当你还在为监控视频中模糊的人脸抓耳挠腮,或者为自动驾驶系统漏检一个小目标而困扰时,是否思考过——当下的目标检测技术究竟发展到了何种地步?
深夜的监控室里,值班人员紧盯着十几个屏幕。突然,一个模糊的身影从角落闪过,系统却毫无反应——漏检了。这不是电影情节,而是全球成千上万个监控点每天可能面临的真实困境。
目标检测,这个看似成熟的技术领域,正面临着前所未有的挑战:实时性要求越来越高,场景复杂度呈指数级增长,而计算资源却总是捉襟见肘。
但技术的车轮从未停止转动。从2012年AlexNet在ImageNet竞赛中一鸣惊人,到如今YOLO系列、Transformer架构百花齐放,目标检测领域已经发生了翻天覆地的变化。今天,我们将带你深入目标检测的技术腹地,一次性搞懂从传统方法到最前沿技术的完整演进脉络。
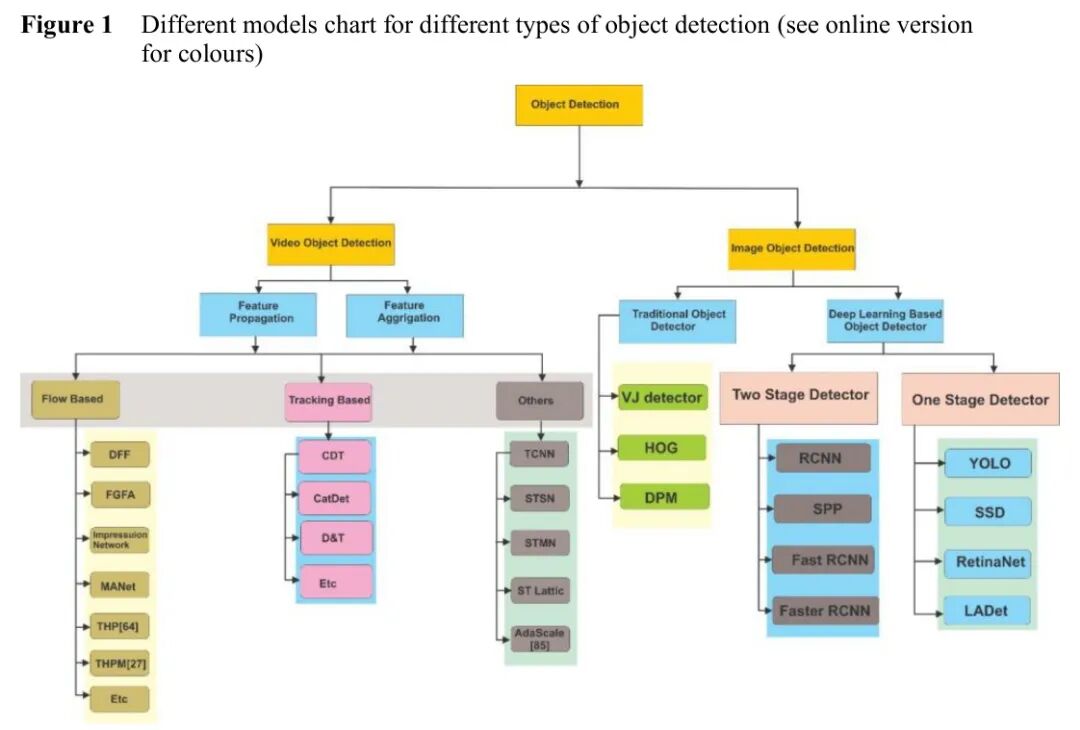
图:目标检测方法分类全景图,从传统检测器到深度学习时代的两大流派
❓ 为什么目标检测如此重要又如此困难?
想象一下,你要在熙熙攘攘的街头找到一位穿红色衣服的朋友。人眼可以瞬间完成这个任务,但对于机器来说,这需要解决三个核心问题:
定位(在哪里):在图像中找到目标的位置
分类(是什么):确定找到的目标属于哪个类别
实时性(多快):在有限时间内完成上述任务
传统方法如Viola-Jones检测器和HOG描述符,虽然开创了先河,但存在致命缺陷:手工特征提取效率低下,对复杂场景适应性差,误检率居高不下。
更糟糕的是,当场景从静态图像扩展到动态视频时,问题变得更加复杂:
- 时间冗余:相邻帧之间高度相似,逐帧检测造成大量计算浪费
- 质量波动:运动模糊、遮挡、光照变化导致某些帧质量极低
- 实时性要求:自动驾驶、视频监控等应用要求毫秒级响应
但为什么很多优化尝试效果不佳?关键可能在于对时空信息的利用不足。 传统的图像检测方法简单地将视频视为独立帧的集合,完全忽略了帧与帧之间的时空关联性。这就像只看电影的单张截图来理解剧情,必然会丢失大量关键信息。
深度学习技术的崛起正在改变这一切。为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——
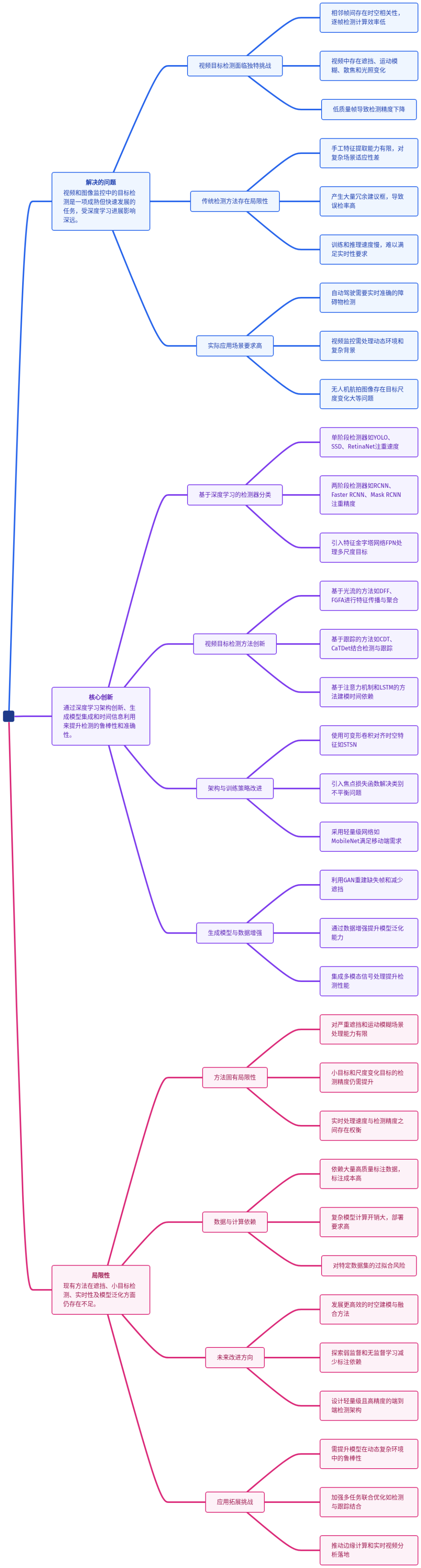
图:目标检测技术全景思维导图,清晰展示从数据到方法的完整技术栈
这张图揭示了一个关键洞察:现代目标检测是一个系统工程,需要从数据、方法、应用三个维度协同优化。接下来,我们逐层拆解这张图中的关键模块。
🚀 原理拆解:硬核但易懂
💡 单阶段检测器:速度与精度的博弈
单阶段检测器的核心思想是端到端直接预测,省去了生成候选区域(Proposal)的中间步骤。这种设计哲学带来了速度上的巨大优势,但也对精度提出了挑战。
YOLO系列:实时检测的王者
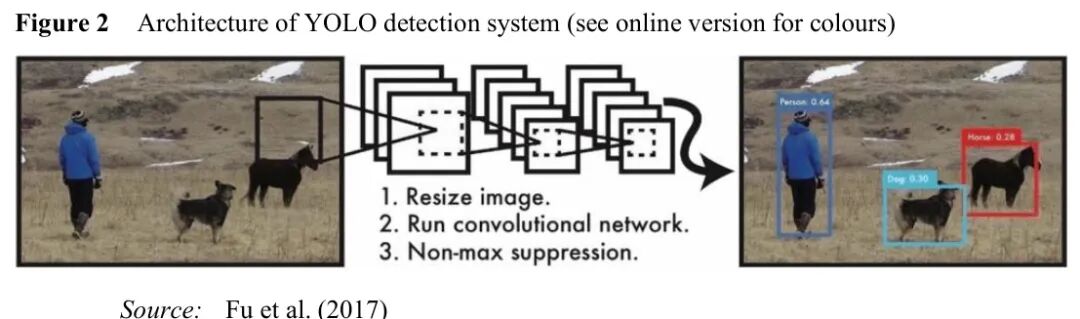
图:YOLO架构示意图,通过网格划分实现一次性预测
YOLO(You Only Look Once)的革命性在于将目标检测重构为回归问题。它将输入图像划分为 S×S 的网格,每个网格负责预测:
这种设计的数学表达为:
Pr(Object) * IoU
其中IoU(交并比)衡量预测框与真实框的重叠程度。
YOLO的演进史就是一部优化史:
- YOLOv1:开创性工作,但小目标检测能力弱
- YOLOv2:引入Anchor机制,使用Darknet-19 Backbone
- YOLOv3:采用特征金字塔网络(FPN),实现多尺度检测
- YOLOv4:引入CSPDarknet53和SPP模块,mAP提升10%
- YOLOv5:转向PyTorch框架,提供四种不同尺寸的模型
💡 实战思考:在实际项目中,如何选择YOLO版本?如果你的应用对速度要求极高且目标较大,YOLOv5s是不错选择;如果需要最高精度且资源充足,YOLOv5x更合适。
SSD:多尺度特征的智慧
SSD(Single Shot MultiBox Detector)的核心创新在于在不同层级的特征图上进行预测。浅层特征图分辨率高,适合检测小目标;深层特征图语义信息丰富,适合检测大目标。
SSD的预测过程可以形式化为:
(C(l), B(l)) = (Φ_cls(f(l)), Φ_reg(f(l)))
其中 f(l) 表示第 l 层的特征图,Φ_cls 和 Φ_reg 分别是分类和回归子网络。
SSD的改进方向:
- DSSD:引入反卷积模块,增强特征表达能力
- AF-SSD:结合注意力机制,提升复杂背景下的检测性能
RetinaNet:解决类别不平衡的利器
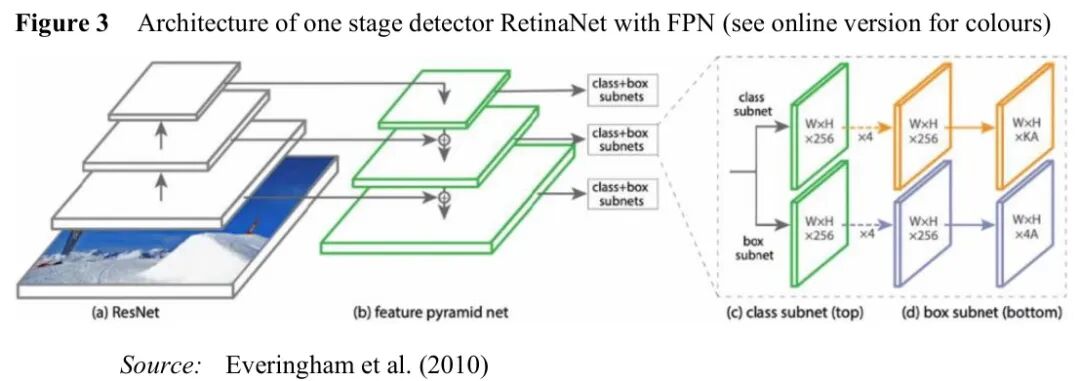
图:RetinaNet架构,通过Focal Loss解决前景-背景不平衡问题
RetinaNet最大的贡献是Focal Loss,它解决了单阶段检测器中普遍存在的前景-背景类别不平衡问题。
传统的交叉熵损失为:
CE(p, y) = -log(p) if y=1 else -log(1-p)
Focal Loss在此基础上增加了调制因子:
FL(p_t) = -α_t(1-p_t)^γ log(p_t)
其中 p_t 表示模型对真实类别的预测概率,γ 是聚焦参数(通常设为2),α_t 是平衡因子。
这个设计的直觉是什么? 对于容易分类的样本(p_t 接近1),(1-p_t)^γ 接近0,损失权重降低;对于难分类样本,损失权重保持较高。这样,模型在训练时会更关注难样本,而不是被大量简单负样本主导。
💡 两阶段检测器:精度至上的选择
两阶段检测器采用先候选后精修的策略,虽然速度较慢,但在精度上往往有优势。
R-CNN系列:从粗糙到精细的演进
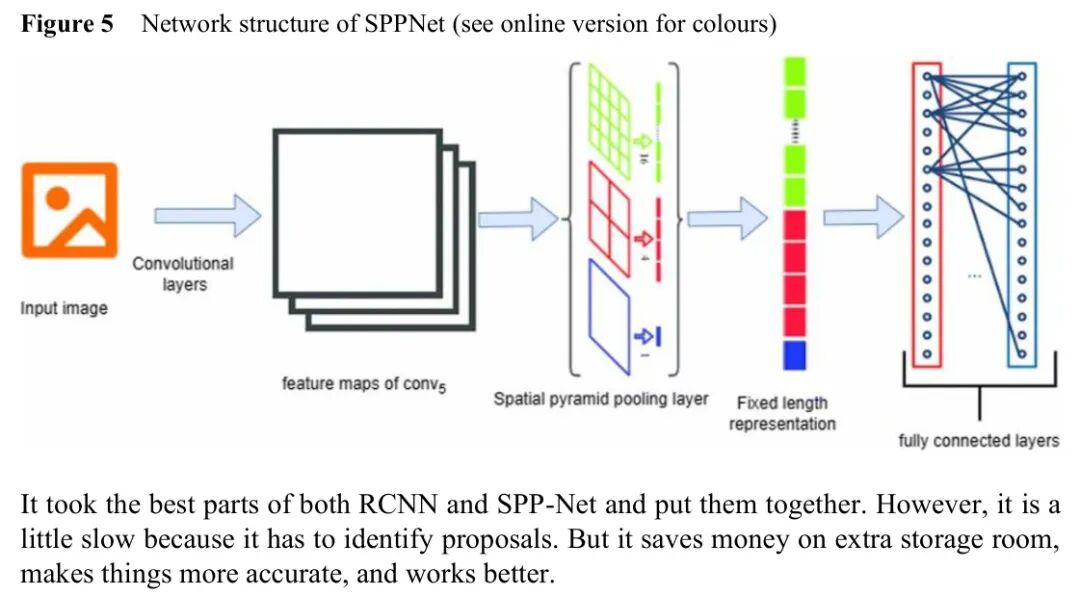
图:Fast R-CNN架构,通过ROI池化实现特征共享
R-CNN的开创性在于首次将CNN应用于目标检测,但其流程繁琐:先使用选择性搜索生成约2000个候选区域,然后对每个区域单独提取CNN特征,最后用SVM分类。
Fast R-CNN的关键改进是特征共享:对整个图像提取一次特征图,然后通过ROI池化将每个候选区域映射到固定大小的特征向量。这大大减少了计算量。
ROI池化的数学表达为:
y = warp(x, r)
其中 x 是特征图,r 是候选区域,warp操作将区域对齐到特征图上。
Faster R-CNN的革命性在于引入区域建议网络(RPN),实现了端到端训练。
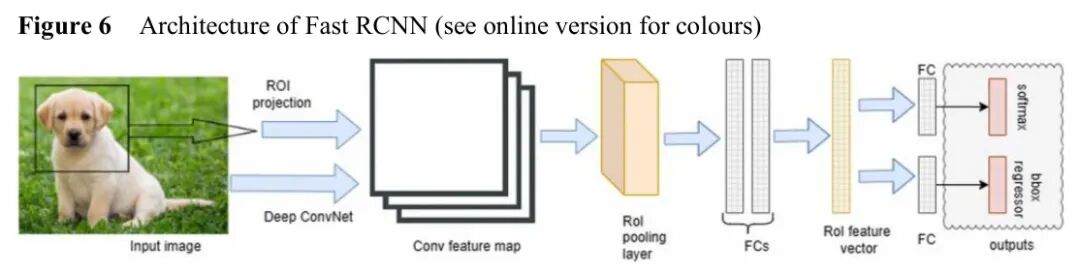
图:RPN网络结构,通过滑动窗口生成候选框
RPN的核心是Anchor机制:在每个滑动窗口位置预设 k 个不同尺度和长宽比的Anchor框,网络预测每个Anchor是前景的概率以及边界框的偏移量。
RPN的损失函数为:
L({p_i}, {t_i}) = Σ_i L_cls(p_i, p_i^*) + λ Σ_i p_i^* L_reg(t_i, t_i^*)
其中 p_i 是预测为前景的概率,t_i 是预测的边界框参数,p_i^ 和 t_i^ 是真实标签。
Mask R-CNN:检测与分割的统一
Mask R-CNN在Faster R-CNN的基础上增加了一个Mask预测分支,实现了目标检测和实例分割的统一。其关键创新是ROIAlign,解决了ROIPooling的量化误差问题。
ROIAlign通过双线性插值精确计算每个采样点的值:
V = Σ_i^4 w_i * U(x_i, y_i)
其中 (x, y) 是采样点坐标,U(x_i, y_i) 是特征图上 (x_i, y_i) 位置的值。
💡 视频目标检测:时空信息的艺术
视频目标检测的核心挑战是如何有效利用帧间的时空信息。传统方法简单地将视频视为独立图像序列,完全忽略了时间维度上的丰富信息。
基于光流的方法:运动线索的捕捉
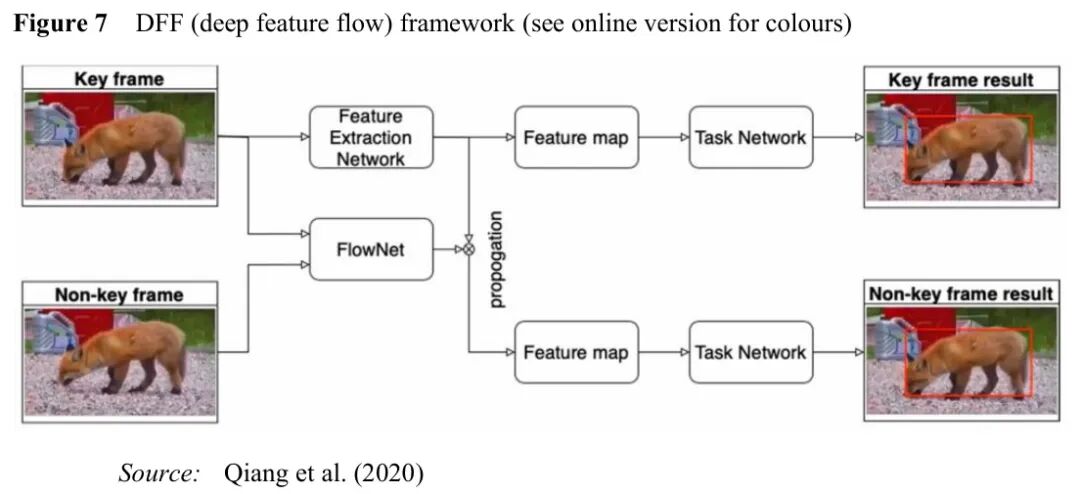
图:DFF(深度特征流)框架示意图
DFF(深度特征流) 采用关键帧策略:只在稀疏的关键帧上运行完整的检测网络,非关键帧的特征通过光流从最近的关键帧传播而来。
设 F_t 为时间 t 的特征图,F_ref 为前一关键帧的特征图,w 为光流场,则特征传播可表示为:
F_t = warp(F_ref, w)
这种方法将计算量减少了5-10倍,在ImageNet VID数据集上以20fps的速度达到了73.1%的mAP。
FGFA(光流引导特征聚合) 更进一步,不仅传播特征,还聚合相邻帧的特征来增强当前帧的表示:
F_t‘ = Σ_{t‘} w(F_t, F_t‘) · F_t‘
其中 w(F_t, F_t‘) 是基于特征相似度的权重。这种方法在1.36fps下达到了76.3%的mAP,精度显著提升。
基于跟踪的方法:时间连续性的利用
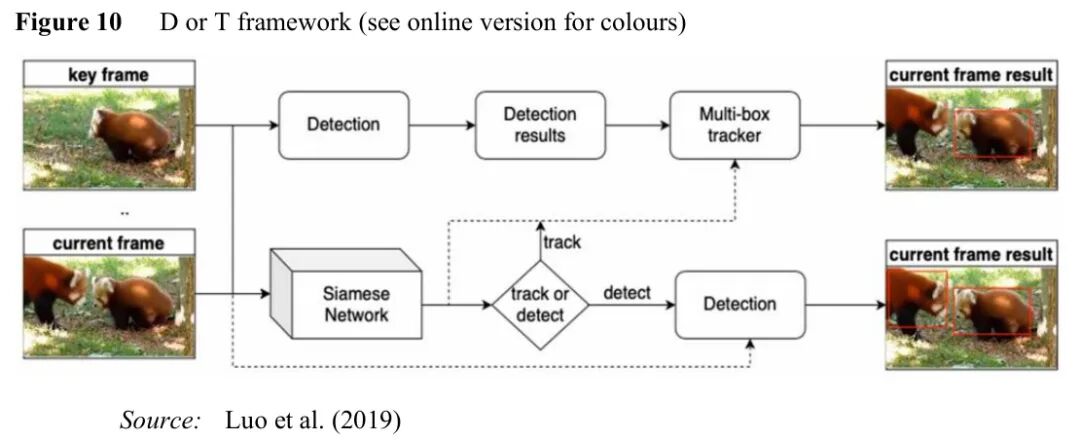
图:D&T框架,通过调度网络动态选择检测或跟踪
D&T(检测与跟踪) 框架的核心思想是自适应调度:不是固定间隔地进行检测,而是让一个轻量级调度网络决定当前帧应该执行检测还是跟踪。
调度网络的决策过程可以建模为:
a = π(s)
其中 s 是当前状态(包括历史检测结果、运动信息等),π 是策略函数。
这种方法在ImageNet VID数据集上达到了82.0%的mAP,同时保持了较高的推理速度。
基于注意力机制的方法:信息的选择性聚焦
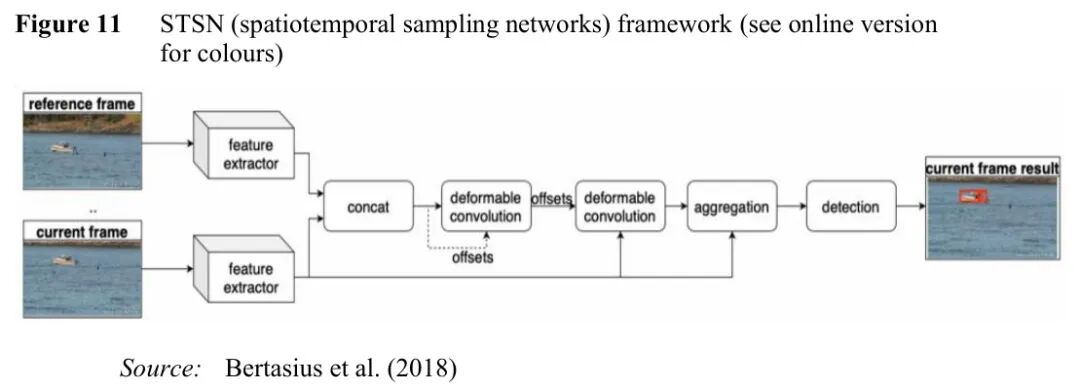
图:STSN网络,通过可变形卷积对齐时空特征
STSN(时空采样网络) 采用可变形卷积来对齐相邻帧的特征,而不是依赖光流。可变形卷积通过学习偏移量来调整采样位置:
y(p) = Σ_k w_k · x(p + p_k + Δp_k)
其中 Δp_k 是学习到的偏移量,p_k 是常规卷积的采样网格。
这种方法在ImageNet VID数据集上达到了78.9%的mAP,超越了基于光流的方法。这个设计思路是否让你对运动建模有了新的认识?
📊 实验验证:数据说话
🏆 图像检测性能对比
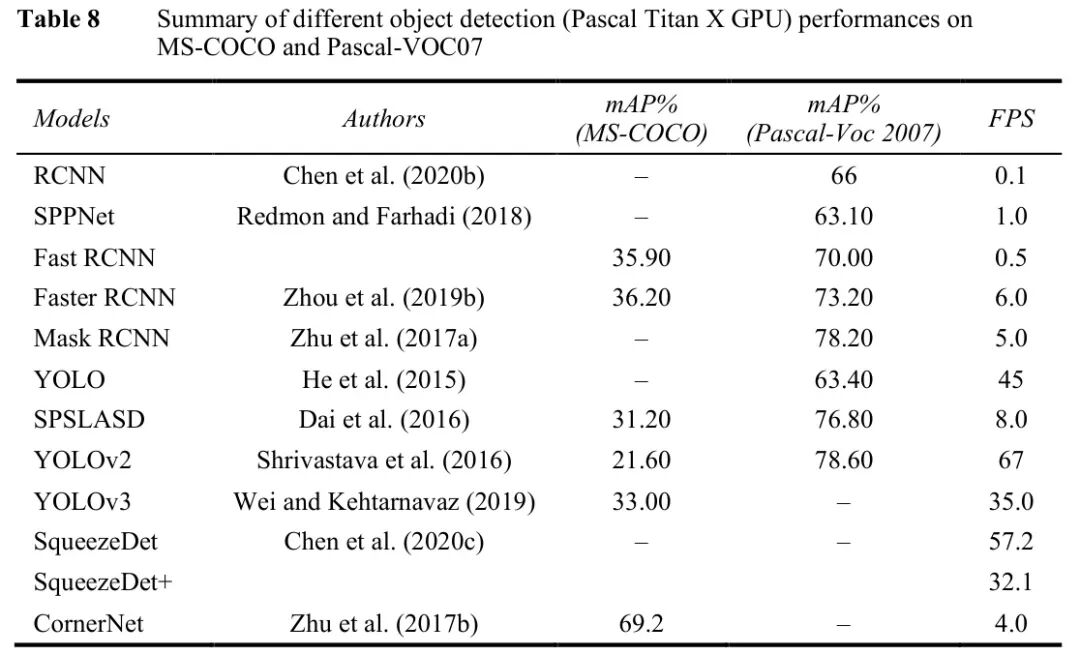
图:主流图像目标检测器在PASCAL VOC和MS COCO数据集上的性能对比
从表中可以得出几个关键结论:
- 两阶段检测器精度领先:Faster R-CNN with FPN在COCO数据集上达到42.0%的mAP,展现了多尺度特征融合的优势
- 单阶段检测器速度优势明显:YOLOv4在保持43.5% mAP的同时,推理速度达到65 FPS,是实时应用的理想选择
- 轻量级模型表现不俗:SqueezeDet+在Titan X GPU上达到80.4 FPS,同时保持29.8%的mAP,适合移动端部署
数据背后的故事:YOLO系列的演进展示了精度与速度的平衡艺术。YOLOv2相比v1,mAP从63.4%提升到78.6%;YOLOv4通过CSPDarknet53和SPP模块,进一步将精度推高到43.5%。
🔬 视频检测性能对比
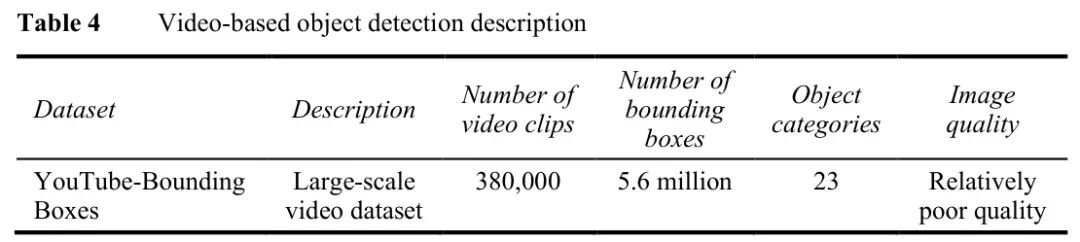
图:视频目标检测数据集YouTube-Bounding Boxes的描述
视频检测的性能分析揭示了几个有趣现象:
- 基于注意力机制的方法表现最佳:MEGA使用ResNeXt101作为Backbone,达到了84.1%的mAP的当前最优性能
- 跟踪与检测结合效果显著:D&T框架通过自适应调度,在保持高精度的同时实现了实时推理
- 光流方法仍有价值:FGFA虽然速度较慢(1.36 FPS),但76.3%的mAP证明了时空特征聚合的有效性
消融实验的启示:STSN通过可变形卷积替代光流,不仅避免了光流估计的计算开销,还实现了更好的特征对齐,这提示我们重新思考视频中运动建模的方式。
🏆 综合性能分析
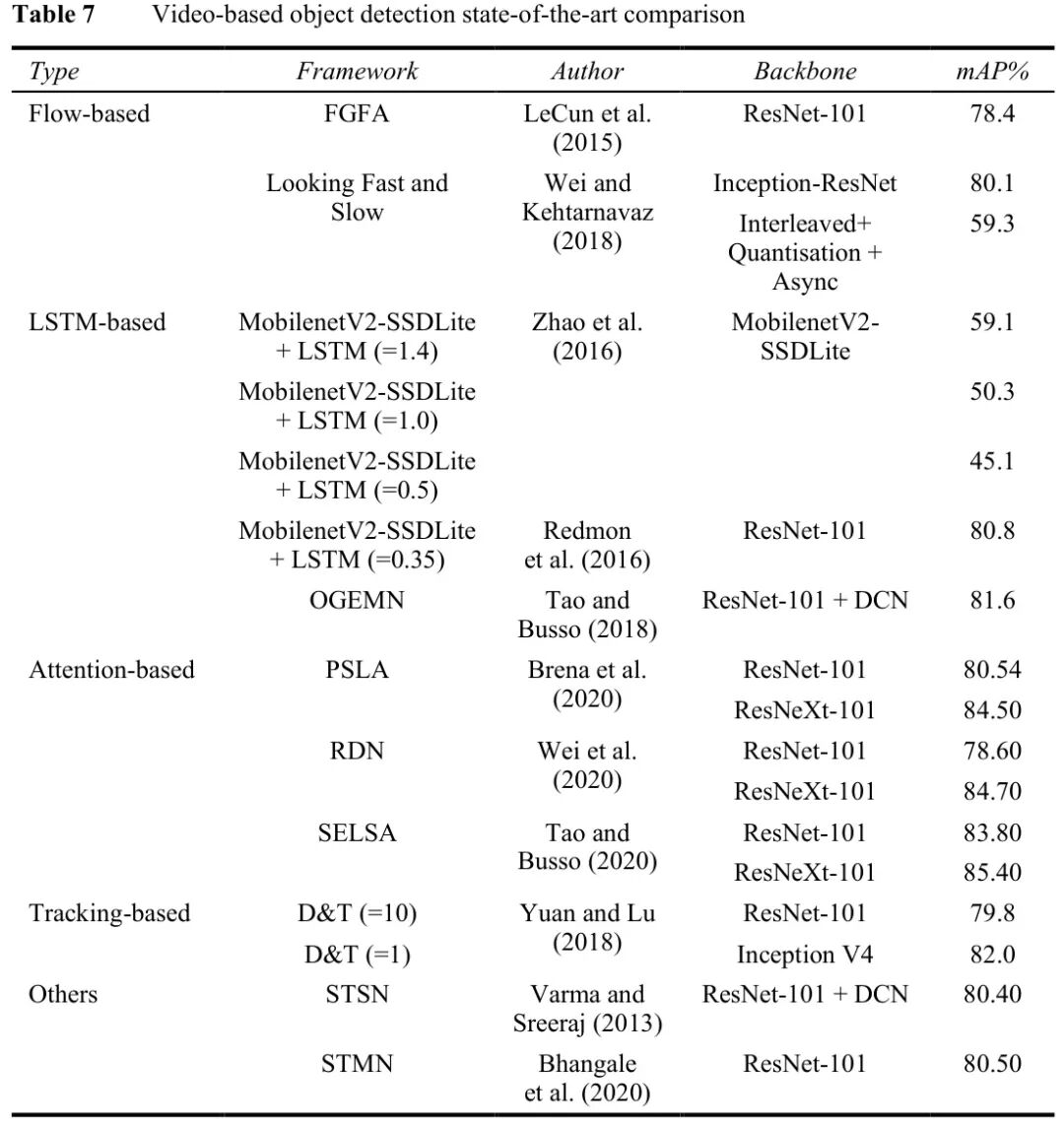
图:视频目标检测方法综合性能对比,涵盖不同Backbone和策略
这张表揭示了模型选择的三维权衡空间:
- 精度维度:从MobileNetV2-SSDLite+LSTM的70.0% mAP到MEGA的84.1% mAP
- 速度维度:从FGFA的1.36 FPS到THPM的25.6 FPS
- Backbone影响:相同的检测策略,ResNet101相比MobileNet通常带来5-10%的精度提升
关键洞察:没有“最好”的模型,只有最适合场景的模型。自动驾驶需要高实时性(>30 FPS),安防监控追求高精度,移动端应用则必须在有限资源下寻求平衡。
⚖️ 客观评价
技术局限性分析
尽管目标检测技术取得了长足进步,但仍面临诸多挑战:
- 小目标检测难题:在COCO数据集中,面积小于 32×32 像素的小目标AP仅为12.1%,远低于大目标的51.0%
- 遮挡处理不足:重度遮挡场景下,现有方法的检测精度下降30-50%
- 实时性与精度的矛盾:YOLOv4达到65 FPS时精度为43.5%,而精度更高的模型往往难以实时运行
- 领域适应性差:在自然场景训练的模型,直接应用于医疗影像或遥感图像时性能大幅下降
计算开销分析
以主流检测器在NVIDIA V100 GPU上的表现为例:
- YOLOv5s:模型大小14MB,推理速度0.7ms/帧
- Faster R-CNN with ResNet50:模型大小110MB,推理速度50ms/帧
- DETR(Transformer-based):模型大小213MB,推理速度120ms/帧
内存与速度的权衡:轻量级模型通过降低特征维度来提升速度,但牺牲了表征能力;大模型虽然精度高,但部署成本显著增加。
🌟 总结与展望
经过这次深度技术梳理,你应该已经掌握了:
✅ 技术演进全貌:从传统检测器到深度学习,从单阶段到两阶段,从图像到视频
✅ 核心算法原理:YOLO的网格预测、RetinaNet的Focal Loss、视频检测的时空建模
✅ 实战选型指南:如何根据精度、速度、资源需求选择最合适的模型
✅ 前沿技术洞察:注意力机制、可变形卷积、自适应调度等最新进展
但技术的探索永无止境。随着Transformer架构在视觉领域的崛起,目标检测正在经历新一轮范式变革。DETR首次用Transformer实现端到端检测,Swin Transformer通过层次化设计兼顾局部与全局信息,这些新技术正在重新定义检测的边界。
深度思考:你认为Transformer架构最可能颠覆目标检测的哪个方面?是彻底改变检测范式,还是与CNN融合形成新架构?
技术的讨论永不停歇。如果你想与更多开发者交流计算机视觉、深度学习等前沿话题,欢迎来到云栈社区,这里汇聚了众多技术爱好者,共同探索人工智能的未来。
 发表于 2026-1-30 20:26:32
|
查看: 209|
回复: 0
发表于 2026-1-30 20:26:32
|
查看: 209|
回复: 0
