
在大语言模型纷纷迈向超长上下文处理的背景下,混合注意力已成为许多先进模型的核心技术组件。其典型做法是利用标准Softmax注意力捕捉局部精细依赖,同时借助线性注意力或状态空间模型来高效处理长程背景信息。
然而,线性注意力长期被视为一种“次优近似”,在超长序列任务中常面临数值不稳定与记忆退化等挑战。
南洋理工大学与复旦大学的最新研究将问题根源指向了实现层面,而非模型结构本身。研究者提出了EFLA(Error-Free Linear Attention),指出过往方法使用一阶欧拉法去离散一个本应有精确解的连续系统,正是导致性能瓶颈的罪魁祸首。关键在于,他们证明了在维持线性时间复杂度的前提下,通过引入无限阶Runge-Kutta级别的解析解,可以彻底消除离散化误差。
这意味着,线性注意力首次在不牺牲效率、不增加参数的情况下,同时获得了稳定性与性能的显著提升,并在多个基准测试中超越了DeltaNet等主流方案。

论文信息

研究背景
当大语言模型需要处理超长的推理轨迹时,标准注意力的二次方复杂度成为了巨大障碍。线性注意力的核心思想是通过维护一个状态矩阵来聚合历史键值对信息,从而实现线性复杂度的推理:
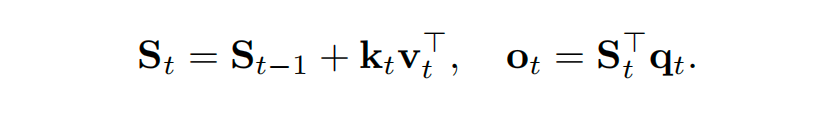
但这种无限制的累加容易导致记忆干扰和状态数值爆炸。为解决此问题,DeltaNet将状态更新建模为一个在线梯度下降过程:
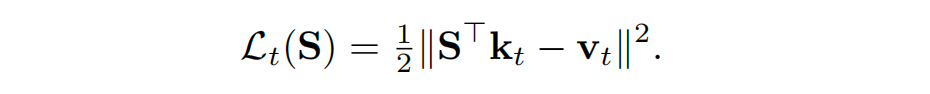
由此推导出的Delta Rule更新公式为:
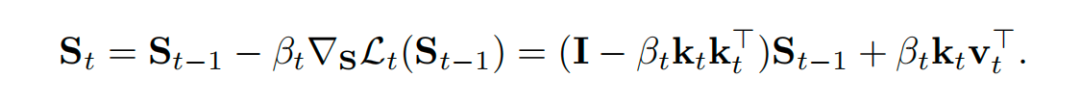
论文指出,这一更新步骤在数学上等价于对一个一阶线性常微分方程进行一阶显式欧拉离散化。该底层连续时间ODE为:
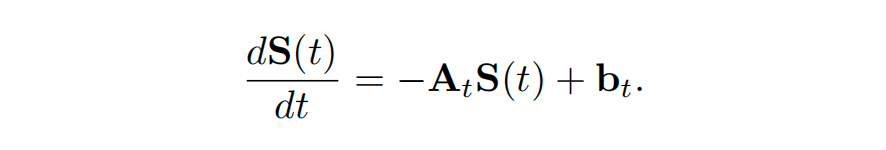
其中 为动力学矩阵, 为输入项。数值分析表明,欧拉法的局部截断误差为 。在处理长上下文或刚性动力学系统时,这种低阶近似会导致误差迅速累积,表现为记忆过早遗忘或数值漂移。此前一些通过引入门控或自适应遗忘系数的改进方法,本质上只是对这种低阶误差的启发式修补。

核心方法:EFLA
研究者提出,消除误差的根本方案不是优化离散步长,而是直接求解底层ODE的解析解。
解析解的导出
基于数字系统中常见的零阶保持假设,可以认为在每个时间步内,状态在分段常数的 和 下演化。该ODE在步长 内的通用解析解为:
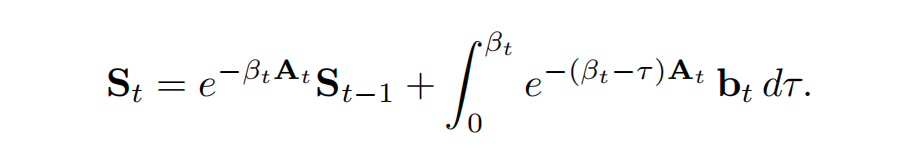
这个解析解代表了数值积分中Runge-Kutta方法在阶数趋于无穷时的极限。
利用Rank-1结构实现高效计算
通常,计算矩阵指数需要 的复杂度。但EFLA的设计者洞察到一个关键数学特性:动力学矩阵 是一个秩为1的矩阵。秩1矩阵具有幂等相关的特殊性质:,其中 。利用这一性质,矩阵指数的泰勒展开可以坍缩为一个简洁的闭式解:
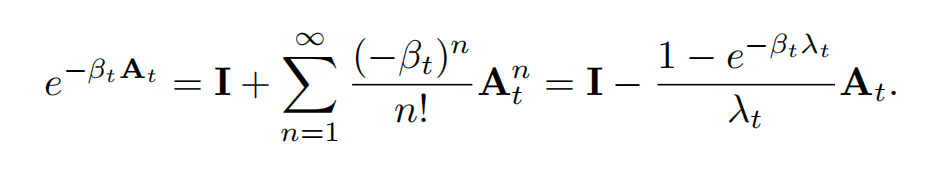
将此项代入积分式并进行代数简化,最终得到EFLA的精确更新规则:
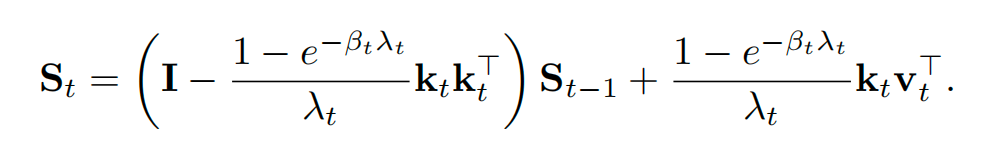
这一公式在彻底消除离散化误差的同时,计算复杂度仍保持在 。这证明了在Rank-1的约束下,获得解析解是“免费”的。
光谱门控与动态遗忘机制
与强制对Key进行归一化的DeltaNet不同,EFLA使用非归一化Key。在此框架下, 项充当了光谱门控的角色:
- 强输入信号:当Key的范数较大时, 会导致状态沿 方向快速指数衰减,迅速清理旧信息为新信息腾出空间。
- 弱输入信号:当Key的范数较小时,衰减过程缓慢,从而最大限度地保留历史背景。这种方向性的衰减机制赋予了EFLA比传统线性注意力更强的记忆动态管理能力。
与Mamba的理论阶数对比
这是一个有趣的对比点。现代SSM模型如Mamba通常采用双线性变换进行离散化,这在数学上等价于隐式二阶Runge-Kutta方法。而EFLA通过利用Rank-1矩阵指数的特性,直接达到了RK-∞的精度水平。这意味着在理论数值精度上,EFLA构成了对现有有限阶SSM方法的一次显著超越。

实验结果
研究者通过Sequential MNIST和大规模语言建模实验验证了EFLA的优越性。
鲁棒性压力测试
在Sequential MNIST任务中,通过人为引入像素丢失、信号缩放和高斯噪声来模拟极端不稳定的输入环境。
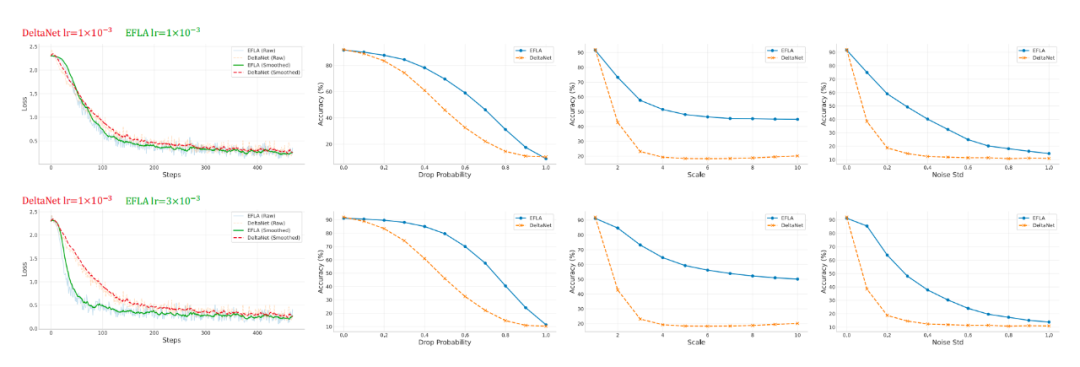
图1. EFLA与DeltaNet在sMNIST上的收敛速度与鲁棒性对比
实验揭示了两个关键现象:
- 对抗信号爆炸:当输入信号被放大时,基于一阶近似的DeltaNet性能迅速崩溃,印证了低阶近似在处理高能信号时的脆弱性。而EFLA凭借其精确的指数饱和机制,有效防止了状态爆炸。
- 高保真记忆:在噪声干扰下,EFLA的性能退化速度远慢于基线模型,证明其构建了更高保真的记忆表示。
语言建模能力评估
在大规模语言建模实验中,EFLA全面超越了DeltaNet基准。
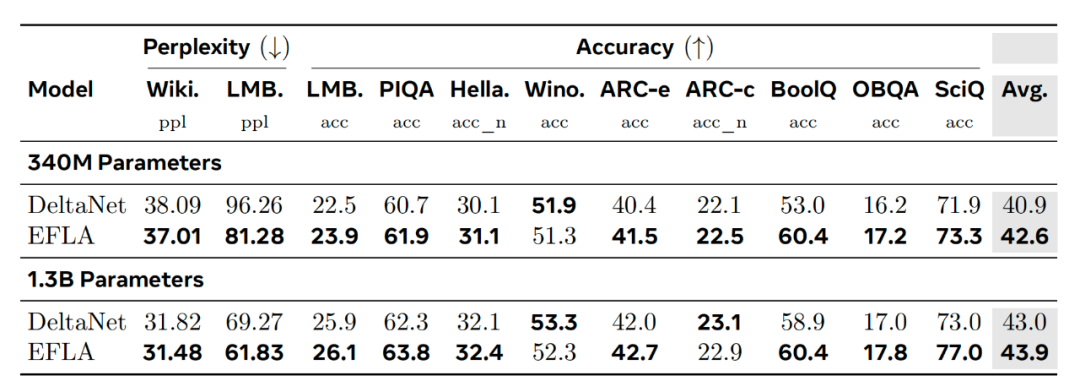
表1. EFLA与DeltaNet在语言建模实验中的结果对比
从表中数据可以清晰看到:
- 在LAMBADA任务上,EFLA将困惑度从96.26显著降低至81.28(340M规模)。
- 在BoolQ准确率上,EFLA实现了+7.4%的大幅提升。
这些结果有力证明,通过消除数值离散化误差,模型能够显著提升对长序列历史信息的记忆精度。
反直觉的优化策略:采用更大学习率
实验发现,由于EFLA存在指数级的饱和效应,可能在训练后期阻碍梯度信号。有趣的是,相比传统保守策略,EFLA在更大的学习率下反而表现出更强的鲁棒性。
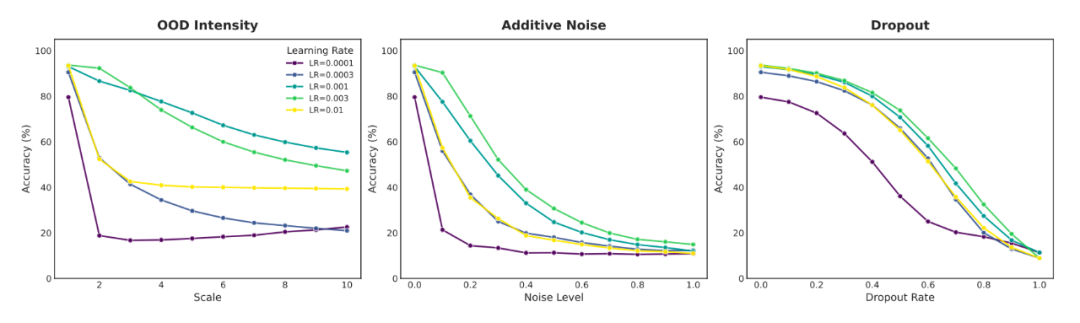
图2. 学习率缩放对EFLA鲁棒性的影响
如图2所示,这种反直觉的超参数设置是充分释放其理论潜力的关键之一。

结语
EFLA是一项兼具理论美感与实用价值的工作。它清晰地表明,线性注意力长期面临的性能瓶颈并非源于架构本身的固有缺陷,而是我们在数值实现上做出的妥协。随着人工智能,特别是大语言模型对长上下文处理的需求日益增长,此类基础性优化显得尤为重要。
通过巧妙利用Rank-1矩阵特性绕过复杂的数值积分,EFLA在不增加任何计算成本的前提下,实现了从一阶欧拉近似到无限阶解析解的跨越。对于当前正深入探索混合注意力架构的业界而言,EFLA提供了一条直接且高效的升级路径。它再次证明,最优雅、最强力的解决方案,往往隐藏在最底层的连续时间动力学方程之中。
 发表于 2025-12-19 02:57:35
|
查看: 236|
回复: 0
发表于 2025-12-19 02:57:35
|
查看: 236|
回复: 0
