近年来,多模态大语言模型在图像描述、视觉问答、视觉定位、多模态推理等任务中取得了显著突破,已成为人工智能领域的重要研究方向。然而,随着模型规模不断扩大、视觉输入分辨率持续提升,MLLMs 的训练成本急剧上升,成为制约其发展和应用的关键瓶颈。
传统的效率优化方法主要聚焦于模型压缩、参数高效微调和视觉编码器嫁接等方面,但往往忽视了另一个关键因素——视觉令牌数量。
在典型的多模态模型中,一张图像会被编码为数百甚至数千个视觉令牌,这些令牌与大语言模型中的自注意力机制相结合,产生了二次计算复杂度,导致训练过程极其耗时耗力。
一、MLLM 训练效率瓶颈与视觉令牌剪枝的潜力
1.1 多模态大语言模型的基本架构
多模态大语言模型通常由三个核心组件构成:
- 视觉编码器:将原始视觉输入(如图像、视频帧)转换为视觉令牌序列
- 多模态投影器:将视觉令牌映射到文本特征空间
- 大语言模型:统一处理视觉和文本令牌,执行跨模态理解和生成任务
以 LLaVA-1.5 为例,它采用 CLIP-ViT-L/14 作为视觉编码器,将一张 336×336 分辨率的图像转换为 576 个视觉令牌。而更高分辨率的模型如 LLaVA-NeXT,每张图像可产生多达 2880 个视觉令牌。这些视觉令牌与大语言模型的自注意力机制相结合,产生了 O(n²)的计算复杂度,其中 n 为令牌总数。
1.2 视觉令牌冗余性问题
研究表明,并非所有视觉令牌都对多模态理解至关重要。许多令牌对应于冗余或低信息区域,如:
这些冗余令牌不仅增加了计算负担,还可能引入噪声,影响模型的学习效率。视觉令牌剪枝技术正是基于这一洞察而发展起来的,它通过动态识别和删除冗余令牌,在推理阶段显著提升了效率。
1.3 训练-推理不匹配的挑战
尽管 VTP 在推理阶段表现出色,但将其直接应用于训练阶段却面临一个根本性挑战:训练-推理不匹配。具体来说,当模型在剪枝后的视觉序列上进行训练时,它难以在完整的、未经剪枝的视觉序列上进行有效推理。
这种不匹配可能源于多方面的差异:
- 序列长度差异:剪枝序列远短于完整序列
- 信息密度差异:剪枝序列的信息密度更高
- 空间结构差异:剪枝可能破坏原始的空间拓扑关系
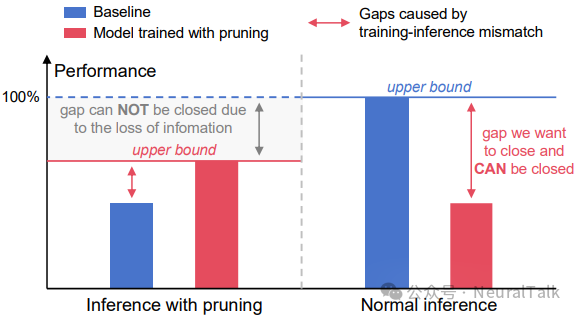
性能上界理论分析显示,剪枝推理的性能上限低于正常推理,因为剪枝导致视觉信息丢失。因此,接近 100%性能的可能路径是解决训练-推理不匹配问题。
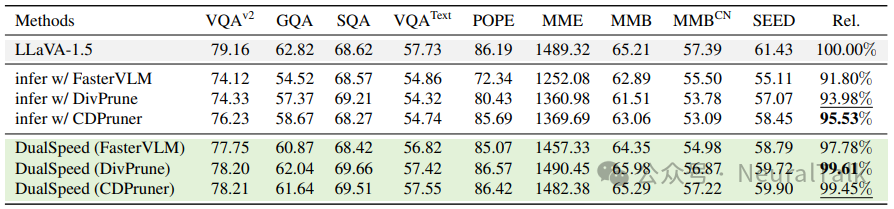
如表所示,当直接在训练中应用 VTP(NaivePrune)时,模型在正常推理(使用完整视觉序列)下的性能仅为基线的 95.89%,而在剪枝推理下性能为 97.85%。这表明训练-推理不匹配导致了显著的性能损失。
二、DualSpeed 框架:双速训练的创新设计
为了解决训练-推理不匹配问题,研究团队提出了 DualSpeed 框架,其核心思想是让模型在训练过程中同时学习处理剪枝序列和完整序列的能力。
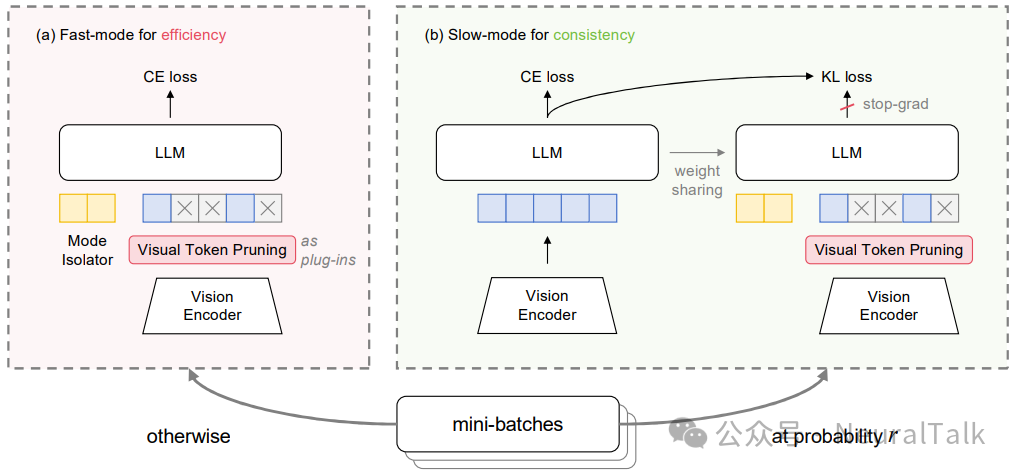
2.1 整体架构设计
DualSpeed 框架包含两种训练模式,在训练过程中随机切换:
- 快速模式(Fast-Mode):主要训练模式,使用剪枝后的视觉序列
- 慢速模式(Slow-Mode):辅助训练模式,使用完整的视觉序列
两种模式的切换遵循以下概率分布:
P(mode = slow) = r
P(mode = fast) = 1 - r
其中 r 为慢速模式的激活概率,通常设置为 10%。
2.2 快速模式:高效学习剪枝序列
2.2.1 视觉令牌剪枝
在快速模式中,首先对视觉令牌进行剪枝。给定剪枝比例 p,通过 VTP 方法获得剪枝后的视觉令牌序列:
V_fast = VTP(V, p)
其中 len(V_fast) = (1-p) * len(V),len(V_fast) 为剪枝后的视觉令牌序列长度,通常 len(V_fast) ≪ len(V),显著减少了视觉令牌数量。
2.2.2 模式隔离器
为了让模型能够区分处理剪枝序列和完整序列,DualSpeed 引入了模式隔离器,这是一个可学习的软提示(soft prompt):
M ∈ R^(l×d)
其中 l 为隔离器长度,通常设置为 4。在快速模式中,模式隔离器作为前缀与剪枝后的视觉序列连接:
X_fast = M ⊕ V_fast
其中 ⊕ 表示连接操作。模式隔离器的作用是明确提示大语言模型激活特定的感知模式来处理剪枝序列。
2.2.3 训练目标
快速模式采用原始交叉熵损失函数:
L_ce_fast = -Σ log P_θ(y_t | y_<t, X_fast)
其中P_θ表示模型 θ 预测的条件概率分布,y为文本令牌序列。
快速模式的训练目标为:
L_fast = L_ce_fast
2.3 慢速模式:保持训练-推理一致性
2.3.1 完整序列训练
慢速模式使用完整的、未经剪枝的视觉序列进行训练,确保模型学习处理完整输入的能力。这部分的训练目标同样基于交叉熵损失:L_ce_slow。
2.3.2 自蒸馏技术
由于快速模式占据了大部分训练时间(通常 90%的批次使用快速模式),慢速模式可能得不到充分训练。为了解决这一问题,DualSpeed 引入了自蒸馏技术:将充分训练的快速模式作为“教师”,指导慢速模式“学生”的学习。
蒸馏损失计算为教师和学生输出 logits 之间的 KL 散度:
L_kl = KL( softmax(z_teacher/τ) || softmax(z_student/τ) )
其中z_teacher和z_student分别是教师和学生的温度缩放 logits 分布,z表示大语言模型的 logits,τ 为蒸馏温度(通常设置为 1)。
2.3.3 慢速模式训练目标
慢速模式的最终训练目标是交叉熵损失和蒸馏损失的加权和:
L_slow = L_ce_slow + λ * L_kl
尽管教师模型(基于剪枝序列训练)的能力有限,但学生模型通过交叉熵损失可以学习完整视觉信息,最终超越教师模型的能力。
2.4 整体训练框架
DualSpeed 的整体训练目标由快速模式和慢速模式的损失加权组成:
L = Σ [ I(mode=fast) * L_fast + I(mode=slow) * L_slow ]
其中I(·)是指示函数,L_fast和L_slow分别由公式定义。
三、实验设计与结果分析
3.1 实验设置
研究团队在广泛使用的 LLaVA-1.5 和 LLaVA-NeXT 模型上验证了 DualSpeed 的有效性。实验设置严格遵循原始模型的训练配方,包括模型结构、训练数据、超参数等。
训练阶段划分:
- 预训练阶段:仅训练多模态投影器
- 监督微调阶段:训练多模态投影器和大语言模型
训练数据:
- 预训练阶段:LLaVA-Pretrain-558K 字幕数据集
- 监督微调阶段:LLaVA-665K 指令调优数据集
高效实验配置:在监督微调阶段使用 LoRA(Low-Rank Adaptation)进行参数高效微调,严格保持所有比较的公平性。
3.2 核心实验结果
3.2.1 训练加速与性能保持
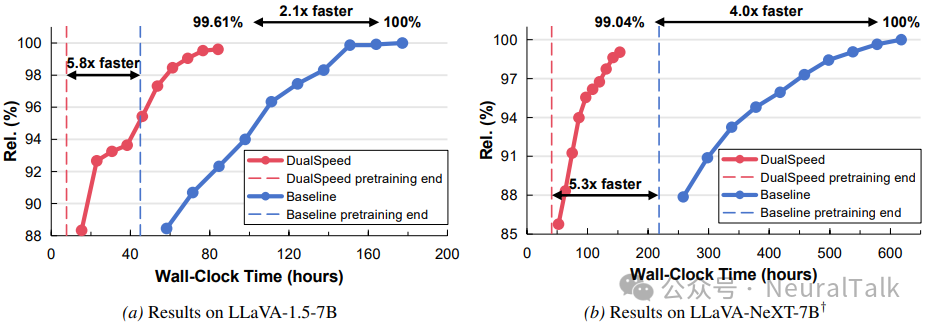
- 在 LLaVA-1.5-7B 模型上的实验结果显示,DualSpeed 实现了2.1 倍的整体训练加速,同时保持了99.61%的最终性能,如图 a 所示。特别值得注意的是,在预训练阶段,DualSpeed 实现了5.8 倍的加速,这远高于整体加速比。这主要是因为 LLaVA-1.5 的监督微调阶段中,视觉令牌所占比例较低(训练样本包含较长的文本查询和答案),从而降低了 VTP 对整体训练加速的贡献。
- 在更高分辨率的 LLaVA-NeXT-7B 模型上,DualSpeed 的表现更加出色,实现了4.0 倍的整体训练加速,如图 b 所示,同时保持了99.04%的最终性能,高分辨率模型有更大比例的视觉令牌,这放大了 VTP 带来的加速效果。
3.2.2 训练-推理差距的量化分析
研究团队比较了基线模型、NaivePrune 和 DualSpeed 在正常推理和剪枝推理设置下的性能。
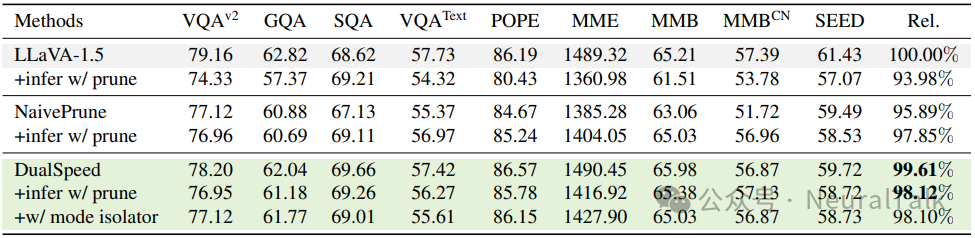
从上表可以看出,NaivePrune 在正常推理下性能显著低于基线(95.89% vs 100%),而在剪枝推理下性能相对较高(97.85%),因为此时训练和推理是一致的(都使用剪枝序列)。这暗示了剪枝训练模型在正常推理中性能不佳是由训练-推理不匹配引起的。
相比之下,DualSpeed 缓解了这种不匹配,与 NaivePrune 相比,在正常推理中带来了3.72%的性能提升。因此,DualSpeed 能够弥合的训练-推理差距约为 3.72%。通过弥合这一差距,DualSpeed 达到了与基线相当的性能(仅-0.39%)。
3.2.3 速度-性能权衡分析
DualSpeed 的训练加速取决于两个超参数:剪枝比例 p 和慢速模式激活概率 r。研究团队探索了不同 p 和 r 值下的速度-性能权衡。
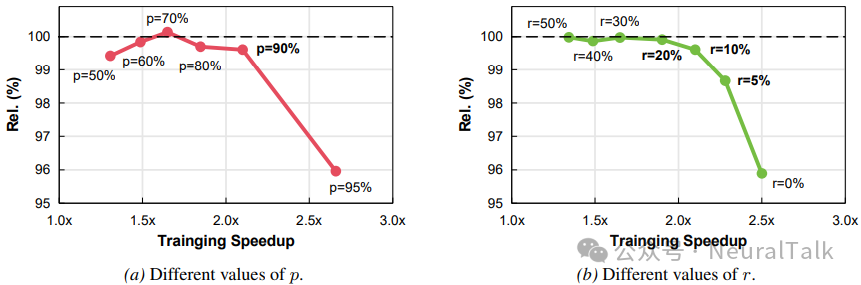
上图实验发现,随着剪枝比例 p 增加,训练速度持续提升,而模型性能几乎保持不变,直到 p 超过 90%这一极值。当 p 从 90%增加到 95%时,性能急剧下降超过 3%。这一发现表明:大约 90%的视觉令牌对于 MLLM 训练是冗余的。
类似地,当慢速模式激活概率 r 高于 20%时,性能不会下降,但当 r 超过 10%时,性能会急剧下降。当 p≈90%且 r≈10%时,权衡点位于帕累托前沿,在保持性能的同时实现了最大训练加速。
3.3 消融研究
研究团队通过逐步在 NaivePrune 基础上添加每个设计选择来创建不同变体,对 DualSpeed 的关键设计选择进行了消融研究。

消融研究有两个关键发现:
- 快-慢模式实现了优越的速度-性能权衡:快-慢模式设计将性能保持从 95.89%显著提高到 98.88%,代价仅仅是 0.3 倍的训练加速下降。
- 模式隔离器和自蒸馏带来进一步改进:模式隔离器将性能保持提高了 0.44%,自蒸馏进一步提高了 0.29%,两者对加速的影响均可忽略不计。
总之,DualSpeed 相对于基线 NaivePrune 的 95.89%实现了 3.72%的性能改进,达到了 99.61%的近乎无损性能。
3.4 在不同训练阶段应用 VTP
研究团队探索了在不同训练阶段应用 VTP 的效果。

当仅在预训练阶段应用 VTP 时,最终性能没有下降(100.12%对比原始的 100.00%),甚至略有提升。研究团队推测,VTP 消除了低贡献的视觉令牌,使投影器能够专注于学习关键视觉特征的映射。
然而,当在 SFT 阶段应用 VTP 时,性能下降与在两个阶段都应用 VTP 时相同(95.83%对比 95.89%)。这证实了训练-推理不匹配主要影响大语言模型的自注意力机制,而不是多模态投影器。
四、关键问题与技术深度解析
问题一:模式隔离器是根本解决方案还是行为掩盖?
模式隔离器确实是 DualSpeed 框架中的一个关键设计,其作用是通过一个可学习的软提示前缀,引导模型在处理修剪序列时激活一种特定的“快速感知模式”,而在处理完整序列时不使用该前缀,从而切换到另一种模式。从机制上看,这确实像是在模型外部添加了一个“开关信号”,而非让模型从内在表征层面统一理解两种输入。
然而,实验表明:在推理时若完全移除模式隔离器,模型在完整序列上的性能几乎不受影响(99.61%),而在修剪推理中性能仅轻微下降(从 98.12%降至 98.10%)。这说明:
- 模型确实学到了对完整序列的稳健理解,其能力不依赖于外部前缀;
- 模式隔离器在训练中更像一个“脚手架”,帮助模型区分两种输入分布,防止混淆,但其存在并非推理时的必要条件。
因此,DualSpeed 并未“掩盖”问题,而是通过结构化引导让模型在训练中同时学习两种模式,最终内化为统一的表征能力。去除隔离器后性能的保留,正是其成功解决训练-推理不匹配的实证。
问题二:DualSpeed 的普适性如何?
论文实验集中于 LLaVA 系列(基于 CLIP-ViT),虽验证了方法在图像模态上的有效性,但其在更广泛架构与动态任务中的普适性仍有待系统验证。
从原理上分析,DualSpeed 的核心思想——通过双模训练兼顾效率与一致性——具有架构无关性,但其具体实现(如修剪准则、隔离器设计)需根据视觉编码器的令牌特性与任务需求进行适配。未来需在更多架构(如 Video-LLaMA、InternVL)与动态任务上开展验证,以全面评估其普适性。
五、实验细节与复现指南
5.1 训练配方
研究团队严格遵循 LLaVA-1.5 的训练配方。

5.2 复现注意事项
对于希望复现或应用 DualSpeed 的研究者和实践者,以下注意事项可能有所帮助:
- VTP 方法选择:虽然论文默认使用 DivPrune,但实验表明 CDPruner 也表现良好。选择 VTP 方法时应考虑具体任务需求和计算约束。
- 超参数调优:剪枝比例 p 和慢速模式激活概率 r 是关键超参数。建议从 p=90%和 r=10%开始,根据具体任务进行调整。
- 硬件要求:实验在 NVIDIA L40 48G GPU 上进行,但 DualSpeed 的核心优势在于减少计算需求,因此在较低配置的硬件上也能实现显著加速。
- 与现有方法的结合:DualSpeed 可以与其他高效训练技术(如 LoRA、量化)结合使用,获得进一步的效率提升。
六、结论与展望
DualSpeed 框架通过创新的双速训练设计,成功解决了视觉令牌剪枝在训练阶段面临的训练-推理不匹配问题,为多模态大语言模型的高效训练提供了切实可行的解决方案。实验证明,该方法能够在保持模型性能几乎无损的情况下,实现显著的训练加速,为 MLLMs 的大规模训练和应用扫除了重要障碍。
核心贡献总结:
- 问题识别:首次系统性地识别并分析了视觉令牌剪枝在训练阶段面临的训练-推理不匹配问题。
- 创新框架:提出了 DualSpeed 双速训练框架,通过快-慢模式切换、模式隔离器和自蒸馏技术,实现了高效训练与性能保持的平衡。
- 实证验证:在多个模型和基准测试上验证了框架的有效性,实现了 2.1-4.0 倍的训练加速和超过 99%的性能保持。
- 深入分析:通过系统的消融研究和理论分析,深入揭示了训练-推理不匹配的根源和 DualSpeed 的工作机制。
该研究的代码已在GitHub开源,为社区提供了宝贵的实践参考。对于关注高效AI模型训练的开发者而言,这类在算法层面优化训练效率的工作,与硬件部署优化同样重要。如果你想了解更多前沿的AI模型训练与优化技术,可以到云栈社区与更多开发者交流探讨。
 发表于 2026-2-7 09:30:55
|
查看: 178|
回复: 0
发表于 2026-2-7 09:30:55
|
查看: 178|
回复: 0
