“预训练-微调”范式已成为构建AI应用的标准流程。随着业务需求的多样化,为不同任务专门微调的模型数量急剧增加,带来了高昂的维护与管理成本。一个直观的解决方案是:能否将这些单一任务的“专家”模型,高效地整合成一个通用的“多面手”模型?
模型融合技术为此提供了可能。它无需重新进行昂贵的多任务联合训练,而是直接对多个已完成微调的模型参数进行操作,通过轻量级的合并策略,将各自的能力集成到一个统一的模型中。早期的经典方法是Task Arithmetic,其核心思想是将每个微调模型与基础预训练模型的参数差值视为一个“任务向量”,通过对这些向量进行线性叠加来融合多任务能力。
然而,Task Arithmetic方法在任务差异较大时效果并不稳定。当不同任务的需求存在矛盾时,其对应的任务向量可能在参数空间中方向相反或强度不一,导致直接相加后性能相互抵消或掩盖,即发生了“知识冲突”。这成为了制约模型融合技术实用化的核心瓶颈。
本文将深入解析三种旨在解决知识冲突的前沿融合方法,它们构成了从粗放到精细的技术演进路径:
- TATR:在参数维度层面识别并过滤冲突维度,仅在可信区域进行融合。
- CAT Merging:在更高维的子空间层面定位冲突方向,通过投影消除干扰。
- LOT Merging:在冲突空间内依据任务重要性进行自适应加权融合,而非简单删除。
实验表明,这些基于“冲突感知”的人工智能融合策略,能显著提升多任务模型在复杂场景下的性能与鲁棒性。

研究背景:从Task Arithmetic到知识冲突
Task Arithmetic是模型融合领域的奠基性工作。给定一个预训练模型 ( \theta_0 ) 及其在 ( n ) 个任务上微调后的模型 ( \theta_i ),每个任务的更新被定义为任务向量 ( \tau_i = \theta_i - \theta0 )。融合模型通过将这些向量加权求和得到:
[
\theta{\text{merge}} = \theta0 + \sum{i=1}^{n} \lambda_i \tau_i
]
其中 ( \lambda_i ) 是手工选择的缩放系数。
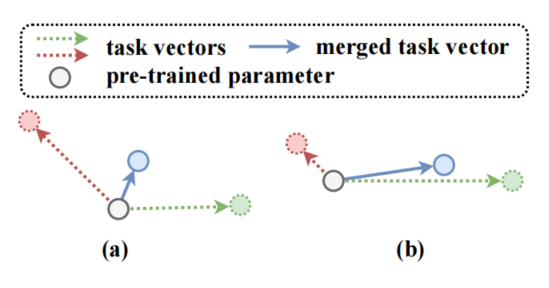
图表1 任务向量的方向(a)或尺度(b)不一致时,可能会导致知识冲突
但在实际应用中,简单的线性相加往往失效,根源在于“知识冲突”。如图1所示:(a) 当两个任务向量方向相反时,相加会导致效果折中,双双削弱;(b) 当向量幅度差异巨大时,小任务的知识容易被大任务淹没。知识冲突可形式化定义为融合模型在特定任务上的损失,相较于其专属微调模型变差的程度。
后续介绍的三项工作,正是围绕如何量化并缓解这一冲突而展开,技术思想从维度筛选演进至空间投影与自适应加权。
方法一:TATR —— 基于可信区域的维度筛选融合
TATR的核心洞见在于:并非所有参数维度都适合参与融合。它首先评估任务 ( i ) 对任务 ( j ) 的冲突程度 ( C_{i \to j} ),定义为加入任务 ( i ) 的向量后,任务 ( j ) 的损失变化。通过理论推导,该冲突近似于任务向量 ( \tau_i ) 与任务 ( j ) 的梯度 ( g_j ) 的点积。
据此,TATR将每个参数维度 ( d ) 根据 ( \tau_i[d] \cdot gj[d] ) 的值分为三类:正分量、负分量和正交分量。有趣的是,实验发现正交分量引发的冲突最小,而正/负分量都可能造成较大干扰。因此,TATR定义了一个“可信区域”掩码 ( M ),筛选出那些在不同任务间冲突较低的维度(即接近正交的部分),融合公式调整为:
[
\theta{\text{merge}} = \theta0 + \sum{i=1}^{n} \lambda_i (M \odot \tau_i)
]
此方法通过规避高冲突维度,实现了更安全的融合。

方法二:CAT Merging —— 冲突子空间投影法
当模型参数具有矩阵等结构化形式时,冲突可能存在于子空间层面。CAT Merging方法将每个任务视为一个线性模型 ( f_i(x) = \tau_i^T x ),其目标是找到一组基向量 ( U ) 张成的“冲突子空间”。通过将其他任务向量投影到该子空间的补空间上,以消除对当前任务的干扰。
具体地,对于任务 ( j ),其消除冲突后的向量为:
[
\tilde{\tau}_i = \tau_i - UU^T\tau_i
]
构建冲突子空间 ( U ) 的优化目标,是最大化一个能同时反映干扰程度与知识保留度的瑞利商。通过求解一个特征值问题,选取主要特征向量作为冲突方向。CAT Merging的融合过程,即是使用这些“净化”后的任务向量进行加权求和。

方法三:LOT Merging —— 基于重要性的自适应层融合
CAT Merging的投影操作可能丢弃包含重要信息的分量。LOT Merging采取了更柔和的策略:在冲突空间内进行自适应加权,而非硬性剔除。
同样在线性模型假设下,LOT Merging寻求一个最优融合向量 ( \tau^ ),使得融合模型在所有任务上的表现与各自专属模型尽可能接近。这导出了一个凸优化问题,其闭式解为:
[
\tau^ = \left( \sum_{i=1}^n Ai \right)^{-1} \left( \sum{i=1}^n A_i \tau_i \right)
]
其中 ( A_i ) 与任务 ( i ) 的特征协方差矩阵相关。该解的本质是所有任务向量的加权平均,权重由各任务在其特征空间中的重要性(( A_i ))动态决定。
理论分析表明,在任务特征空间完全独立的最优情况下,LOT Merging能将各任务向量完美安置于互不干扰的子空间;在最差的全冲突情况下,它会根据任务在冲突方向上的“信号强度”进行软性加权,重要性高的任务占主导,重要性低的任务影响被抑制,从而在保留知识与缓解冲突间取得平衡。这对于复杂的深度学习模型集成尤为重要。
实验结果
研究在视觉(ViT-B/32, ViT-L/14)与多模态(BLIP)模型上进行了广泛的8任务和6任务融合实验。
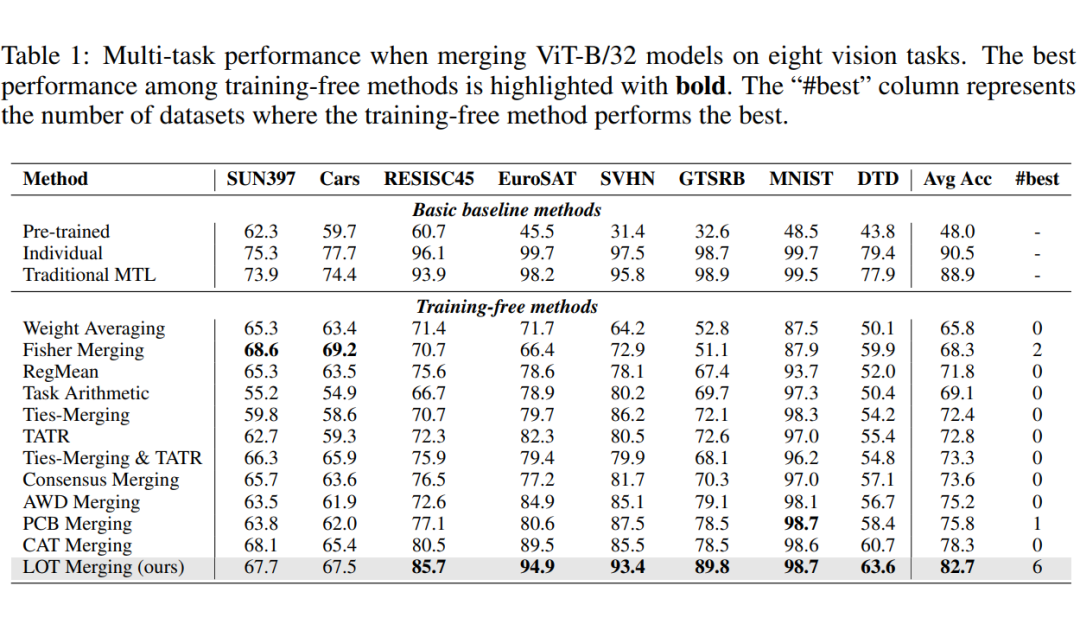
- 在ViT-B/32上,LOT Merging平均准确率达82.7%,比Task Arithmetic提升13.6%,展现了其卓越的冲突处理与知识保留能力。
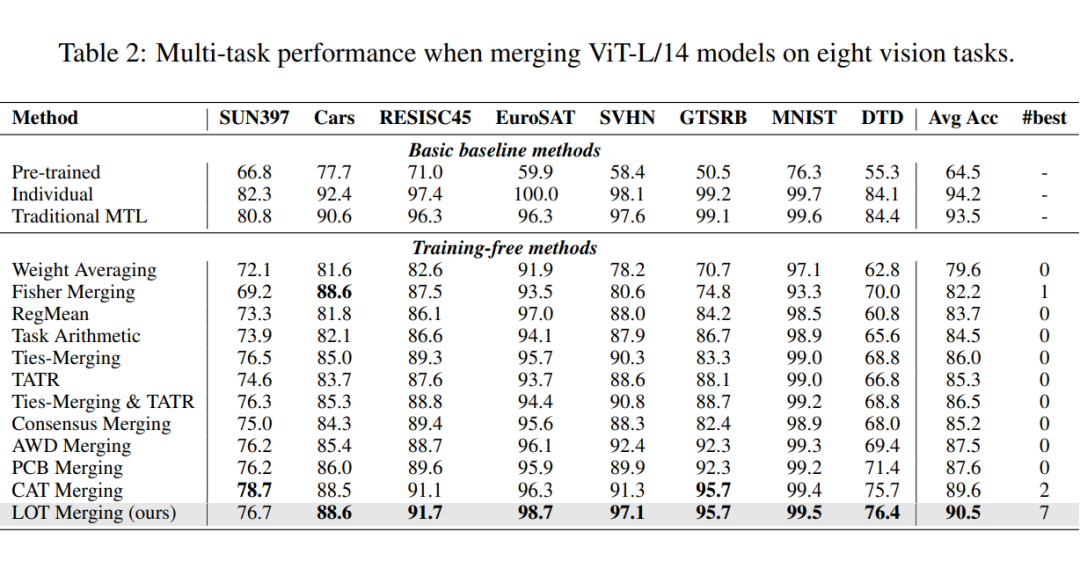
- 在更大规模的ViT-L/14上,LOT Merging仍以90.5%的平均准确率领先,较Task Arithmetic提升6%,证明了其良好的可扩展性。
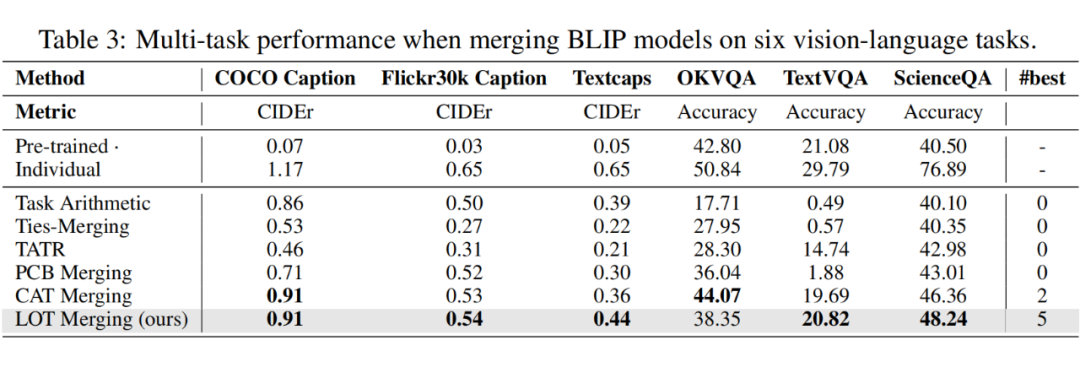
- 在BLIP模型融合中,LOT Merging在多数任务上领先,而CAT Merging在部分任务上表现最佳,说明投影策略在特定场景下具有独特优势。
总结与展望
TATR、CAT Merging与LOT Merging分别从维度、子空间和自适应加权三个由浅入深的层面,系统性地解决了模型融合中的知识冲突问题。它们标志着模型融合技术从简单的参数叠加,迈向了精细化、智能化的协同整合阶段。
展望未来,随着大模型在多任务场景中的深入应用,融合技术将需要应对更异构的任务、更动态的环境。未来的融合机制可能会更加灵活,能够依据任务特性、数据分布实时调整策略,实现真正的自适应多能力集成。本文所述的三种方法为这一方向奠定了坚实的技术基础,开启了高效模型协作与知识整合的新篇章。
 发表于 2025-12-19 03:00:28
|
查看: 310|
回复: 0
发表于 2025-12-19 03:00:28
|
查看: 310|
回复: 0
