国产数据库为何不直接复制 MySQL 的底层架构?这源于对闭源生态的深刻教训,以及对数据价值应被广泛利用的坚定信念。
一方面,底层技术被黑盒内核与私有协议锁死,导致数据库替换或向多云迁移受制于人;另一方面,数据入库后往往仅被少数技术或报表人员掌握,业务方使用数据需要漫长等待。因此,不照搬MySQL内核,并非为了彰显技术优越性,而是旨在实现双重目标:自主掌控底层架构,并向更广泛的群体开放数据能力。 唯有实现数据库可控,且数据能被更多人便捷分析,国产数据库的真正价值才能得以释放。

1. 兼容的初衷:是为了降低门槛,而非制造新枷锁
近年来,国产数据库厂商有一个普遍共识:对外宣称“兼容 MySQL 协议”。
这一策略市场接受度高,因为它意味着:
- DBA无需重新学习一套全新的查询“方言”;
- 大部分上层中间件、驱动及报表工具可无缝对接;
- 从现有系统迁移的显性成本大幅降低。
于是,一个自然的联想产生了:既然协议要兼容,何不一并将MySQL的底层架构也“借鉴”过来,岂不省时省力?
然而,风险恰恰在于此。一旦底层架构完全仿照MySQL,很可能在不知不觉中,将自己打造成下一个 “闭源黑盒 + 强绑定生态” 的翻版。届时,企业可能只是将“被国外厂商卡脖子”的困境,置换为“被另一家国产厂商卡脖子”。

2. 历史包袱:MySQL的设计源于过去的互联网场景
MySQL的成功毋庸置疑,但其底层设计本质上是为 “过去二十年的典型互联网场景” 服务的,例如:
- 架构以单机及主从复制为主,分布式与云原生特性是后期逐步叠加的;
- 更侧重于读多写少、OLTP事务处理及相对轻量的互联网业务;
- 为兼容众多历史版本、插件及生态伙伴,其核心设计难以进行颠覆性重构。
反观当下国产数据库需要应对的场景:
- 金融、政务、制造等行业对强一致性、高可靠性与审计合规的严苛要求;
- 基于Kubernetes、云原生及多中心多活的现代化部署模式;
- 需要适配国产CPU、操作系统及存储的完整技术栈。
若想解决2025年中国企业的数据挑战,却照搬一套源于2000年互联网世界的底层工程妥协方案,这无异于一种“捷径幻觉”。 看似站在巨人肩上,实则承接了巨人的历史包袱与设计局限。模仿得越深,未来为兼容性和历史设计缺陷所付出的代价就越高,最终可能被旧有架构牢牢束缚,丧失真正的创新能力。
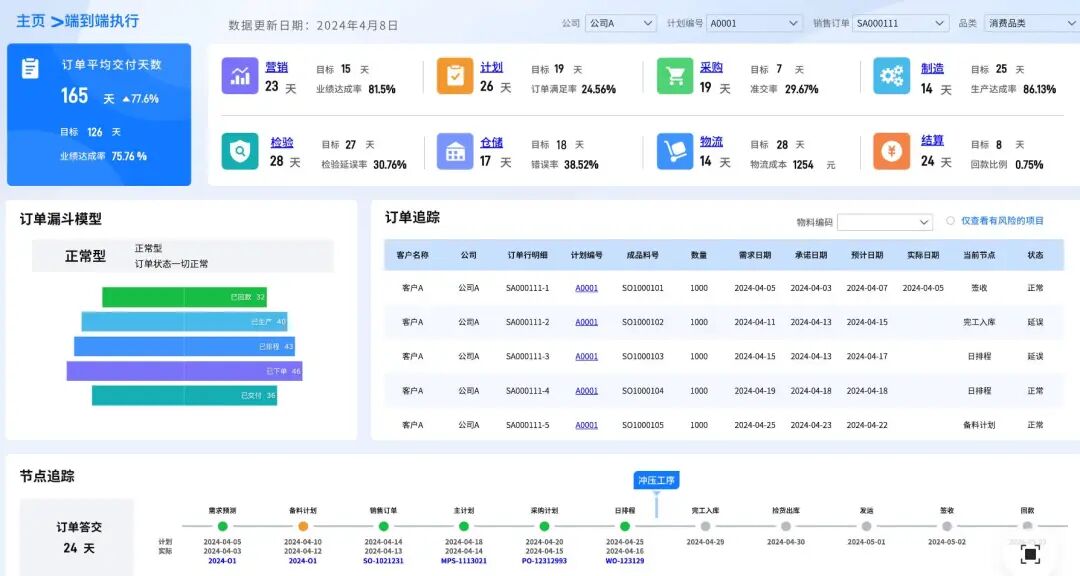
3. 更深层的痛点:不仅是技术闭源,更是数据使用权的封闭
人们对“闭源之痛”的认知,往往停留在商业数据库厂商的年费上涨、授权模式复杂以及迁移改造困难。然而,从企业完整数据链路的视角看,真正的“智商税”不仅来自底层数据库,更源于数据使用权的过度集中。
典型现象是:
- 数据已迁移至国产数据库,但业务决策仍严重依赖Excel表格;
- 尽管部署了BI工具,但其使用高度中心化,仅限数据部门的少数人员;
- 产出报表精美,但能够理解并敢于依据其做出决策的业务人员凤毛麟角。
这导致了一种微妙的困境:“数据库国产化了,但依赖直觉拍板的决策方式并未改变。” 这说明,仅仅解决“库可控”的问题是不够的,“谁能用数据驱动业务”这一根本性问题依然悬而未决。
4. 学习的精髓:应是“接口生态”,而非“内核实现”
问题的关键不在于“能否学习”,而在于“学习什么”。
4.1 接口层:兼容是为了生态平滑过渡
MySQL的核心价值之一,在于其塑造了一套事实标准的接口与生态:
- 其通信协议、基础语法得到了几乎所有编程语言和框架的支持;
- 大量工具、BI平台与数据中台都对其原生友好。
国产数据库学习并兼容其协议与语法,是明智之举,能显著降低迁移门槛和生态切换成本。但需明确:兼容应是“为客户架桥”,而非“为自己筑墙”。 将兼容作为优势可以,但若将其变为创新的枷锁,则重蹈了封闭生态的覆辙。
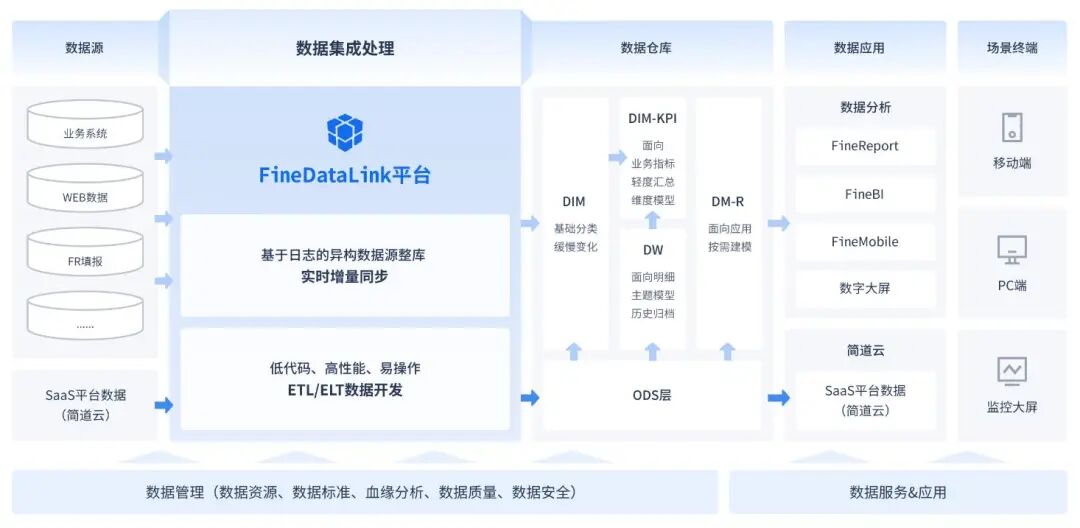
4.2 内核层:必须自主攻克中国场景下的工程难题
国产数据库必须结合本土实际业务场景,从零开始解决核心工程问题:
- 如何设计兼顾一致性、性能与可用性的分布式事务机制;
- 在国产芯片与操作系统上如何进行IO、调度与并发控制的深度调优;
- 满足行业监管、审计与合规要求下的日志、加密与安全设计方案。
这些内核层面的挑战,无法通过“抄底”规避。若不自主攻克,最终将让客户承受技术不匹配的代价。
5. 价值闭环:从“库可控”到“数据民主化”
当成功将数据库替换为国产产品后,下一步的关键是什么?如果数据的使用权依然被少数部门垄断,那么企业只不过是用“组织结构的卡脖子”替代了“技术上的卡脖子”。
因此,一个显著趋势是:在国产数据库之上,企业会引入一层自助式BI平台。这类工具的目标是让“数据查看与分析”从技术特权转变为业务人员的日常技能。
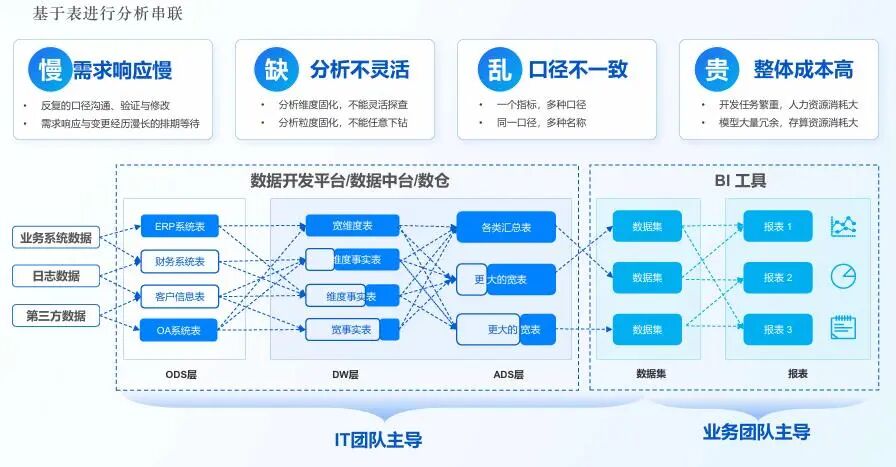
5.1 打通数据供给链路
再优秀的国产数据库,如果数据难以被便捷地提取和消费,也只是一个“高性能存储设备”。自助BI平台的首要作用是:
- 直连各类主流及国产数据库、数据仓库;
- 整合来自业务系统、表格文件、API等多源数据;
- 在语义层统一定义业务指标与计算口径(如GMV、客单价),实现“一次定义,全公司复用”。
这使得业务人员面对的不再是散乱的数据表,而是结构清晰的数据模型与预定义好的业务指标体系。数据库专注于存储、事务与性能;BI则负责“将数据价值呈现于人前”。
5.2 推动报表制作自助化
传统模式是“业务提需求→数据团队排期开发”,一个简单的维度调整可能耗时数日。自助BI的理念截然不同:它假设“业务人员最了解自身问题,应赋能他们直接探索数据”。
在数据模型与权限管控完备的基础上,业务人员可通过拖拽字段、选择维度和指标的方式,自主创建图表与仪表盘。IT/数据团队则聚焦于更核心的工作:对接数据源、构建公共数据模型、管控权限与资源。这便将大量重复、临时的报表开发工作交还给了业务方。
5.3 实现协同与口径统一
当企业拥有统一的BI平台后,协作方式将悄然优化:
- 指标唯一化:关键指标被固化在统一的模型中,避免了各部门数据“各算各的”的混乱。
- 讨论可视化:团队基于同一份实时仪表盘进行“看图说话”的讨论,临时分析需求可通过自助操作快速满足,效率远胜于邮件或工单流转。
- 释放底层潜力:国产数据库可以更专注地提升其分布式处理、实时计算等底层能力,而BI平台则能将这些能力转化为业务侧可感知的洞察速度与深度。
至此,那些曾“只躺在少数人电脑里的数据”,才能真正转化为“驱动多数人决策的生产力”。
6. 结语:不照搬内核,是为了掌握全面的主动权
回顾开篇的问题,答案已逐渐清晰。国产数据库不复制MySQL内核,不仅是为了避免再次被封闭的技术体系锁死,更是为了打破数据使用权的垄断。
“国产数据库 + 自助式BI平台”构成了一条从“技术自主”走向“决策科学”的路径。
- 前者保障了数据存得住、存得稳、存得安全;
- 后者确保了数据看得见、用得着、能指导行动。
这一选择并非追求技术上的“纯粹”,而是为了最终能够宣告:我们既不再受制于他人的闭源技术,也不会被自身低效的数据应用方式所拖累。数据库的掌控权在我们手中,利用数据进行洞察与决策的权利,同样在我们自己人手中。
 发表于 2025-12-18 06:54:40
|
查看: 248|
回复: 0
发表于 2025-12-18 06:54:40
|
查看: 248|
回复: 0
