想象一下,一座城市如果没有红绿灯和交通规则,所有车辆在路口肆意穿行,结果必然是全面瘫痪。网络世界亦是如此,若缺乏流量控制机制,数据包将无序争抢带宽,导致网络拥塞、延迟飙升、丢包严重。
Linux流量控制(Traffic Control, 简称 TC)便是网络世界的“智能交通管理系统”。它工作在Linux内核网络栈的数据链路层,负责管理和整形网络接口上的数据流。作为操作系统基础设施的重要组成部分,Linux提供了一套业界公认功能强大且高度灵活的流量控制框架,被广泛应用于路由器、防火墙、云计算平台及各类嵌入式系统中。
一、Linux流量控制的整体架构
1.1 核心设计思想
Linux流量控制框架的设计遵循几个核心原则:
- 模块化设计:每个功能组件(如队列、分类器)独立,支持灵活组合。
- 层次化管理:支持多级队列和分类,实现精细化的流量管理。
- 策略与机制分离:流量控制算法(机制)与流量分类规则(策略)相互解耦。
- 纯软件实现:不依赖特定硬件,具备高度的可移植性。
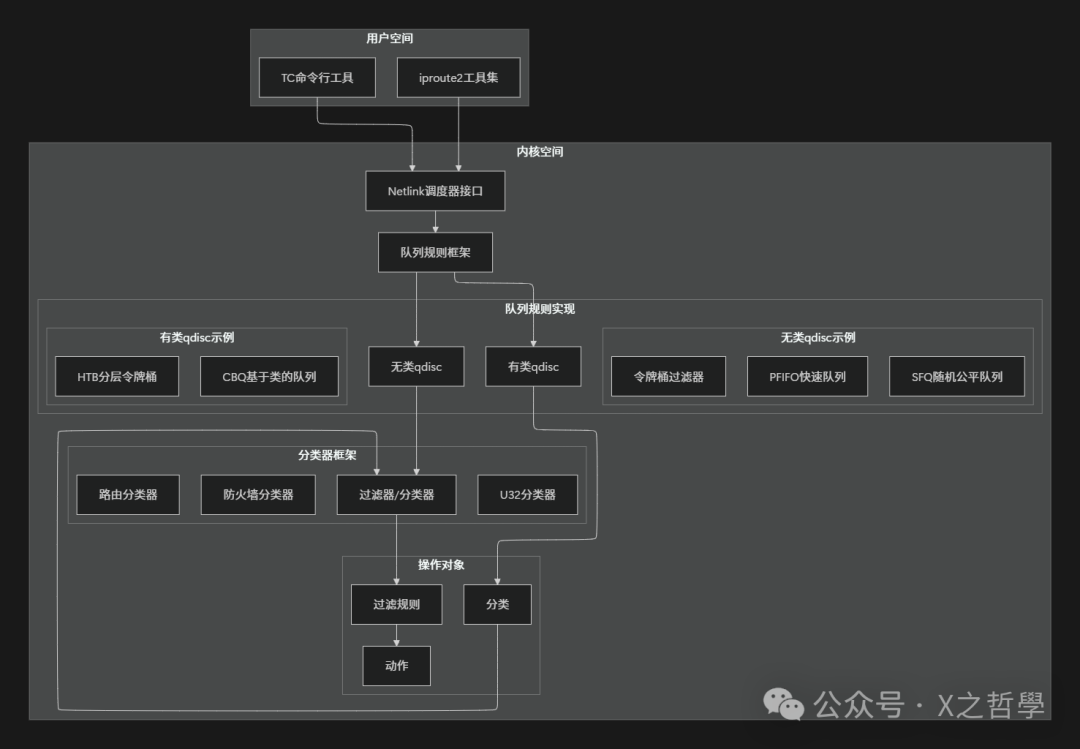
1.2 数据包处理流程
当数据包通过Linux网络接口时,流量控制子系统会按照既定流程进行处理:
二、核心概念深度解析
2.1 队列规则(Queueing Discipline, qdisc)
队列规则是流量控制的基石。你可以将其理解为一个邮局的分拣中心:数据包如同待处理的信件,而qdisc则决定了这些信件如何被暂存、排序以及最终投递出去。
2.1.1 qdisc的基本原理
每个网络接口都关联着一个或多个qdisc。当内核需要发送数据包时,并非直接交给网卡驱动,而是先送入qdisc队列中排队。qdisc根据其内置算法决定:
- 何时发送数据包
- 发送哪一个数据包
- 是否丢弃某些数据包
2.1.2 qdisc的类型对比
| 类型 |
特点 |
适用场景 |
示例 |
| 无类qdisc |
结构简单,不对流量进行分类 |
简单限速、基础公平队列 |
pfifo_fast, TBF, SFQ |
| 有类qdisc |
结构复杂,支持创建子类和过滤器 |
精细化的流量管理与整形 |
HTB, CBQ, PRIO |
| 入口qdisc |
处理接收(ingress)方向的流量 |
入口限速、过滤 |
ingress |
| 出口qdisc |
处理发送(egress)方向的流量 |
出口流量整形、调度 |
默认类型 |
2.2 分类(Class)
分类是有类qdisc的核心组件。延续邮局的比喻,如果qdisc是邮局,那么class就是邮局内不同的处理部门,如平信部、快递部、国际邮件部等,每个部门都有自己的处理规则和优先级。
2.2.1 分类的层次结构
分类支持多级嵌套,形成一棵“分类树”。这类似于公司的组织架构:根qdisc(CEO)下可创建多个一级分类(副总裁),每个一级分类下又可挂载多个二级分类(经理)。
// Linux内核中class的基本数据结构(简化版)
struct Qdisc_class_common {
u32 classid; // 分类ID
struct hlist_node hnode; // 哈希节点
};
struct Qdisc_class {
struct Qdisc_class_common common;
struct Qdisc *qdisc; // 关联的qdisc
// ... 其他字段
};
2.3 过滤器(Filter)
过滤器是执行分类决策的“裁判”。它如同邮局的自动分拣机,根据数据包“信封”上的信息(如源/目的IP、端口号、协议类型等)来决定其应该被送往哪个分类(部门)。
2.3.1 过滤器的工作原理
每个过滤器通常包含两部分:
- 分类器(Classifier):检查数据包的特征,进行匹配。
- 动作(Action):根据匹配结果执行相应操作,如将包分类到特定class、丢弃或修改包内容。
// 过滤器的关键数据结构
struct tcf_proto {
struct tcf_proto *next; // 下一个过滤器
__be16 protocol; // 协议类型
int prio; // 优先级
struct tcf_chain *chain; // 过滤器链
// ... 其他字段
};
// U32过滤器的匹配规则结构
struct tc_u_knode {
struct tc_u_knode *next; // 下一条规则
u32 handle; // 规则句柄
u32 val; // 匹配值
u32 mask; // 掩码
u32 link_handle; // 链接句柄
struct tc_u_hnode *ht_up; // 上级哈希表
// ... 其他字段
};
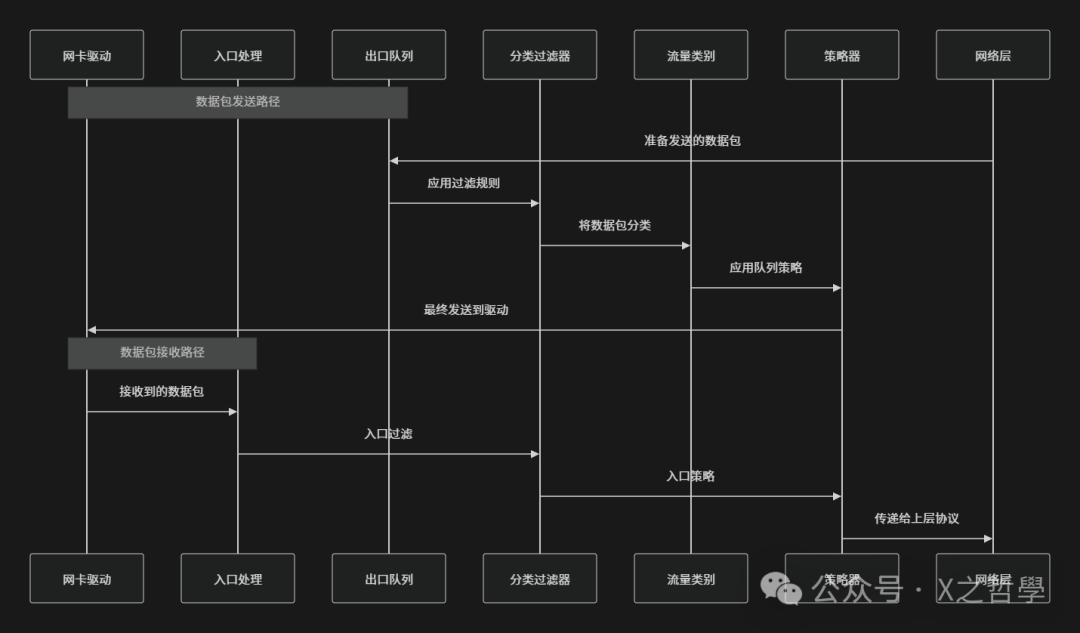
2.4 数据流向全景图

三、关键算法与实现机制
3.1 分层令牌桶(HTB)算法
HTB是Linux中最常用、功能最强大的流量整形算法之一。我们可以用一个多级费率的高速公路系统来类比理解它:
- 每个
class像一个独立的收费站。
- 令牌如同通行许可。
- 速率限制(rate)好比每小时允许通过的基本车辆数。
- 突发限制(burst/ceil)则像临时增加的通行配额。
3.1.1 HTB的工作原理
HTB维护着一个令牌桶系统,令牌以设定的恒定速率生成。发送数据包需要消耗相应数量的令牌。若桶中有充足令牌,数据包可立即发送;否则,数据包将根据策略被延迟发送或丢弃。
// HTB分类的关键数据结构
struct htb_class {
struct Qdisc_class_common common;
/* 速率限制参数 */
struct tc_ratespec rate; // 保证速率
struct tc_ratespec ceil; // 最大速率
/* 令牌桶状态 */
s64 tokens; // 当前令牌数(对应rate)
s64 ctokens; // 当前ceil令牌数
psched_time_t t_c; // 最后检查时间
/* 层次结构 */
struct htb_class *parent; // 父分类指针
struct hlist_node hlist; // 兄弟节点链表
struct list_head sibling; // 子节点链表
/* 队列 */
struct sk_buff_head queue; // 等待队列
// ... 其他字段
};
// HTB qdisc结构
struct htb_sched {
struct Qdisc *qdisc; // 基础qdisc
/* 分类管理 */
struct htb_class root; // 根分类
struct hlist_head hash[HTB_HSIZE]; // 分类哈希表
/* 定时器 */
struct timer_list timer; // 令牌更新定时器
/* 统计 */
u64 now; // 当前时间
// ... 其他字段
};
3.1.2 HTB的层次关系
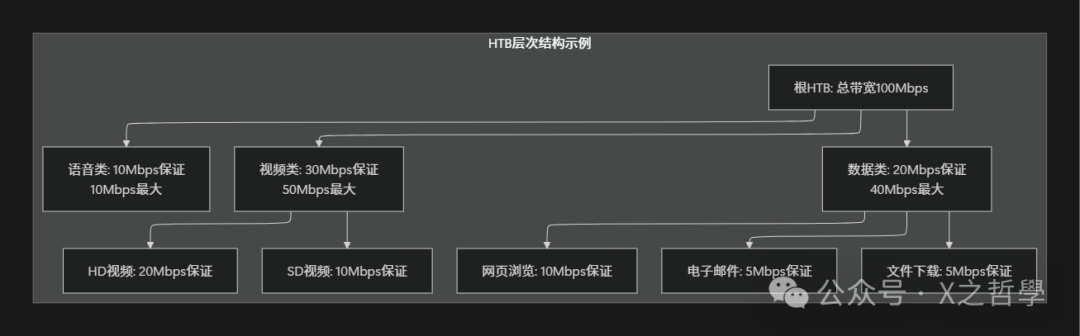
3.2 随机公平队列(SFQ)算法
SFQ算法类似于旋转寿司店的运营模式:每位顾客(一个数据流)拥有固定的座位,寿司(数据包)在传送带上循环。每个座位每次只能取用一盘寿司。这保证了:
- 每位顾客都能获得均等的服务机会。
- 没有顾客能长时间独占传送带。
- 短暂的流量突发可以被平滑且公平地处理。
// SFQ流的状态结构
struct sfq_flow {
struct sk_buff *head; // 队列头指针
struct sk_buff *tail; // 队列尾指针
unsigned short allot; // 当前分配量
unsigned short quantum; // 每次服务的数据量配额
u32 hash; // 流的哈希值
// ... 其他字段
};
// SFQ调度器结构
struct sfq_sched_data {
/* 流的管理 */
struct sfq_flow *flows; // 所有流的数组
unsigned short maxflows; // 最大流数
/* 调度参数 */
unsigned short quantum; // 每个流每次服务的数据量基准值
unsigned short perturbation; // 哈希扰动值(防哈希碰撞)
/* 轮转调度 */
unsigned int slot; // 当前服务的槽位索引
struct timer_list timer; // 调度定时器
// ... 其他字段
};
四、实际配置示例与源码解析
4.1 基本配置:限制总带宽
让我们从一个简单的例子开始:将 eth0 接口的总出口带宽限制为 10Mbps。
# 清理接口上现有的根队列规则
tc qdisc del dev eth0 root
# 添加HTB作为根队列规则,句柄设为1:,默认未分类流量发往ID为10的子类
tc qdisc add dev eth0 root handle 1: htb default 10
# 创建根分类1:1,限制总带宽为10Mbps
tc class add dev eth0 parent 1: classid 1:1 htb rate 10mbit ceil 10mbit
# 创建一个默认子分类1:10,继承根分类的全部带宽
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10mbit ceil 10mbit
# 为该默认子分类关联一个简单的FIFO队列(pfifo),队列深度1000个包
tc qdisc add dev eth0 parent 1:10 handle 10: pfifo limit 1000
4.2 高级配置:多类别流量管理
创建一个更复杂的配置,将流量划分为语音、视频和数据三类,并赋予不同优先级和带宽保证。
#!/bin/bash
# 清理旧配置
tc qdisc del dev eth0 root 2>/dev/null
# 1. 创建根HTB队列
tc qdisc add dev eth0 root handle 1: htb default 30
# 2. 创建根分类,总带宽100Mbps
tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit ceil 100mbit
# 3. 创建子分类
# 语音类 - 高优先级,保证10M,最大10M
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 10mbit ceil 10mbit prio 0
# 视频类 - 中优先级,保证50M,最大80M
tc class add dev eth0 parent 1:1 classid 1:20 htb rate 50mbit ceil 80mbit prio 1
# 数据类 - 低优先级,保证30M,最大100M(可借用空闲带宽)
tc class add dev eth0 parent 1:1 classid 1:30 htb rate 30mbit ceil 100mbit prio 2
# 4. 为每个子分类添加公平队列(SFQ)作为内部队列
for i in 10 20 30; do
tc qdisc add dev eth0 parent 1:$i handle ${i}0: sfq perturb 10
done
# 5. 设置过滤器,基于IP包头的DSCP字段进行分类
# 语音流量(EF: 加速转发,DSCP 46/0xb8)
tc filter add dev eth0 parent 1: protocol ip prio 1 \
u32 match ip tos 0xb8 0xfc \
flowid 1:10
# 视频流量(AF41: 保证转发,DSCP 34/0x88)
tc filter add dev eth0 parent 1: protocol ip prio 2 \
u32 match ip tos 0x88 0xfc \
flowid 1:20
# 默认规则:所有其他流量进入数据类
tc filter add dev eth0 parent 1: protocol ip prio 3 \
u32 match ip dst 0.0.0.0/0 \
flowid 1:30
4.3 代码实现:简化的令牌桶过滤器(TBF)
通过一个简化的TBF实现,理解其核心逻辑。
// 简化的TBF调度器数据结构
struct tbf_sched_data {
/* 速率限制参数 */
u64 rate; // 承诺信息速率(字节/秒)
u64 burst; // 突发大小(字节)
u64 limit; // 队列最大长度(字节)
/* 令牌桶状态 */
u64 tokens; // 当前普通令牌数
u64 ptokens; // 当前峰值令牌数(用于突发)
psched_time_t t_c; // 最后更新时间戳
/* 队列 */
struct sk_buff_head q; // 等待队列
struct Qdisc *qdisc; // 内部队列
/* 统计 */
u32 drops; // 丢包计数
};
// 主要的数据包入队函数
static int tbf_enqueue(struct sk_buff *skb, struct Qdisc *sch)
{
struct tbf_sched_data *q = qdisc_priv(sch);
int ret;
// 更新令牌数量
tbf_update_tokens(q);
// 检查是否有足够令牌发送当前数据包
if (skb->len <= q->tokens) {
// 有足够普通令牌,消耗令牌并放入队列
q->tokens -= skb->len;
ret = qdisc_enqueue_tail(skb, sch);
} else {
// 普通令牌不足,检查峰值令牌是否足够(突发允许)
if (skb->len <= q->ptokens) {
q->ptokens -= skb->len;
ret = qdisc_enqueue_tail(skb, sch);
} else {
// 令牌不足,丢弃数据包
qdisc_drop(skb, sch, &q->drops);
ret = NET_XMIT_DROP;
}
}
return ret;
}
// 令牌更新函数
static void tbf_update_tokens(struct tbf_sched_data *q)
{
psched_time_t now;
u64 elapsed;
// 获取当前时间
now = psched_get_time();
// 计算自上次更新以来经过的时间
elapsed = now - q->t_c;
if (elapsed > 0) {
// 根据经过的时间生成新的令牌
u64 new_tokens = (elapsed * q->rate) >> PSCHED_SHIFT;
// 补充令牌,但不超过桶的容量(burst)
q->tokens = min(q->tokens + new_tokens, q->burst);
q->ptokens = min(q->ptokens + new_tokens, q->burst);
q->t_c = now; // 更新最后检查时间
}
}
五、工具链与调试技巧
5.1 常用tc命令速查表
| 命令 |
功能 |
示例 |
tc qdisc show |
显示队列规则 |
tc qdisc show dev eth0 |
tc class show |
显示分类 |
tc class show dev eth0 |
tc filter show |
显示过滤器 |
tc filter show dev eth0 |
tc qdisc add |
添加队列规则 |
tc qdisc add dev eth0 root htb |
tc class add |
添加分类 |
tc class add ... htb rate 1mbit |
tc filter add |
添加过滤器 |
tc filter add ... u32 match ip dst 1.2.3.4 |
tc qdisc change |
修改队列参数 |
tc qdisc change ... rate 2mbit |
tc qdisc del |
删除队列规则 |
tc qdisc del dev eth0 root |
tc qdisc replace |
替换队列规则 |
tc qdisc replace ... |
5.2 高级监控与调试工具
5.2.1 实时监控工具
# 1. 监控qdisc统计信息(每秒刷新)
watch -n 1 'tc -s qdisc show dev eth0'
# 2. 监控分类统计
watch -n 1 'tc -s class show dev eth0'
# 3. 使用bmon进行实时带宽监控
bmon -p eth0 -r 1
# 4. 使用iftop查看基于连接的实时流量排行
iftop -i eth0 -B
# 5. 使用nethogs查看按进程划分的带宽使用情况
nethogs eth0
5.2.2 调试技巧
# 1. 获取详细的统计信息(-d 显示更多细节)
tc -s -d qdisc show dev eth0
tc -s -d class show dev eth0
tc -s filter show dev eth0
# 2. 检查内核日志中与TC相关的信息
dmesg | grep -i tc
dmesg | grep -i qdisc
# 3. 使用dropwatch工具监控内核丢包点
sudo dropwatch -l kas
# 4. 使用SystemTap进行内核态深度调试(示例:监控入队操作)
stap -e 'probe kernel.function("qdisc_enqueue") {
printf("qdisc enqueue: dev=%s len=%d\n",
kernel_string($skb->dev->name), $skb->len);
}'
# 5. 使用perf分析TC相关性能事件
perf record -e skb:* -a sleep 10
perf script | grep -i qdisc
5.3 故障排除流程图
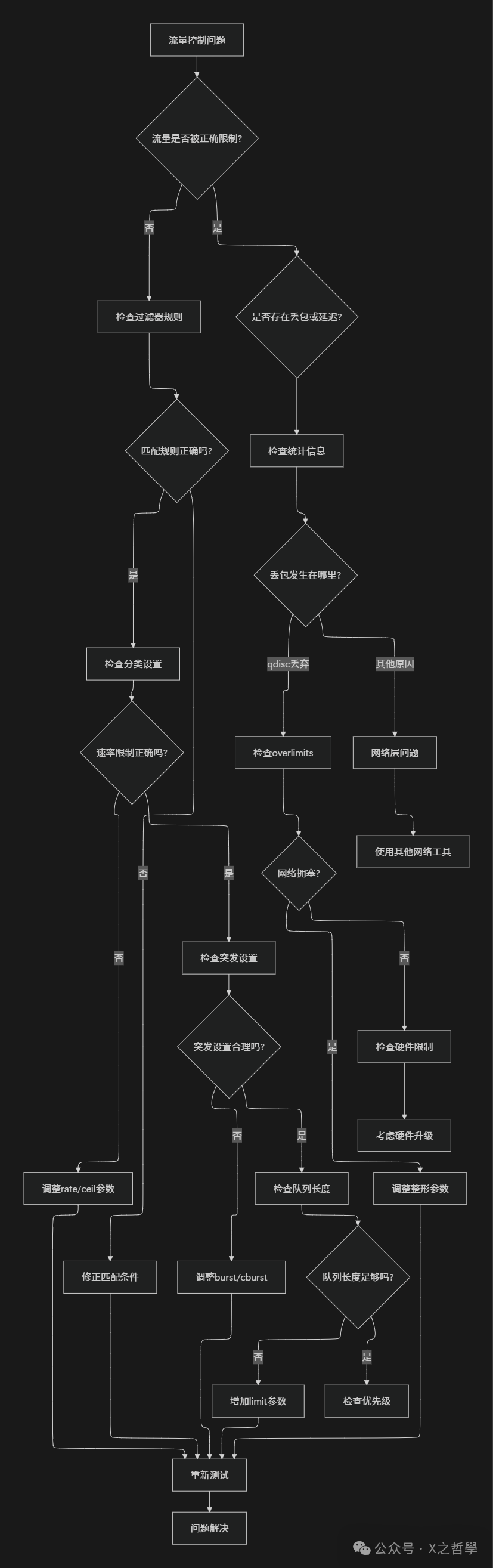
六、性能优化与最佳实践
6.1 性能优化策略
6.1.1 如何选择合适的qdisc
| 场景 |
推荐qdisc |
主要理由 |
| 简单的出口带宽限制 |
TBF |
实现简单,CPU开销小。 |
| 保证多用户/多连接的公平性 |
SFQ / FQ_CODEL |
有效防止单个流垄断带宽,减少缓冲膨胀。 |
| 复杂的层次化流量整形与借用 |
HTB |
功能全面,支持分类和带宽借用,策略灵活。 |
| 对延迟有极致要求的实时应用 |
ETF / TAPRIO |
支持基于时间表的调度,提供确定性延迟。 |
6.1.2 关键参数调优指南
# HTB参数调优示例
tc class add dev eth0 parent 1:1 classid 1:10 \
htb \
rate 100mbit \ # 保证带宽
ceil 200mbit \ # 最大可借用带宽
burst 150k \ # 令牌桶突发容量(通常建议设为 rate/8 左右)
cburst 300k \ # ceil对应的突发容量
prio 0 \ # 优先级(0最高,7最低)
quantum 1500 # 每次调度尝试发送的数据量,建议接近MTU
# SFQ参数调优示例
tc qdisc add dev eth0 parent 1:10 \
sfq \
perturb 10 \ # 重新计算流哈希值的间隔(秒),防哈希碰撞
quantum 1500 \ # 每次从一个流中取出的字节数上限
limit 127 # 可排队的总包数(建议值为 2^n - 1)
6.2 现代流量控制技术
6.2.1 Cake(Common Applications Kept Enhanced)
Cake是一个集成了多种先进特性的现代qdisc,旨在简化配置并智能管理流量。
# 启用Cake(需要内核支持)
sudo tc qdisc add dev eth0 root cake
# Cake的智能特性包括:
# 1. 自动区分批量传输和交互式流量。
# 2. 内置对抗缓冲膨胀(Bufferbloat)的机制。
# 3. 在多个流之间进行公平的带宽分配。
# 4. 致力于保持低延迟。
6.2.2 FQ_CODEL(Fair Queuing with Controlled Delay)
FQ_CODEL巧妙地将公平队列与主动队列管理(AQM)结合,是解决缓冲膨胀的利器。
// FQ_CODEL使用的延迟控制参数
struct codel_params {
u32 target; // 目标队列延迟(默认5ms)
u32 interval; // 检查间隔(默认100ms)
u32 ecn; // 是否启用显式拥塞通知(ECN)
};
// 其核心工作原理:
// 1. 使用流哈希将流量分散到多个内部子队列(FQ)。
// 2. 使用CoDel算法监控每个子队列的排队延迟。
// 3. 当某个流的包延迟持续超过`target`,则开始丢弃或标记该流的包。
// 4. 从而在保证吞吐量的前提下,将队列延迟控制在较低水平。
七、实际应用场景分析
7.1 家庭路由器智能QoS场景
家庭路由器需要智能管理不同设备(手机、电视、电脑)和不同应用(游戏、视频、网页、下载)的带宽,以保障核心体验。
#!/bin/bash
# 家庭路由器智能QoS配置脚本
# 定义设备MAC地址
DEVICE_PHONE="aa:bb:cc:dd:ee:ff"
DEVICE_TV="11:22:33:44:55:66"
DEVICE_LAPTOP="77:88:99:aa:bb:cc"
# 重置配置
tc qdisc del dev eth0 root 2>/dev/null
# 1. 设置根队列(假设外网总带宽为100Mbps)
tc qdisc add dev eth0 root handle 1: htb default 30
# 2. 创建根分类
tc class add dev eth0 parent 1: classid 1:1 htb rate 100mbit ceil 100mbit
# 3. 创建业务子分类(优先级由高到低)
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 20mbit ceil 40mbit prio 0 # 游戏/语音
tc class add dev eth0 parent 1:1 classid 1:20 htb rate 40mbit ceil 80mbit prio 1 # 视频流
tc class add dev eth0 parent 1:1 classid 1:30 htb rate 30mbit ceil 60mbit prio 2 # 网页/聊天
tc class add dev eth0 parent 1:1 classid 1:40 htb rate 10mbit ceil 30mbit prio 3 # 文件下载
# 4. 为每个子分类关联FQ_CODEL队列(现代推荐)
for i in 10 20 30 40; do
tc qdisc add dev eth0 parent 1:$i handle ${i}0: fq_codel limit 1000
done
# 5. 配置分类过滤器
# 基于MAC地址的设备分类
tc filter add dev eth0 parent 1: protocol all prio 1 \
basic match "mac($DEVICE_PHONE)" \
flowid 1:10
tc filter add dev eth0 parent 1: protocol all prio 2 \
basic match "mac($DEVICE_TV)" \
flowid 1:20
# 基于目标端口的应用分类(示例)
tc filter add dev eth0 parent 1: protocol ip prio 10 \
u32 match ip dport 1935 0xFFFF \ # 示例:游戏流端口
flowid 1:10
tc filter add dev eth0 parent 1: protocol ip prio 20 \
u32 match ip dport 554 0xFFFF \ # RTSP视频流
flowid 1:20
tc filter add dev eth0 parent 1: protocol ip prio 30 \
u32 match ip dport 80 0xFFFF \
match ip dport 443 0xFFFF \ # HTTP/HTTPS
flowid 1:30
tc filter add dev eth0 parent 1: protocol ip prio 40 \
u32 match ip dport 20 0xFFFF \
match ip dport 21 0xFFFF \ # FTP
flowid 1:40
# 默认规则
tc filter add dev eth0 parent 1: protocol all prio 100 \
match any any \
flowid 1:30
7.2 云计算多租户网络隔离场景
在云平台中,需要为不同租户或不同业务实例提供带宽保证与隔离。
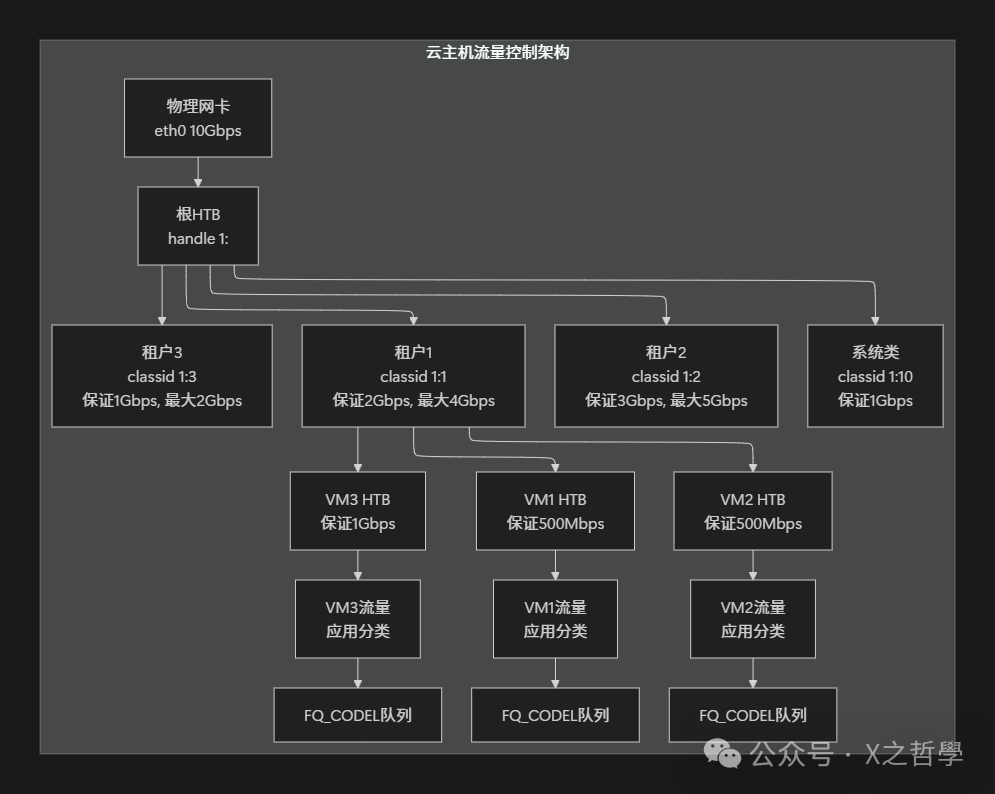
八、内核实现深度剖析
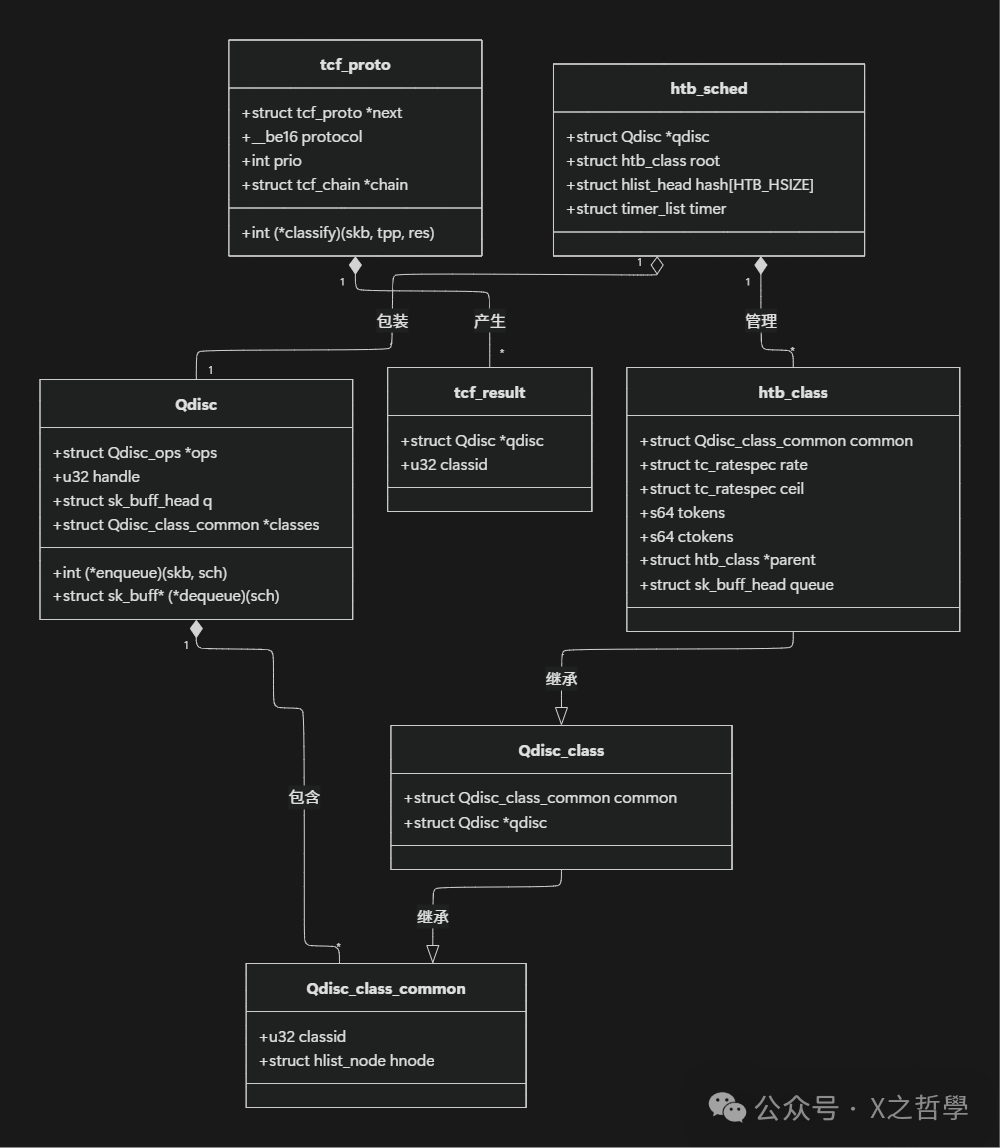
8.1 核心数据结构关系图
8.2 关键函数调用链
以下简化的调用链展示了数据包在Linux网络栈中经历TC处理的主要路径:
// 发送路径上的TC关键调用链
dev_queue_xmit()
↓
__dev_queue_xmit()
↓
sch_direct_xmit()
↓
qdisc_enqueue() // 数据包进入qdisc队列
↓
qdisc_run()
↓
qdisc_restart()
↓
dequeue_skb() // 尝试从qdisc取出数据包
↓
ops->dequeue() // 调用具体qdisc的dequeue方法,例如:
↓
htb_dequeue() // 以HTB为例
↓
htb_dequeue_tree() // 遍历分类树选择下一个要发送的class
↓
qdisc_bstats_update() // 更新队列统计信息
↓
dev_hard_start_xmit() // 最终交付给网卡驱动发送
8.3 性能关键点分析
- 锁竞争:对qdisc和class的操作通常需要锁保护,高并发下可能成为瓶颈。
- 内存分配:
sk_buff的频繁分配和释放对性能影响显著。
- 定时器开销:HTB等算法的令牌更新、SFQ的轮转调度都依赖于内核定时器。
- 哈希计算:分类器(如U32、BPF)和数据流识别(如SFQ)中的哈希计算消耗CPU。
优化建议:
- 采用RCU(读-复制-更新)机制减少锁争用。
- 使用
sk_buff缓存或池化技术。
- 合并多个定时器任务,减少触发频率。
- 选择计算高效的哈希算法(如Jenkins hash)。
九、总结
9.1 技术演进脉络
| Linux流量控制技术历经二十余年发展,从基础队列演进为智能调度系统: |
时期 |
代表技术 |
核心特点 |
| 1990s |
FIFO, TBF |
提供基础的先进先出和令牌桶限速功能。 |
| 2000s |
HTB, CBQ, SFQ |
支持复杂的层次化分类、带宽借用和公平队列。 |
| 2010s |
FQ_CODEL, PIE |
重点关注对抗缓冲膨胀(Bufferbloat),实现低延迟。 |
| 2020s |
CAKE, ETF, TAPRIO |
智能化、集成化,支持时间敏感网络(TSN)。 |
9.2 核心要点回顾
- 模块化架构:qdisc、class、filter三者分离,可通过 tc命令行工具 灵活组合,是系统管理员进行网络调优的利器。
- 层次化管理:支持树状多级分类,实现对网络流量的精细化管控。
- 算法多样性:针对限速、整形、公平、低延迟等不同场景,提供了TBF、HTB、SFQ、FQ_CODEL等多种算法。
- 用户态配置:通过
iproute2包中的tc命令进行全部配置,策略调整无需重启。
- 内核态高性能:实现在内核网络协议栈的关键路径上,保证了处理效率。
Linux流量控制系统充分体现了其内核设计的哲学:机制与策略分离,在提供强大能力的同时保持架构的清晰与灵活。掌握它需要对网络原理和Linux系统有深入理解,但这项技能将使你能够为任何复杂场景下的网络流量规划出高效、稳定、公平的“交通规则”。
 发表于 2025-12-18 23:39:39
|
查看: 291|
回复: 0
发表于 2025-12-18 23:39:39
|
查看: 291|
回复: 0
