在实际的微信小程序安全分析与研究过程中,我们常会遇到核心通信数据被加密的情况。本文将基于一个真实案例,详细分析如何通过动态调试定位并解析其使用的SM4国密加密算法流程,并分享在面对代码混淆、反调试等保护措施时的应对思路。
环境准备与工具选择
要进行微信小程序的动态调试,首先需要特定的开发者工具版本。经测试,最新版本的微信开发者工具(如版本11275)已无法使用某些开源工具(如 WeChatOpenDevTools-Python)开启 DevTools。
因此,我们需要使用一个特定的旧版本:3.9.10.27(默认端口8555)。安装后需注意,该版本有自动升级到新版的风险。解决方法包括:在虚拟机中使用快照功能,升级后恢复;或每次启动前删除其他版本文件夹,仅保留目标版本文件夹。
目标分析与加密类型判断
本次分析的目标是某款小程序。通过抓包工具(如 Fiddler)捕获其网络请求,可以发现请求与响应内容均为密文。
一个快速判断加密类型的方法是:在相同业务状态下发起两次相同的请求。如果两个请求包体完全一致,则通常为对称加密(需注意,若请求体包含时间戳等变化参数用于验签,则此方法不适用)。本例即属于对称加密场景,并进一步确定为国密算法。
本次逆向分析面临的挑战主要有:
- 严重的代码混淆。
- 内部存在大量名称、功能相似的加密函数,调用关系复杂,干扰判断。
- 内置了
debugger 语句等反调试机制。
- 数据经过多层加密处理,难以直接追踪明文。
核心加密流程动态定位
面对高度混淆的代码,动态调试是定位关键函数的不二法门。本文不赘述如何寻找初始断点,而是假设已通过堆栈回溯等方式,在可能的加解密路径上设置了断点。
通过一路跟进(F9),我们最终定位到两个关键函数:
-
parse: function(t):此函数至关重要,它既是请求加密前的明文处理点,也是响应解密后的数据输出点。同时,它也是密钥(Key)和初始化向量(IV)的生成位置。定位此函数往往需要反复调试与验证。
-
加密调用点:在 parse 函数中,存在一个复杂的条件赋值语句,这是触发真正加密操作的起点。
z = _gIF$.p(r, _gIF$.h(_gIF$.aC)) || ... ? (_gIF$.y, _encrypt[_gIF$.g(_gIF$.bh)])(p) : (_gIF$.y,_jiami[_gIF$.g(_gIF$.bi)])(p);
在此处步入(F9),才能进入加密算法实现的第一个混淆函数。
SM4加密算法细节还原
跟进上述加密调用点后,会经过几层跳转,最终到达核心的加密函数 isec_crypto_sm4_encrypt: function(t)。
在此函数入口处,我们可以观察到关键的输入参数:
t.plaintext: 待加密的明文,实际为Base64编码后的字符串。t.key: 加密密钥,以Base64格式表示。t.iv: 初始化向量,以Base64格式表示。
函数内部会进一步调用一个高度混淆的函数 function I(G) 来完成加密。在此函数中,可以观察到其内部操作:
- 将Base64编码的
t.key 和 t.iv 转换为Hex(十六进制)格式。
- 将Base64编码的
t.plaintext(即原始的请求JSON数据经Base64编码的结果)作为明文输入。
- 使用SM4算法的CBC模式进行加密。
- 填充方式为PKCS7。
梳理完整的加密数据流如下:
- 构造明文JSON,包含
openId、blackBox(小程序路由等信息的Base64)以及用户输入(如手机号、短信验证码)。
- 对整个JSON字符串进行Base64编码,得到
plaintext。
- 将
plaintext、key、iv 传入加密函数。
- 在加密函数内部,
key、iv、以及plaintext中某些字段(如手机号)会经历Base64到Hex的转换。
- 最终执行SM4-CBC加密,输出结果可能再经过Hex或Base64编码后发送。
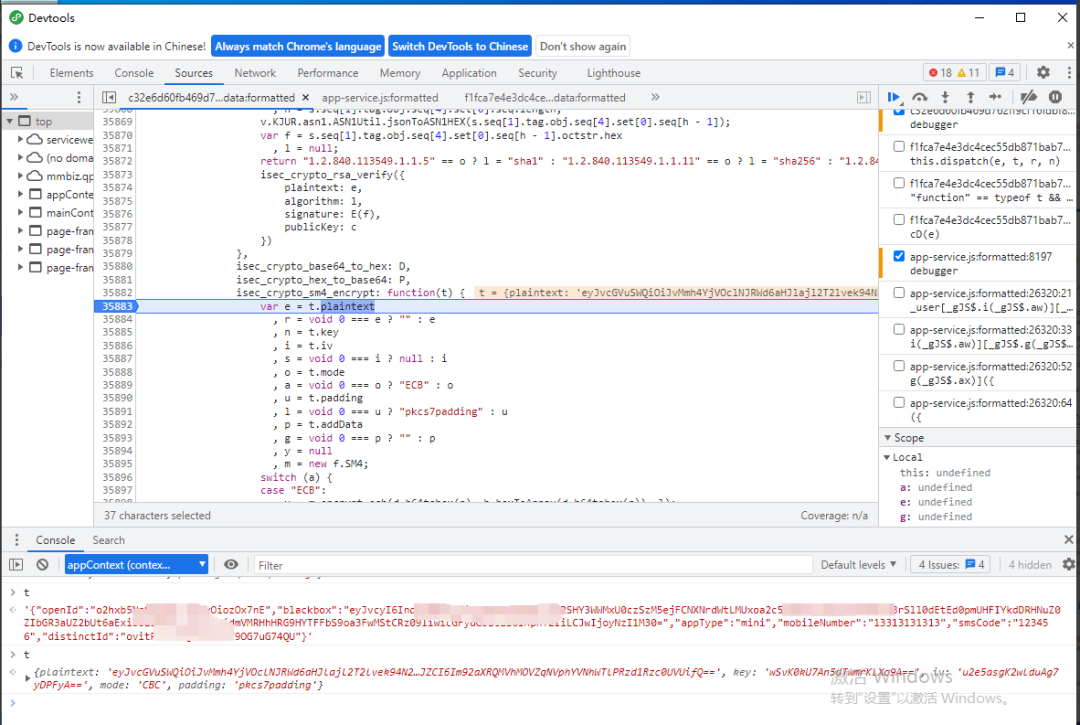
在动态调试中,当程序执行到加密函数内部时,我们可以清晰地看到明文的Base64内容、密钥以及中间转换过程。理解整个流程后,无论是为了安全分析还是其他合规研究,都能清晰地把握数据从明文到密文的每一步变化,这对于深入理解小程序的安全机制至关重要。 |  发表于 2025-12-19 00:24:04
|
查看: 297|
回复: 0
发表于 2025-12-19 00:24:04
|
查看: 297|
回复: 0
