
尽管 QEMU 在 KVM 和 VirtIO 的辅助下,能将虚拟化性能损耗控制在 10% 左右,但这对于追求极致效率与成本的头部云厂商而言,仍然是不可接受的“天花板”。这促使了 AWS、阿里云、华为云等厂商纷纷投入自研虚拟化架构的研发。本文将深入剖析 QEMU+KVM+VirtIO 方案的固有瓶颈,并解读主流云厂商如何通过软硬协同设计,最终将虚拟化损耗降至 1% 以下。
一、QEMU+KVM+VirtIO 的性能瓶颈分析
10% 的性能损耗根植于其软件中心化架构,主要存在三大瓶颈:
- I/O路径的软件栈瓶颈:VirtIO的前后端模型仍需虚拟机退出到宿主机内核,由 QEMU 进程处理,带来了上下文切换、中断处理和内存拷贝三重开销。在高性能网络和NVMe存储场景下,这条路径成为主要性能瓶颈。
- 安全与管理的性能代价:庞大的 QEMU 设备模拟代码构成了巨大的安全攻击面。同时,所有安全组策略、流量监控都需CPU进行软件过滤,管理操作(如快照、监控)也与业务虚拟机争抢计算资源。
- 资源争用与性能抖动:宿主机的 CPU 同时扮演“运动员”(运行用户计算)和“裁判员”(处理所有虚拟机的I/O代理与管理)的角色。在多租户高负载环境下,难以保证每个虚拟机性能的稳定与可预测。
对于拥有百万级服务器规模的云厂商,10% 的损耗意味着数以十万计的 CPU 核心算力被永久闲置,年成本损失可达十亿美元量级。这已从一个纯粹的技术问题,升级为关乎商业竞争力的核心生存问题。
二、破局之道:软硬协同的自研虚拟化架构
面对上述瓶颈,主流云厂商不约而同地选择了同一条路径:用专用硬件取代 QEMU 的软件模拟,实现数据面完全绕过(Bypass)宿主机软件栈。它们的共同设计哲学是:“能用硬件解决的,绝不交给软件。”
| 瓶颈 |
开源方案 (软件模拟) |
自研架构 (软硬协同) |
解决之道 |
| I/O性能瓶颈 |
长软件路径,高延迟抖动。 |
硬件卸载与直通 |
将网络、存储协议栈固化到专用芯片,并通过SR-IOV等技术直通给虚拟机,实现内核旁路。 |
| 安全与管理开销 |
软件实现,与业务争抢CPU。 |
控制面与数据面分离 |
将管理、监控、安全策略等控制面功能外移至独立的专用板卡或管理VM,数据面由硬件强制执行。 |
| 资源争用与隔离 |
所有租户共享宿主机软件栈。 |
硬件资源切分与隔离 |
通过定制芯片实现物理资源的硬切分与硬隔离,从硬件层面根除“吵闹的邻居”问题。 |
以下是三大厂商的代表性架构:
| 厂商 |
架构名称 |
核心组件 |
目标 |
| AWS |
Nitro System |
Nitro Card(FPGA/ASIC)+ Micro Hypervisor |
将网络、存储、安全、管理全部卸载 |
| 阿里云 |
神龙架构(MOC) |
自研 MOC 芯片 + 飞天操作系统 |
实现“零虚拟化开销”的弹性计算 |
| 华为云 |
QingTian 架构 |
虚拟化加速芯片 + 轻量 VMM |
构建高安全、高密度的云底座 |
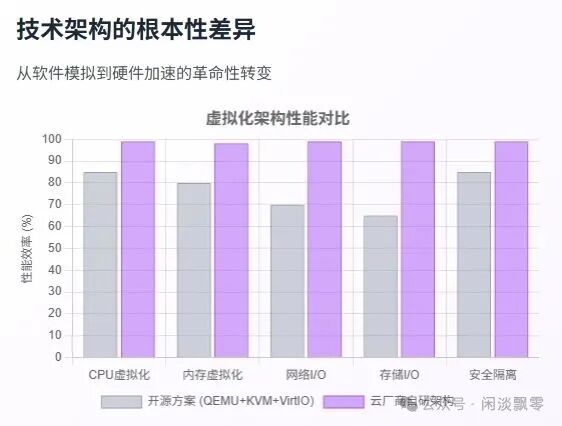
三、专用 I/O 芯片如何实现“几乎零开销”?
专用 I/O 芯片是实现 <1% 虚拟化损耗的核心。以网络 I/O 为例,对比两种路径:
❌ 传统路径(QEMU 参与):
Guest App → VirtIO Driver → KVM → QEMU(读 Descriptor)→ Host Kernel → 物理网卡
- 至少 3 次上下文切换;
- 2 次内存拷贝;
- 延迟 >20μs,CPU 占用高。
✅ 自研芯片路径(QEMU 被 bypass):
Guest App → VirtIO Driver → I/O 芯片(DMA 直读 Guest 内存)→ 物理端口
- 宿主机 CPU 零参与数据面;
- Zero-Copy + 一次 DMA;
- 延迟 <5μs,CPU 占用 <1%。
3.1 硬件级I/O卸载,剥离CPU负担
专用IO芯片集成独立的ASIC/FPGA计算单元、内存与协议引擎,直接承接原本由CPU执行的I/O核心任务:
- 网络卸载:硬件实现TCP/UDP/IP协议栈、校验和计算、流量过滤。
- 存储卸载:硬件解析NVMe/SCSI指令、管理缓存、执行数据加密/解密。
- 安全卸载:硬件处理虚拟机内存隔离、数据校验、访问控制。
以AWS Nitro为例,网络处理的CPU占用率可从25%降至5%以下,这得益于其深度的性能优化理念。
3.2 零拷贝与DMA技术
传统I/O的多次内存拷贝是主要性能损耗点,专用IO芯片通过DMA(直接内存访问)技术实现数据的“直接传输”:
- 芯片内置DMA控制器,绕过CPU直接访问虚拟机内存。
- 将数据从物理设备直接传输至虚拟机内存,拷贝次数从传统方案的4次降至0次。
3.3 SR-IOV硬件直通
通过SR-IOV(单根I/O虚拟化)技术,将物理I/O设备“切片”为多个虚拟功能(VF),每个VF通过VFIO技术直接分配给虚拟机:
- 虚拟机通过原生驱动直接访问VF,Hypervisor完全退出数据路径。
- IOMMU提供硬件级内存隔离,保障安全。
华为云QingTian架构通过SR-IOV将单块物理网卡虚拟为1024个VF,网络PPS(包转发率)提升至开源方案的10倍。
3.4 实战案例:阿里云神龙架构存储I/O流程
- 虚拟机通过原生NVMe驱动发送请求,直达MOC卡。
- MOC卡硬件解析指令,访问ESSD云盘。
- 数据通过DMA直接写入虚拟机内存,同时硬件完成加密校验。
- MOC卡返回完成信号,CPU全程零参与。
该流程使存储IOPS提升至300万,延迟降至40μs。
四、CPU与内存虚拟化的深度优化
I/O被卸载后,CPU和内存虚拟化仍基于 KVM,但进行了极致优化,这也是云原生基础设施高效能的关键。
4.1 内核裁剪
- 移除非虚拟化相关的内核模块、驱动和文件系统。
- 仅保留CPU/内存虚拟化核心功能。
- 效果:内核体积和启动时间大幅减少,内存占用降低。
4.2 调度优化
- CPU亲和性调度:将虚拟机与物理核心绑定,减少上下文切换。
- 预调度机制:通过算法预测资源需求,提前分配。
- 中断合并与均衡:批量处理中断,分散负载。
4.3 内存优化
- 大页内存(HugePage):默认启用,减少TLB失效,提升访问效率。
- EPT/NPT优化:增强硬件辅助的内存地址转换,降低延迟。
五、轻量级Hypervisor:虚拟化层的终极瘦身
云厂商自研架构的核心是将Hypervisor从“全能管理者”转变为“极简调度器”。
5.1 三大优化方向
- 控制面与数据面分离:数据面由硬件完成,控制面运行在独立模块。
- 功能最小化裁剪:仅保留CPU调度、内存管理、硬件接口三大核心功能。
- 架构扁平化:摒弃“KVM+QEMU”双层模型,减少进程切换与跨层转发。
5.2 厂商实现案例
- AWS Nitro Hypervisor:基于KVM深度裁剪,移除QEMU,所有I/O交予Nitro卡,损耗<0.5%。
- 阿里云Dragonfly Hypervisor:自研超薄虚拟化层,代码量仅为传统方案的15%,实现“零资源预留”。
- 华为云Zero Hypervisor:无独立内核,通过Split-Hypervisor技术将所有非核心功能卸载至加速卡。
六、总结:<1%损耗是全栈协同的革命
云厂商实现近零损耗,并非单一技术的突破,而是 “硬件卸载 + 软件精简 + 架构重构” 的全栈协同成果:
- 专用IO芯片解决了I/O性能瓶颈,实现“零CPU参与”。
- 基于KVM的深度优化消除了软件冗余,提升了调度与内存效率。
- 轻量级Hypervisor剥离了非核心功能,实现“零资源预留”。
这种协同效应使得虚拟化损耗从“软件主导的10%”降至“硬件指令延迟主导的<1%”,完成了从“可接受损耗”到“近零损耗”的代际跨越,为云计算提供了更强大、更经济的算力底座。 |  发表于 2025-12-18 06:56:45
|
查看: 291|
回复: 0
发表于 2025-12-18 06:56:45
|
查看: 291|
回复: 0
