Anthropic 近期发布了其旗舰模型 Claude Opus 4.6,标志着其在人工智能领域,特别是编程与复杂任务处理能力上的一次重大升级。这款模型被定位为构建智能体(Agent)和编码任务中最智能的选择。

根据官方介绍,Claude Opus 4.6 在 Opus 4.5 的基础上实现了显著提升。它的规划制定更加周密,能够更长时间、更可靠地执行智能体任务,即使在超大规模代码库中也能稳定运行。模型还增强了自我纠错能力,例如在代码审查和调试方面更加精准。此外,它也是 Anthropic 首款在测试阶段就支持 100 万 Token 上下文的 Opus 级别模型。
性能表现:多项基准测试领先
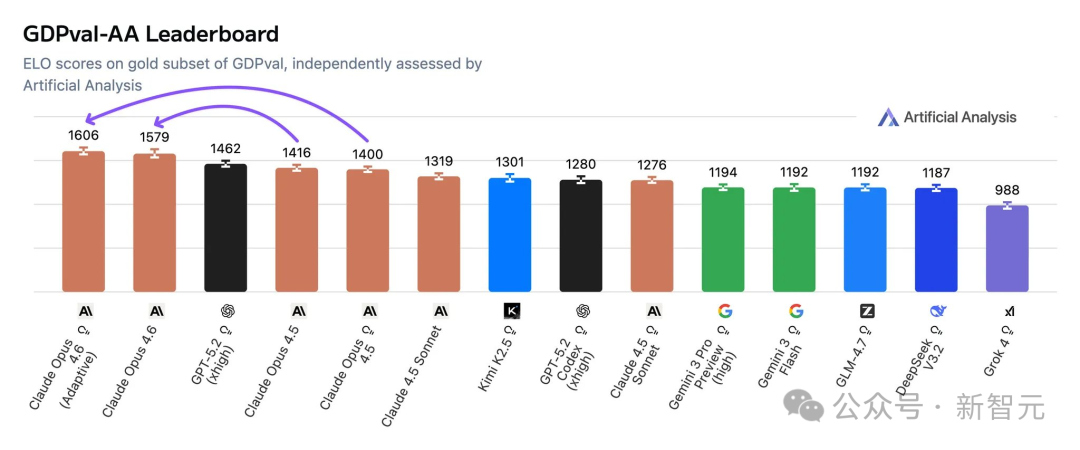
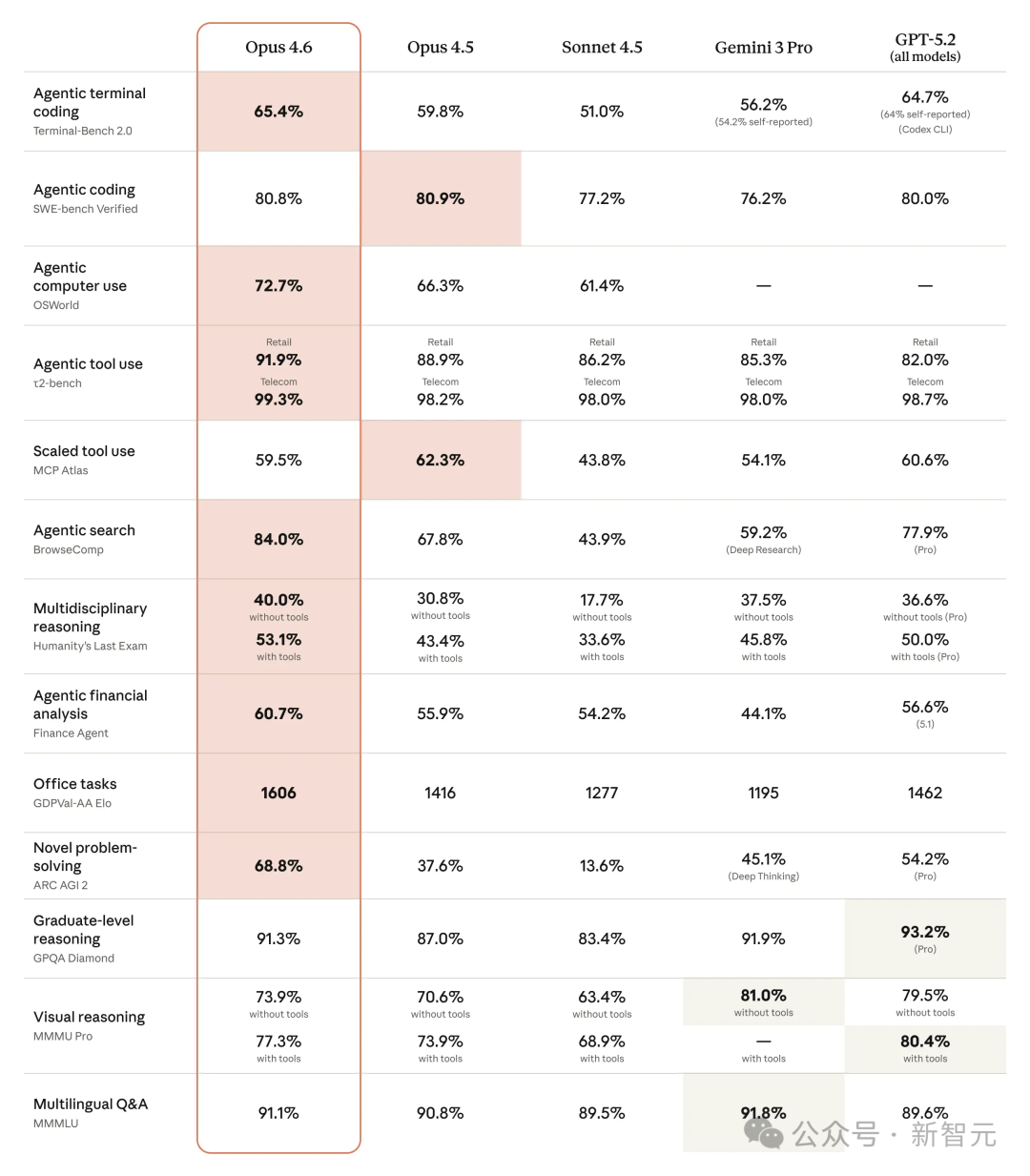
在多项行业基准测试中,Claude Opus 4.6 展现出了全面的竞争力。在评估知识工作的 GDPval-AA(Elo分数)中,它以 1606 分的成绩领先于其他前沿模型。
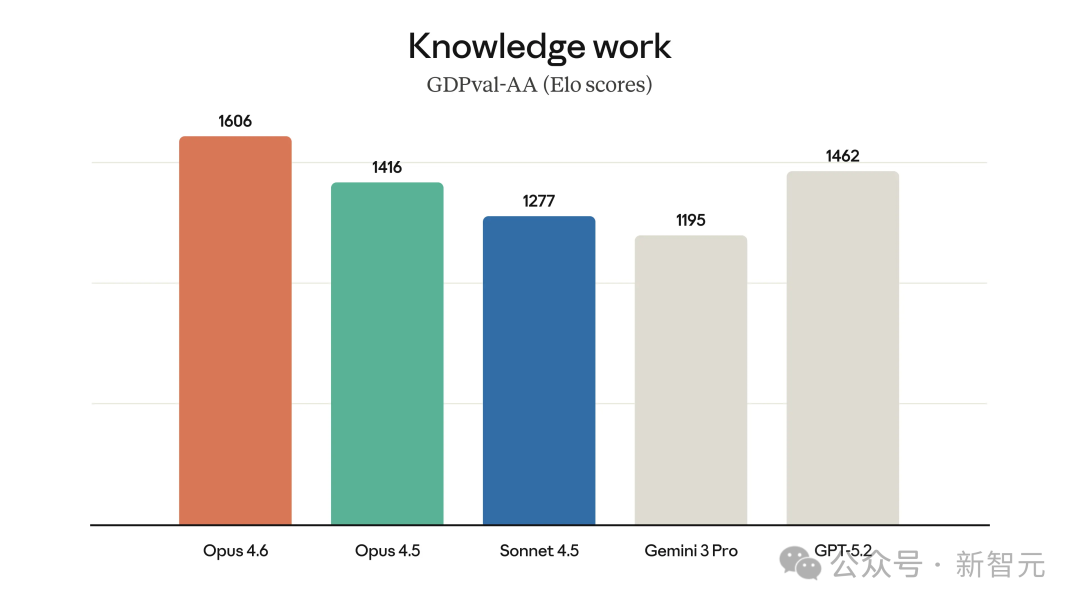
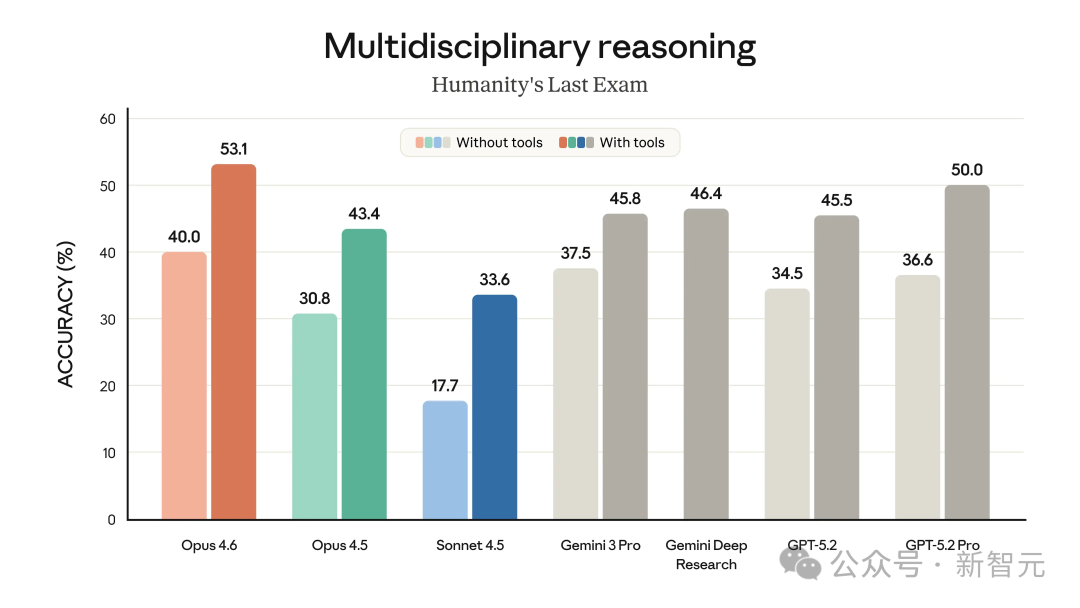
在智能体编程评估 Terminal-Bench 2.0 中,Opus 4.6 取得了 65.4% 的准确率。在多学科推理任务 Humanity‘s Last Exam 中,无论是否使用工具,其表现均领跑其他模型。
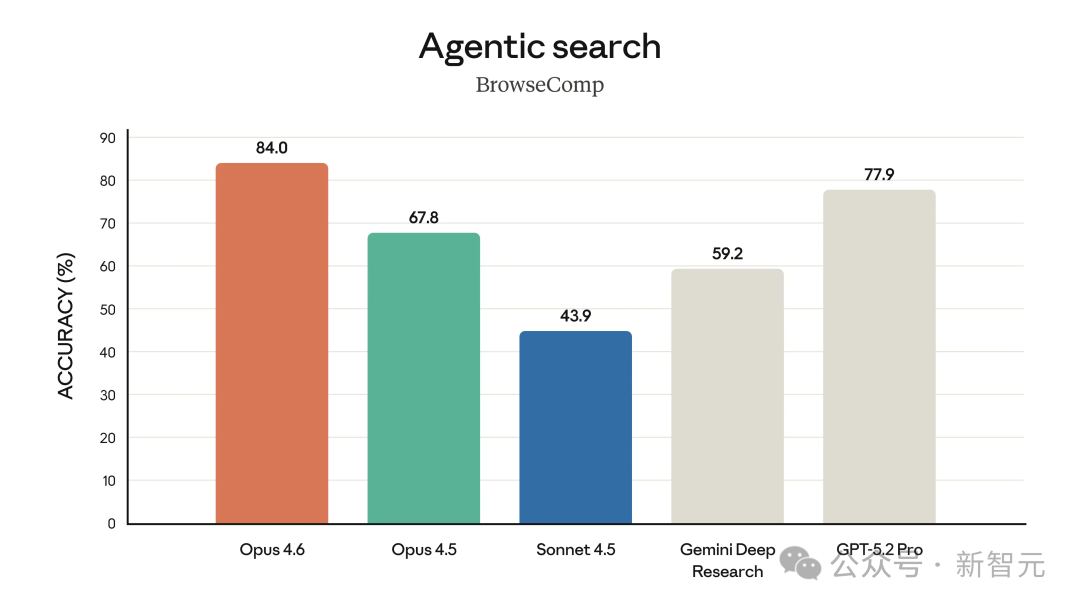
在智能体搜索 BrowseComp 基准上,Opus 4.6 以 84.0% 的准确率表现突出。
更全面的基准测试汇总显示,Opus 4.6 在智能体编程、计算机使用、工具使用、搜索和金融分析等多个领域均处于业界领先地位。例如,在智能体工具使用 t2-bench 测试中,其在零售和电信场景分别获得了 91.9% 和 99.3% 的近满分成绩。
长上下文能力突破
长上下文处理是大型语言模型的核心挑战之一,Opus 4.6 在此方面取得了显著进步。它更擅长从海量文档中检索信息,并能有效减少长对话中的信息衰减(context rot)。
在 MRCR v2 的 8-needle 测试(一种“大海捞针”式检索基准)中,Opus 4.6 在 1M Token 上下文下的匹配率达到了 76%,远高于对比模型。在长上下文推理任务 Graphwalks 中,其表现也优于前代模型。
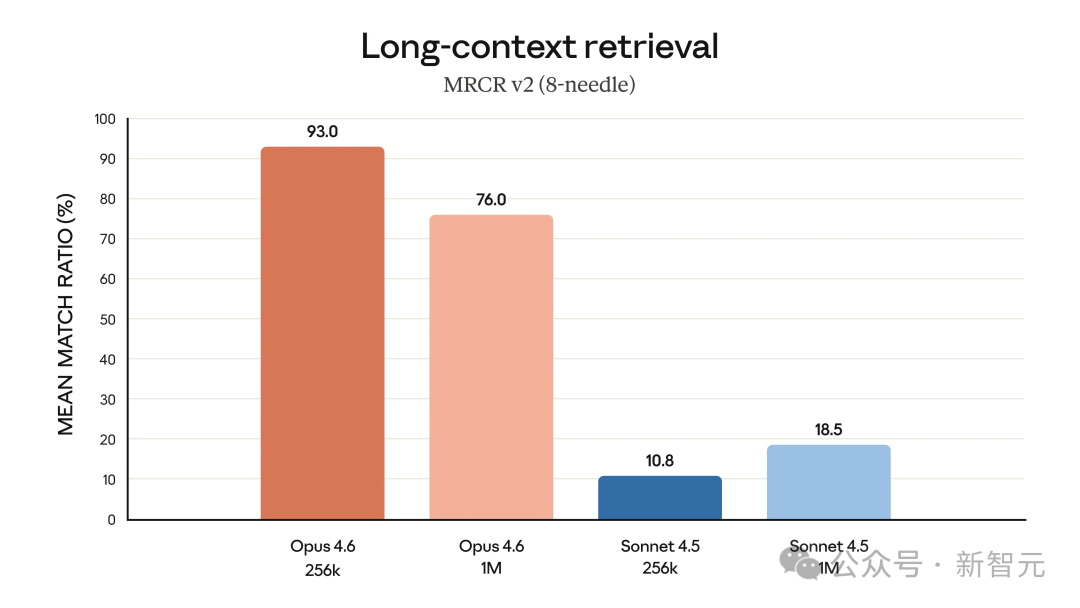

官方表示,Opus 4.6 在保持峰值性能的同时,其实际可用的上下文长度实现了质的飞跃,能够在数十万 Token 中有效地保存、跟踪信息,并捕捉到更深埋的细节。
深度集成 Claude Code:智能体团队(Agent Teams)登场
此次升级的一个关键亮点是 Opus 4.6 与 Claude Code 的深度集成,引入了“智能体团队”(Agent Teams,或称智能体群 Agent Swarms)功能。

这意味着开发者可以协调多个 Claude Code 实例协同工作。任务不再由单个智能体线性处理,而是可以被分发给一个团队,成员之间可以并行开展调研、调试、开发工作,并实时沟通协作。
这种方式与传统的“子智能体”(Subagent)模式不同。在团队模式下,每个成员拥有独立的上下文窗口,可以直接相互通信并进行自我协调,更适用于需要讨论与协作的复杂工作,而子智能体则主要在单一会话内向主智能体汇报结果。

官方实验:AI 团队自主开发 C 编译器
为了展示智能体团队的潜力,Anthropic 进行了一项实验:让一个由 16 个 Claude Opus 4.6 实例组成的团队,在几乎无人干预的情况下,从零开始用 Rust 语言编写一个能编译 Linux 内核的 C 编译器。
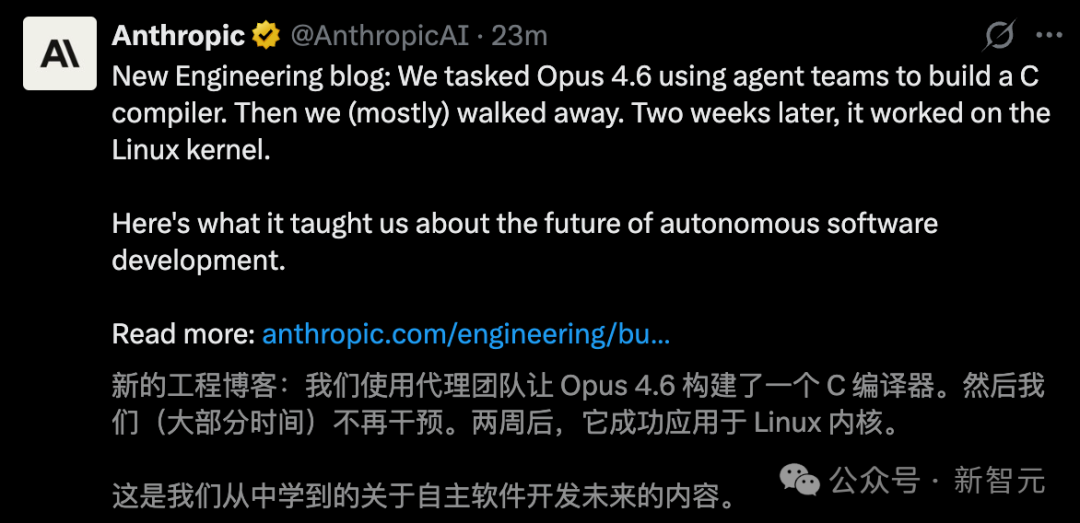
实验采用了基于 Git 的任务锁机制来协调工作,不同的 AI 实例分别负责不同的模块,如修复 Bug、编写文档、优化代码和重构架构。经过约两周时间,消耗了近 20 亿输入 Token(约合 2 万美元 API 成本),该 AI 团队最终产出了一个约 10 万行代码的编译器。这个编译器成功编译了 Linux 6.9 内核(支持 x86、ARM 和 RISC-V 架构),并能运行《毁灭战士》(Doom)、PostgreSQL、Redis 等复杂项目。
其他特性与开发者信息
- 自适应思考与力度控制:Opus 4.6 引入了“自适应思考”(adaptive thinking),模型可根据上下文自行判断是否需要延长思考时间。同时,开发者可以通过全新的“思考力度”(Effort)控制,在智能、速度和成本之间进行权衡。
- API 定价与上下文:
- 标准定价为输入 5 美元/百万 Token,输出 25 美元/百万 Token。
- 它是首款支持 100 万 Token 上下文的 Opus 模型(测试阶段)。对于超过 20 万 Token 的提示,将按高阶费率计费。
- 支持高达 128K Token 的单次输出。
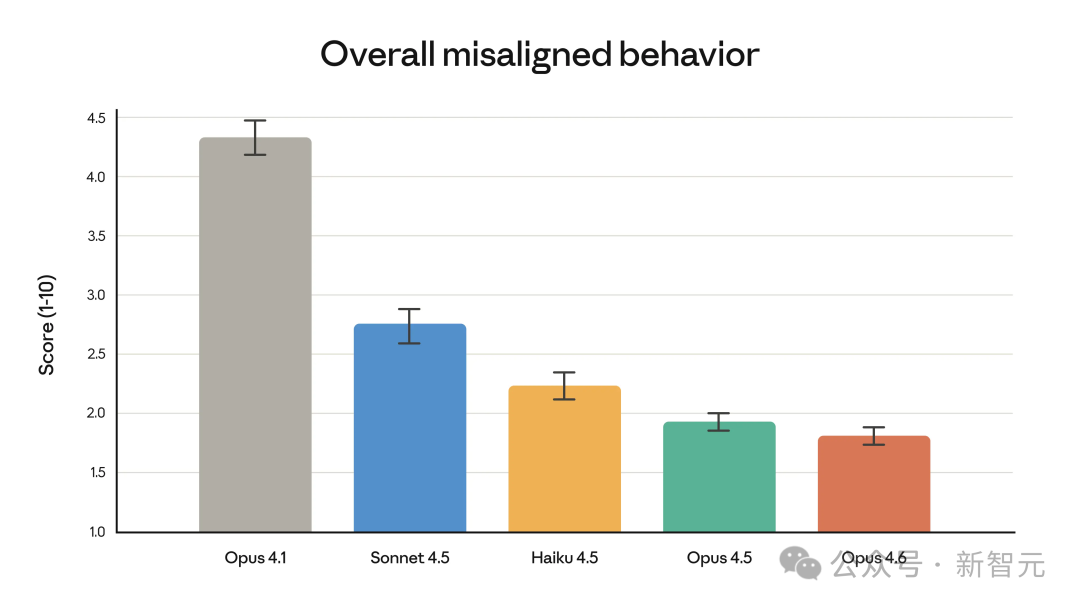
- 安全性与对齐:官方称,在自动化行为审计中,Opus 4.6 表现出较低的错误行为发生率(如欺骗、过度迎合),其安全性与 Opus 4.5 保持一致,并且在最近的 Claude 模型中具有最低的良性查询拒绝率。
生态伙伴评价
多家知名技术公司的负责人对 Opus 4.6 给出了积极评价:
- GitHub:早期测试表明,它能处理开发者日常面临的复杂、多步骤编码工作,尤其是需要规划和工具调用的智能体工作流。
- Replit:在智能体规划方面实现了巨大飞跃,能拆解复杂任务并并行运行。
- Cognition:在解决复杂问题时的推理能力达到了新高度,能考虑边缘情况。
- Figma:在生成复杂、交互式应用和原型方面展现出令人印象深刻的创意范围。
总结
Claude Opus 4.6 的发布,不仅仅是模型性能的迭代。通过大幅提升的编程与推理能力、革命性的百万 Token 上下文支持、以及与 Claude Code 深度整合的智能体团队功能,它正试图将 AI 从辅助工具推向真正的“工作伙伴”角色,旨在重塑知识工作的范式。对于开发者社区和广大技术爱好者而言,这标志着开源实战与自动化软件开发进入了新的阶段。随着此类技术的快速演进,整个软件开发和知识工作的流程与边界也正在被重新定义。想了解更多前沿技术动态与深度解析,欢迎关注 云栈社区 的相关讨论。
 发表于 2026-2-7 11:20:23
|
查看: 227|
回复: 0
发表于 2026-2-7 11:20:23
|
查看: 227|
回复: 0
