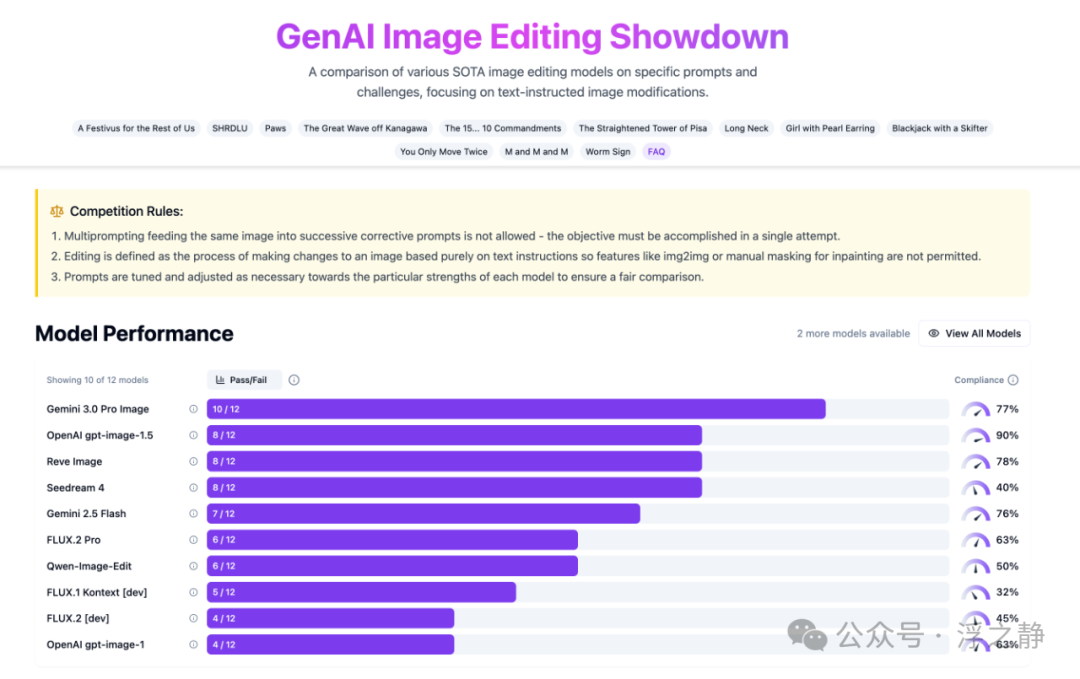
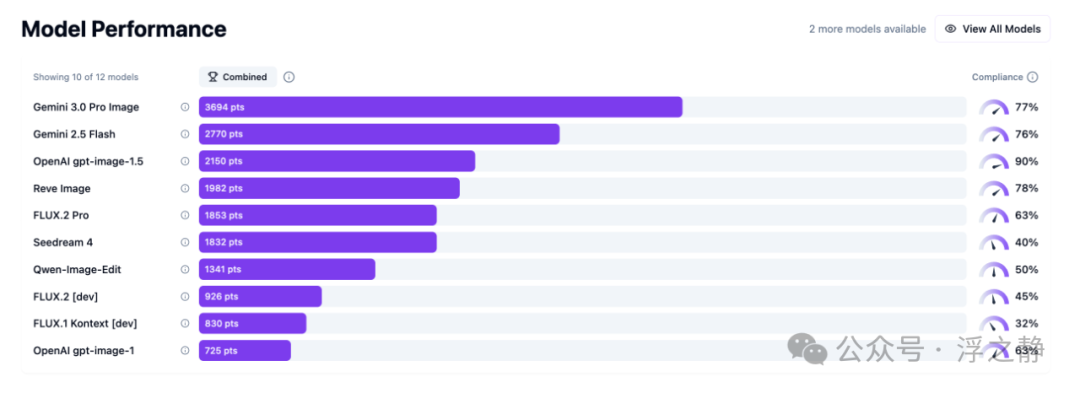
关键指标说明:
- 通过/失败(Pass/Fail):粗略衡量模型完成任务的能力。
- 综合(Combined):加权得分,综合考虑通过率、合规性与质量评分。
- 指令遵循度(Compliance):衡量模型“可控性”,即按提示词行事的准确度。该指标仅对通过测试的样本计算。
从测评结果看,在综合能力上Gemini 3.0 Pro Image(Nano Banana Pro)更为强劲,但GPT Image 1.5的指令遵循度表现突出,直奔90%,比Gemini 3高出13个百分点。
Hacker News
下图截取自Hacker News上关于此话题的相关讨论。

小结
综合第三方测评,可以得出结论:GPT-Image-1.5在指令遵循与提示词还原度上均有巨大提升。以下是Artificial Analysis提供的几组对比测试图,可供直观感受。
文生图 Prompt: A curious cat peeking out from a pile of autumn leaves.

文生图 Prompt: A close-up, photorealistic view of a hummingbird feeding on a bright red hibiscus, shimmering emerald feathers catching the morning light, wings frozen in mid-beat.

文生图 Prompt: A retro-inspired advertisement for a local diner, featuring a chrome milkshake holder and a cheeseburger on a red-checkered tablecloth under neon lighting, with the text 'Classic Comfort, Every Time!'

图生图/编辑 Prompt: Change the car's color to orange

图生图/编辑 Prompt: Insert a family of yellow ducks crossing the railroad

官方Prompt使用指南解析
为了帮助开发者更好地使用Image 1.5模型,OpenAI官方提供了详细的Prompt指南。虽然指南主要面向API使用,但其核心技巧具有通用性,以下为整理要点。
1. 通用写作骨架
建议按固定顺序组织提示词:用途/成品形态 → 场景/背景 → 主体 → 关键细节 → 构图/布局 → 约束(改什么/不改什么)。对于复杂需求,使用分段或标签进行结构化描述,避免将所有信息塞进一段冗长的文字。
2. 提升结果可控性的关键技巧
- 描述具体化:明确材质、形状、纹理、媒介(如照片、水彩、3D渲染)。对于写实风格,建议用镜头语言(如景别、光线、机位)来控制,而非简单使用“8K”、“超清”等泛化词汇。
- 明确构图与版式:指定近景/远景、俯拍/平视、留白、元素位置(如“Logo置于右上角”)。
- 清晰界定修改范围:编辑图片时,使用“只修改X,其余部分保持不变”的句式,并在每次迭代时重复需保留的要素清单,以防止风格漂移。
- 处理图中文字:将必须出现的文案放在引号内(或全大写),并约束字体风格、大小、颜色和位置。对于难拼写的单词,可考虑逐字母拼写。
- 处理多图输入:按“Image 1/2/3:内容描述”逐一标注输入图像,并清晰说明“将哪张图的什么元素放置到何处,或应用哪张图的风格”。
- 分步迭代:先生成一个干净的基础版本,再通过“小改动”提示词进行迭代优化(例如,仅调整光线、仅删除某个元素)。
3. API参数与效果取舍
quality参数:追求细节、密集文字或复杂版式时使用high;追求低延迟、高吞吐量场景可先从low模式试起。input_fidelity参数(编辑时):当编辑涉及保持人物相貌,或需要进行较大幅度的场景修改/合成时,建议倾向使用high。n参数:若需要一次性获得多个备选方案,可直接通过此参数让模型生成多张变体。
4. 高频任务提示词要点
- 信息图/图表:明确目标受众、信息结构与视觉层级。文字密集时更建议使用高质量模式。
- 图片内翻译/本地化:强调“除文字外全部元素保持不变”,尽力保持原有的排版层级、间距和字重,并要求翻译逐字准确、不随意增删词汇。
- 写实自然照片:将其描述为“现场抓拍”,强调真实的纹理与合理瑕疵,避免“棚拍感、过度精修、电影调色”等表述。
- UI界面Mockup:将产品当作“已上线的真实应用”来描述,强调布局、信息层级、间距、使用真实组件,少用概念艺术词汇。
- Logo/品牌图形:先定义品牌气质与使用场景,再强调“简洁、可缩放、负空间平衡、具有矢量感、无侵权风险”。
5. 编辑类工作流的硬约束写法
- 风格迁移:先锁定需要保留的原图风格线索(如色调、笔触、颗粒感),再描述要替换的新内容,并附加“背景/构图/禁止新增元素”等硬性约束。
- 虚拟试穿:将“人物”特征锁死(脸、体型、姿态、发型、表情),只允许修改服装;要求生成真实的布料褶皱、遮挡关系及与原始光影的一致,禁止改动背景、镜头或添加文字/Logo。
- 草图转渲染:将Prompt当作“产品规格书”:先保留原草图的布局、比例与透视关系,再补充材料、光线与环境细节;添加“不要新增元素/文字”的约束。
- 抠图/商品图:要求输出带透明通道的RGBA PNG格式、边缘干净无毛边;产品标签文字必须清晰且内容不变;可选择性添加轻微的接触阴影;强调“不改变产品风格,仅做轻度抛光处理”。
- 含真实文字的广告图:将文案放入引号并要求“逐字渲染、不可多出字符”,再约束字体与位置;若仍不够精确,可通过小幅调整排版或措辞进行迭代。
- 光照/天气替换:只改变环境条件(光线方向、阴影、雾气/雪花、地面湿度等),相机机位、场景几何结构与物体位置必须保持原样。
- 多图合成:明确“从哪张图搬取什么元素 → 放置到目标图的哪个位置 → 哪些部分保持不变”,并要求匹配目标场景的光照、透视、尺度和阴影。
请注意:经测试,其“抠图”功能并非真正移除背景生成透明图层,而是替换为网格背景。以下是测试示例:
测试Prompt:
Extract the product from the input image. Output: transparent background (RGBA PNG), crisp silhouette, no halos/fringing. Preserve product geometry and label legibility exactly. Optional: subtle, realistic contact shadow in the alpha (no hard cut line). Do not restyle the product; only remove background and lightly polish.

输出结果:

Prompt模板总结
可将上述指南总结为以下结构化模板:
Goal/Output:
- 你要的成品类型与用途(海报 / 电商主图 / UI mock / 信息图 / 写实照片 / 风格插画)
Scene:
- 背景/环境 + 主体 + 动作/关系
Style:
- 媒介与风格(照片/水彩/3D)+ 关键质感(材质、纹理、瑕疵/颗粒)
Composition/Layout:
- 景别/机位/光线 + 元素摆位(留白、居中、角落放字/标识)
Text (verbatim, if any):
- "必须出现的文案"
- 字体风格/大小/颜色/位置/只出现一次
Edit constraints (for edits):
- Change ONLY: X
- Preserve exactly: A, B, C(每次迭代都重复这行)
- Negative: no watermark / no extra text / no logos / no new objects
实际测试体验
笔者基于官方推荐的部分Prompt进行了实测,对比了Gemini 3.0 Pro Image与GPT Image 1.5,发现两者各有特色。
测试一:悬浮3D头像风格化
输入Prompt与原始图片:

(Prompt内容较长,描述了一个光泽塑料质感、带有“mean girl”态度的3D悬浮头像,此处略)
测试结果:
要求模型将原图与生成图并列展示。GPT Image 1.5似乎更好地捕捉了“傲娇”神态,而Gemini意外地修改了原图部分。


后续迭代:
在以上风格化Prompt的基础上,追加指令坐在 🐝 上,手里拿着 🌈。模型能够继承上下文设定的风格,并在此基础上进行修改。

测试二:双人图像融合
输入Prompt与两张原始图片:
融合成一张图,眉目传情,卿卿我我


首次生成结果:
若不加以特别约束,GPT Image 1.5可能生成画风奇特的融合结果。

迭代修正:
发送指令男生是一个人进行修正后,画面正常了许多(尽管手部细节仍有些不合理)。

Gemini对比测试:
使用相同的初始Prompt,Gemini 3.0 Pro Image一次就生成了较为合理的融合图。

继续输入换成图中的白发男子,Gemini也能稳定执行,且生成的人物风格更接近原图。

参考资料
[1] ChatGPT Images 公告: https://openai.com/index/new-chatgpt-images-is-here
[2] Artificial Analysis Image Arena: https://artificialanalysis.ai/image/leaderboard/text-to-image
[3] GenAI 图像编辑测评榜: https://genai-showdown.specr.net/image-editing
[4] Hacker News 相关讨论: https://news.ycombinator.com/item?id=46291941
[5] GPT-image-1.5 Prompting Guide (OpenAI Cookbook): https://cookbook.openai.com/examples/multimodal/image-gen-1.5-prompting_guide
 发表于 2025-12-18 01:31:49
|
查看: 303|
回复: 0
发表于 2025-12-18 01:31:49
|
查看: 303|
回复: 0
