就在过去一小时内,人工智能领域迎来密集更新:OpenAI 发布了 GPT-5.3-Codex,而 Anthropic 则推出了 Claude Opus 4.6。
紧随其后,OpenAI 发布了 GPT-5.3-Codex,并宣称这是迄今为止最强大的 agentic coding 模型。
自我训练:模型参与自身创造过程
GPT-5.3-Codex 展现了一个引人注目的特性:它深度参与了自己的创造过程。

OpenAI 团队在研发过程中,使用早期版本的 GPT-5.3-Codex 来调试自身的训练流程、管理部署过程、诊断测试结果并进行评估。简而言之,这个模型协助“孵化”了它自己。
研究团队利用 Codex 监控和调试整个训练过程。它不仅能排查基础设施问题,还能追踪训练模式的变化,对交互质量进行深度分析,提出修复建议,甚至为研究人员构建可视化应用来精确理解模型行为的差异。
工程团队也借助 Codex 来优化和适配 GPT-5.3-Codex 的运行环境。当出现影响用户的边缘情况时,团队会直接让 Codex 去定位上下文渲染的 Bug,并排查缓存命中率低的根本原因。在发布期间,GPT-5.3-Codex 甚至协助团队动态扩展或收缩 GPU 集群以应对流量高峰,确保服务延迟的稳定。
性能飞跃:全面刷新基准测试纪录
GPT-5.3-Codex 在多项关键基准测试中取得了突破性成绩。
-
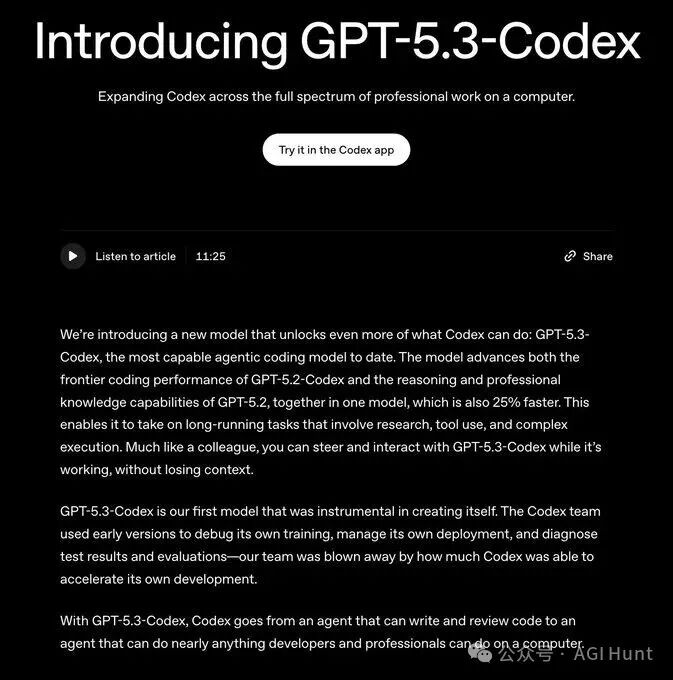
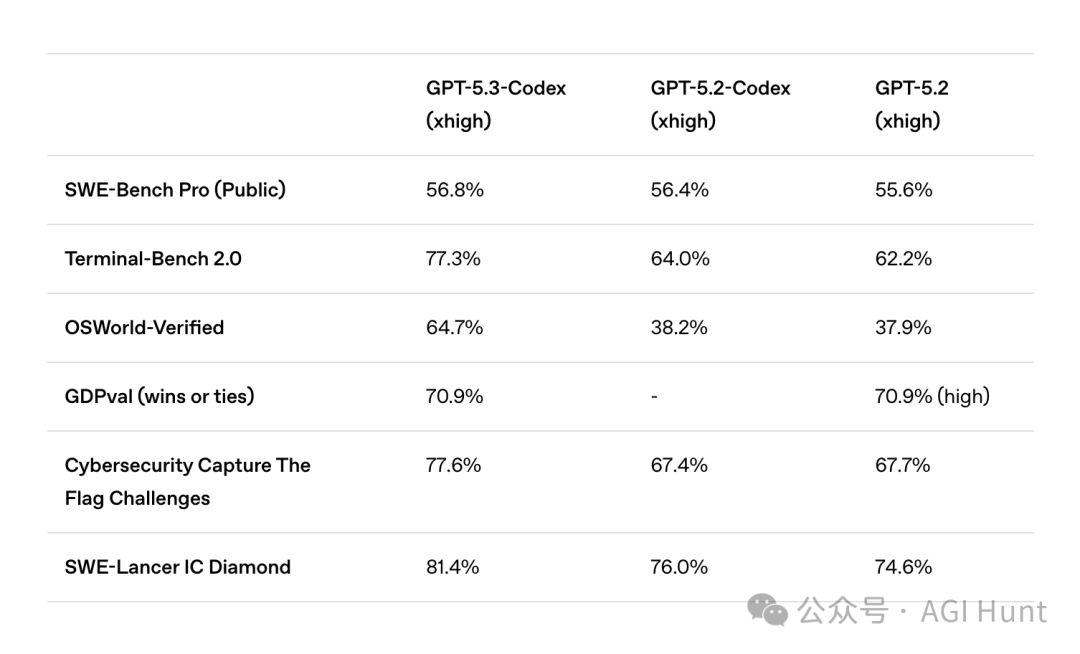
SWE-Bench Pro 达到了 56.8%。这是一个评估真实世界软件工程能力的严格测试,与仅测试 Python 的 SWE-Bench Verified 不同,它覆盖了四种编程语言,抗数据污染能力更强,更贴近工业场景。作为对比,GPT-5.2-Codex 的成绩是 56.4%,GPT-5.2 为 55.6%。
-
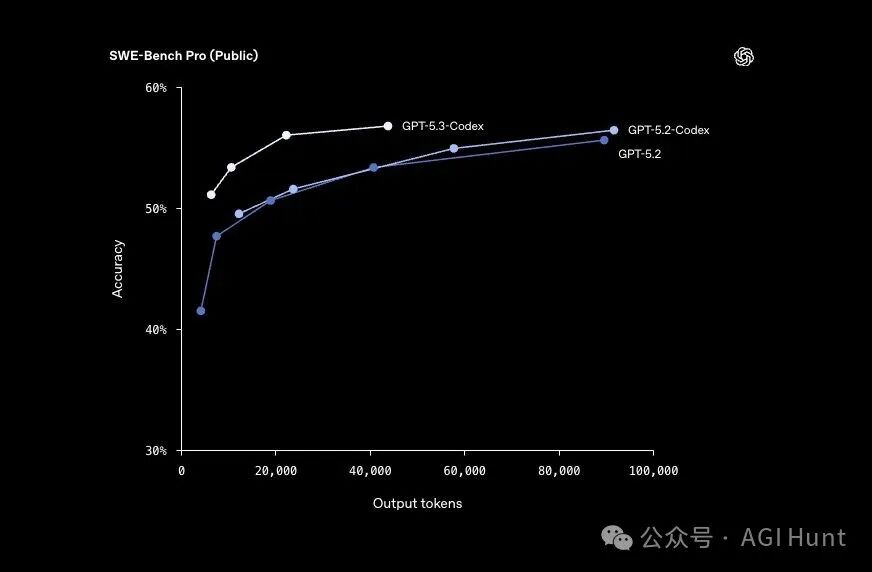
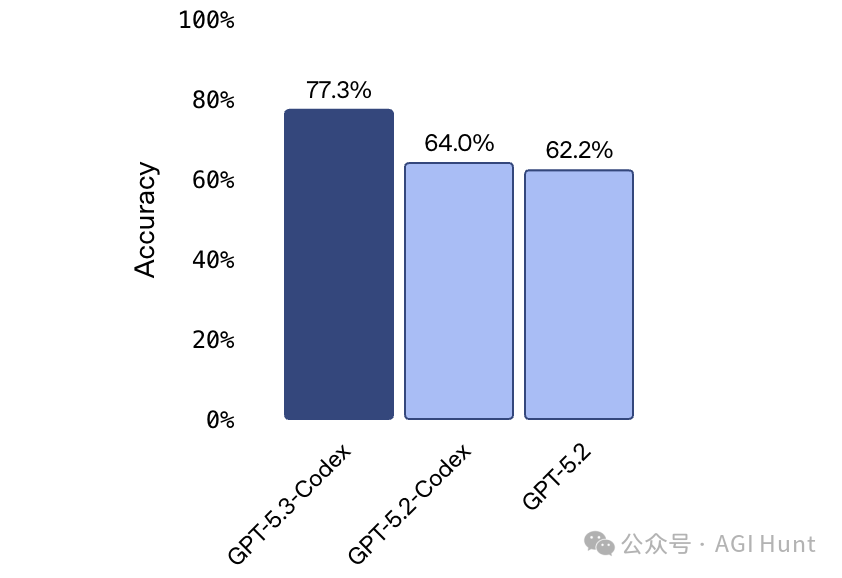
Terminal-Bench 2.0 得分 77.3%,远超 GPT-5.2-Codex 的 64.0%。该基准用于衡量编码智能体所需的终端操作能力。
-
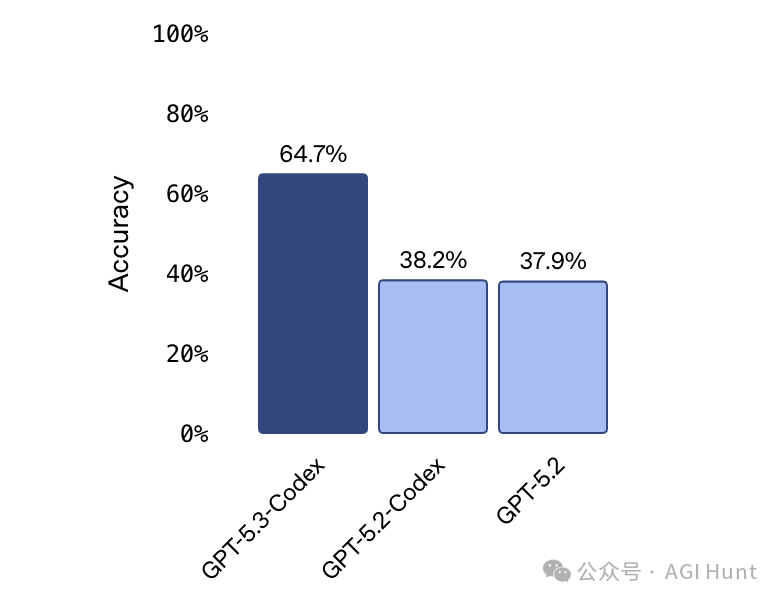
OSWorld-Verified 拿下 64.7%,而 GPT-5.2-Codex 仅为 38.2%。OSWorld 是一个在视觉化桌面环境中完成生产力任务的智能体计算机使用基准,这一提升幅度堪称显著。
-
GDPval 以 70.9% 的胜率或平局率与 GPT-5.2 持平。GDPval 是 OpenAI 在 2025 年发布的评估框架,用于衡量模型在 44 种职业的知识工作任务上的表现,包括制作演示文稿、处理电子表格等。
-
网络安全 CTF 挑战 达到 77.6%(GPT-5.2-Codex 为 67.4%)。
-
SWE-lancer IC Diamond 获得 81.4%,超过 GPT-5.2-Codex 的 76.0%。
值得注意的是,GPT-5.3-Codex 在实现这些性能提升的同时,完成任务所消耗的 Token 数量比以往任何模型都少。
能力扩展:超越代码生成的通用计算机协作者
GPT-5.3-Codex 的定位已经从一个代码生成工具,演变为一个更通用的计算机协作者。
OpenAI 表示,其目标已从“编写代码的智能体”,转变为“一个几乎能完成开发者和专业人士在电脑上所进行的一切工作的智能体”。
软件工程师、设计师、产品经理和数据科学家的日常工作远不止写代码。GPT-5.3-Codex 被设计为能够支持软件生命周期的所有环节:调试、部署、监控、编写产品需求文档、编辑文案、用户研究、测试、指标分析等。其智能体能力甚至超越了软件领域,可以协助制作幻灯片、分析电子表格数据。
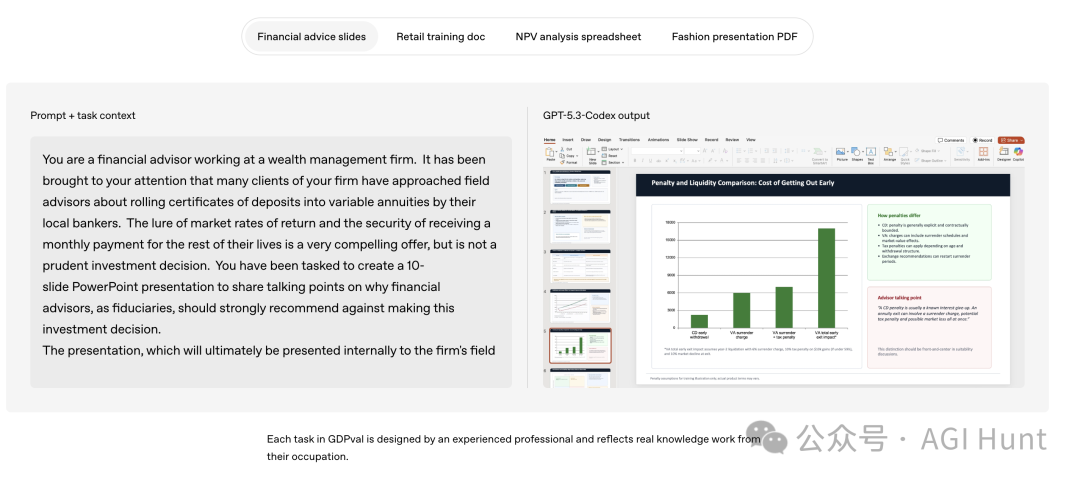
OpenAI 结合了前沿的编码能力、美学改进和压缩技术,打造出一个能够在数天内从零开始构建高度功能化、复杂游戏和应用的模型。为了测试其长时间运行的智能体能力,团队让 GPT-5.3-Codex 仅使用通用的跟进提示(如“修复这个 Bug”或“改进这个游戏”),就在数百万 Token 的交互中自主迭代,构建了两款游戏。
在网页开发方面,GPT-5.3-Codex 能更好地理解用户意图。对于简单或描述不够详细的提示,它会默认生成功能更完善、默认值更合理的网站,为用户实现想法提供一个更强大的起点。
交互进化:边工作边对话的协作模式
随着模型能力不断增强,人机交互的便捷性成为了新的焦点。GPT-5.3-Codex 引入了一个关键改进:交互式协作。
此前,用户给 Codex 下达任务后,通常需要等待最终结果。而现在,GPT-5.3-Codex 会在工作过程中频繁提供更新,让用户实时了解关键决策和进展。用户可以随时提问、讨论方案或调整方向,而不会丢失上下文。它更像是一位与你协作的同事,而非一台仅接受指令的机器。在 Codex 应用中,可以通过 Settings > General > Follow-up behavior 开启此功能。
安全与部署:高能力评级与广泛可用性
在安全方面,GPT-5.3-Codex 是 OpenAI 在 Preparedness Framework 下首个在网络安全相关任务上被评为“高能力”的模型,也是其首个直接训练用于识别软件漏洞的模型。
尽管没有证据表明它能自动化执行端到端的网络攻击,但 OpenAI 采取了预防性措施,部署了迄今为止最全面的网络安全防护体系。具体措施包括推出“Trusted Access for Cyber”试点项目以加速网络防御研究,扩大安全研究智能体 Aardvark 的私有测试,并与开源维护者合作为广泛使用的项目(如 Next.js)提供免费代码库扫描。此外,OpenAI 还承诺投入 1000 万美元的 API 额度,用于加速网络防御,特别是针对开源软件和关键基础设施系统。
在可用性上,GPT-5.3-Codex 现已向所有 ChatGPT 付费用户开放,覆盖 Codex 可用的所有平台:应用程序、CLI、IDE 扩展和网页端。API 访问正在稳步推进中。
性能方面,GPT-5.3-Codex 比 GPT-5.2-Codex 速度快了 25%,而完成相同任务所消耗的 Token 不到前代的一半。该模型是与 NVIDIA GB200 NVL72 系统协同设计、训练和部署的。
总结:从编码到通用计算协作的范式转变
OpenAI 在总结中指出,GPT-5.3-Codex 标志着 Codex 从“编写代码”转向了“使用代码作为工具来操作计算机、端到端地完成任务”。其最初目标是成为最好的编码智能体,如今已演变为一个更通用的计算机协作者,扩展了开发者和专业人士利用 Codex 所能构建和实现的边界。
本次发布也反映出模型迭代周期的显著缩短,以及行业竞争的加剧。一个更有趣的趋势是,像 GPT-5.3-Codex 这样的模型,已经开始利用AI生成的代码来加速自身的开发进程,这预示着未来 AI 发展的新范式。
对于技术社区而言,深入了解此类前沿模型的演进,是把握未来趋势的关键。你可以在 云栈社区 的 人工智能 板块找到更多关于 Transformer 架构和 Agent 应用的深度讨论,或者在 开源实战 板块探索如何利用 AI 工具参与实际项目。
相关链接:
 发表于 2026-2-7 11:40:17
|
查看: 232|
回复: 0
发表于 2026-2-7 11:40:17
|
查看: 232|
回复: 0
