OCR 识别的痛点,技术开发者一定深有体会。规整的印刷体还好处理,一旦遇到复杂表格、专业公式、公章印章或手写内容,许多模型的表现就会大打折扣。
近期,智谱 AI 开源了一款名为 GLM-OCR 的轻量级多模态 OCR 模型,成为了解决这些痛点的新选择。它在 HuggingFace 上的月度下载量已突破 260 万,并在多项权威评测中取得了领先成绩,堪称中文 OCR 领域的一匹黑马。这款模型在识别精度、推理速度和部署便捷性上做到了很好的平衡,无论是企业级业务落地还是个人开发使用,适配度都很高。
模型的开源地址为:https://huggingface.co/zai-org/GLM-OCR
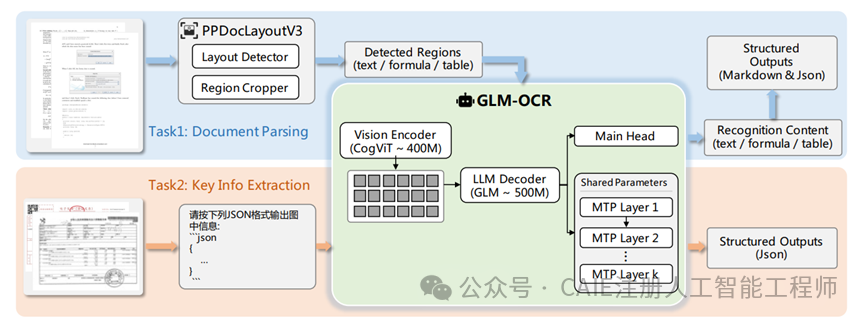
从核心架构来看,GLM-OCR 的设计思路清晰。它首先利用在海量图文数据上预训练的 CogViT 视觉编码器来提取图像特征,然后通过轻量级跨模态连接器无缝桥接视觉与语言信息,最后通过 GLM-0.5B 语言解码器将视觉信息转化为准确的文字。
同时,它还集成了 PP-DocLayout-V3 的两阶段处理流程:先进行布局分析,再对检测出的区域进行并行识别。这种设计能够清晰梳理各种复杂的文档排版,有效解决了传统 OCR 常见的识别混乱和漏识别问题。
GLM-OCR 之所以能在短时间内获得广泛关注,其核心竞争力主要体现在四个方面,每一个都精准击中了实际应用中的痛点。
首先,其性能达到了行业顶尖水平。在 OmniDocBenchV1.5 这一权威文档理解评测中,它获得了 94.62 的高分,稳居第一。在公式识别、表格识别、信息提取等主流评测中,也均处于第一梯队,表现超越了许多大厂的通用大模型的 OCR 能力。
其次,它专为真实业务场景进行了优化。实际工作中常见的复杂表格、代码密集型文档、带公章的正式文件等传统 OCR 的“重灾区”,恰恰是 GLM-OCR 的强项,即使在复杂布局下也能保持稳定的识别效果。
再者,它轻量高效且易于部署。整个模型参数量仅为 0.9B,与动辄几十上百 B 的大模型相比堪称轻量,却支持 vLLM、SGLang、Ollama 等多种部署方式。这能大幅降低推理延迟和计算成本,使其能够轻松应对高并发的企业服务场景或边缘设备部署需求。
最后,它做到了完全开源与易于上手。模型完全开放,并提供了配套的完整 SDK 和推理工具链。安装简单,一行命令即可调用,与现有生产流水线的整合也十分顺畅。技术团队无需投入大量时间进行二次开发,就能快速落地使用。
接下来,我们详细看看 GLM-OCR 在主流评测平台上的具体数据。
在文档解析方面,于 OmniDocBenchv1.5 测评中,它取得了 94.6 的分数,稳居专用视觉语言模型的第一位。
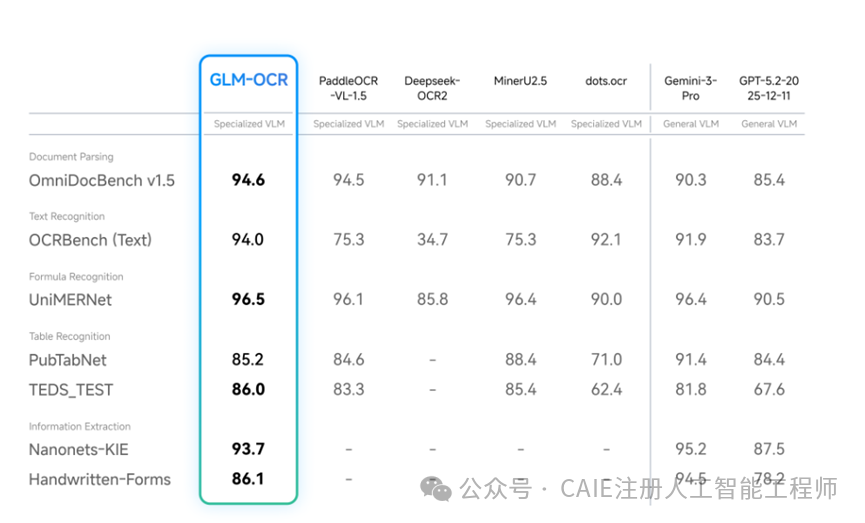
文本识别方面,在 OCRBench 测评中得分高达 94.0,远超同类模型。公式识别更是其强项,在 UniMERNet 测评中 96.5 的分数几乎触及行业天花板,复杂的学术公式也能精准识别。
表格识别虽然在标准测评 PubTabNet 中略逊于 MinerU2.5,但在更贴近真实场景的表格识别任务中,它拿下了 91.5 的高分,远超同类模型。这说明其优化方向更偏向于处理真实业务中远比测评集更复杂的表格。
针对真实业务中的高频场景,GLM-OCR 的表现同样出色:代码识别得分 84.7、印章识别 90.5、票据信息提取 94.5。可以看出,它的优化并非单纯为了刷高评测分数,而是真正适配了实际应用需求。
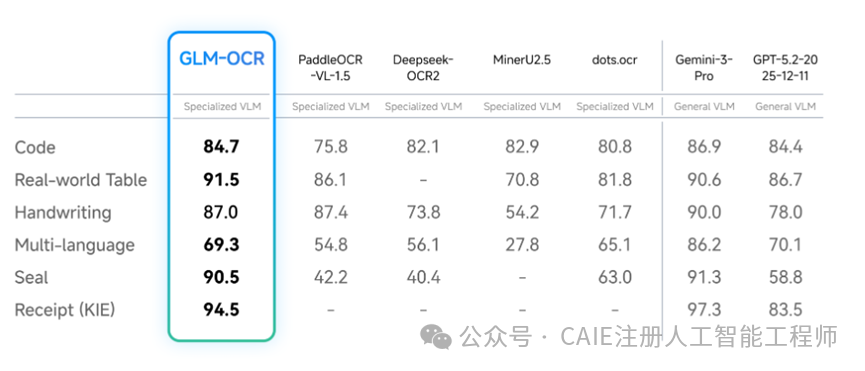
目前来看,其稍弱的环节是多语言识别,得分 69.3。虽然优于多数专用 OCR 模型,但与通用大模型相比仍有差距。不过,如果主打中英文识别场景,其能力已经完全够用。
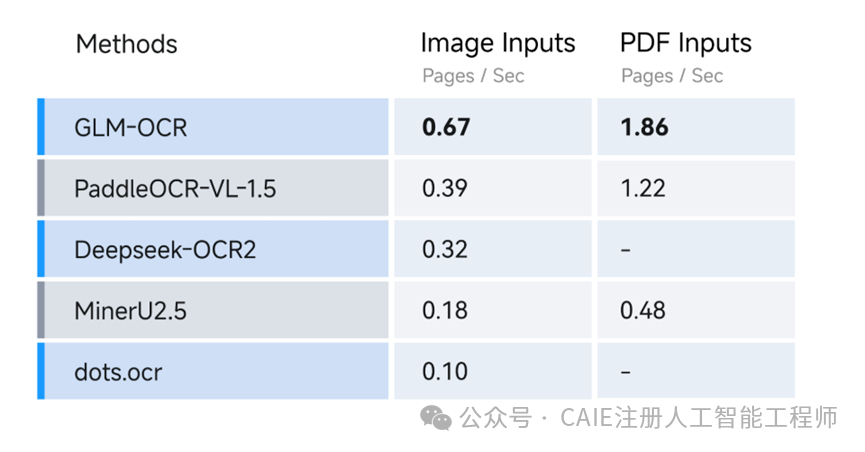
在推理速度上,GLM-OCR 的表现堪称碾压同级。解析图片生成 Markdown 格式时,每秒可处理 0.67 张图片;处理 PDF 文档时,每秒可处理 1.86 页。其图片处理速度比 PaddleOCR-VL-1.5 快近 70%,PDF 处理速度快 50% 以上。在进行大批量文档处理时,这将节省大量的时间成本。
使用 GLM-OCR 时有一个细节需要注意:它的提示词设计主要分为两种场景,正确使用能让识别效果更精准。
文档解析主要用于提取原始内容,支持文本、公式、表格三种类型。用户只需在提示词中指定对应的内容类型即可,方法简单直接。
信息提取则用于获取结构化信息。此时,需要严格按照 JSON 格式来编写提示词,明确定义需要提取的字段。模型会按照指定的格式返回结果,方便后续的数据处理。这一步的关键在于字段定义要清晰准确,以免影响后续的系统对接。
随着 AIGC 技术的快速发展,像 GLM-OCR 这样在垂直领域深耕的专用模型,正展现出巨大的实用价值。它不仅解决了实际业务中的具体难题,其轻量化与开源特性也极大降低了开发者的使用门槛。对于从事文档自动化、信息抽取等领域的开发者而言,这是一个非常值得关注和尝试的工具。更多关于前沿技术实践和开源项目的讨论,欢迎在 云栈社区 交流。
 发表于 2026-3-16 02:28:54
|
查看: 137|
回复: 0
发表于 2026-3-16 02:28:54
|
查看: 137|
回复: 0
