
Transformer的最大受益者,亲手给它判了“死刑”。
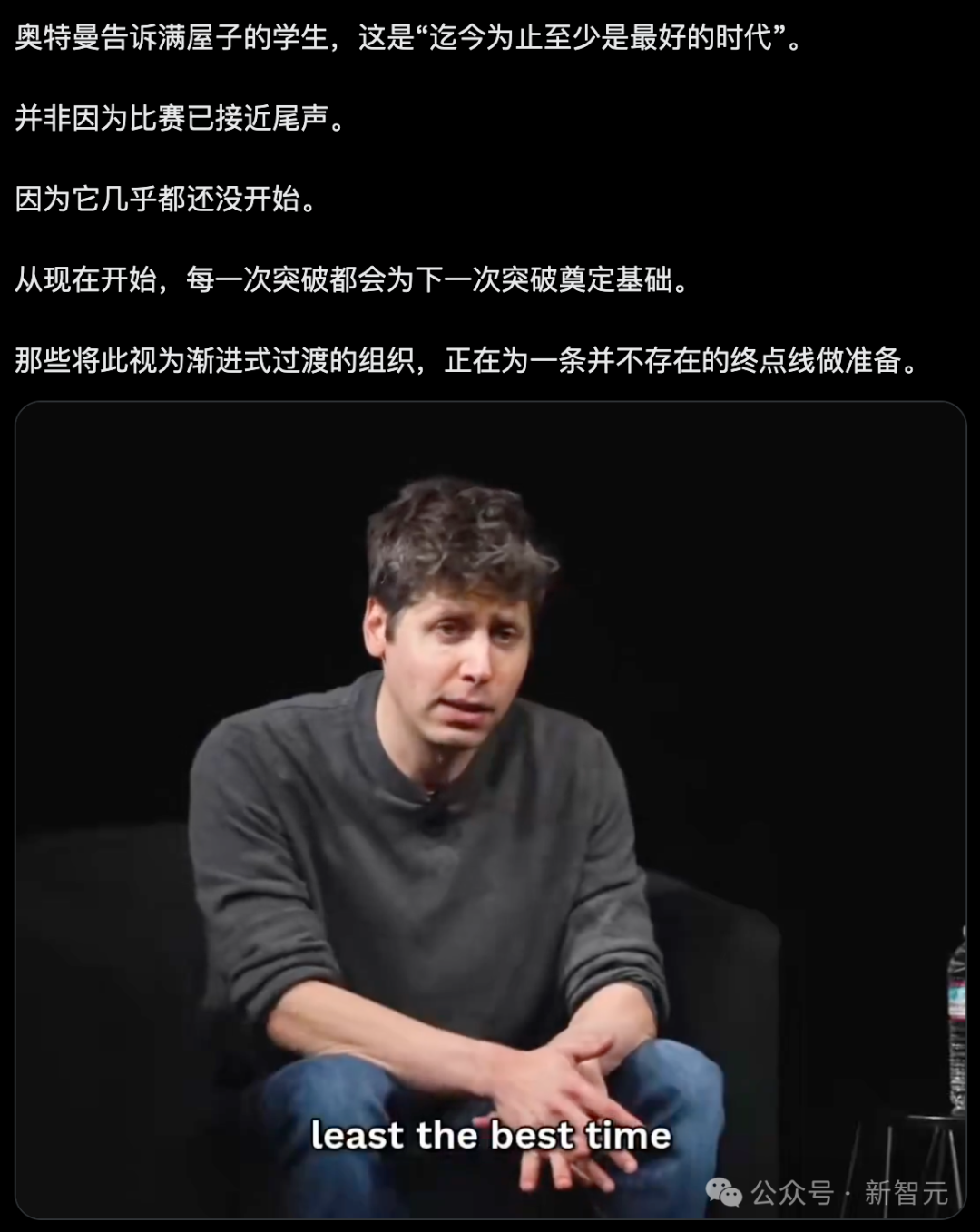
近日,OpenAI CEO Sam Altman回到母校斯坦福大学,在一场面向大二学生的访谈中,抛出了一个震撼业界的观点:未来一定会诞生全新的AI底层架构,其带来的性能跃升,将不亚于当年Transformer对LSTM的降维打击。
要知道,整个GPT帝国都建立在Transformer之上。ChatGPT、GPT-4、o1、Codex,无不是这套架构结出的果实。如今,这位摘果子的人却亲口预言:这棵大树的寿命可能快到头了。
Altman甚至直言不讳,我们所追求的通用人工智能(AGI)可能仅仅是一次“热身”(warm up)。而通往下一代全新架构的突破口,已经在路上——现有的高阶大语言模型已具备足够的认知能力,能够作为人类智力的杠杆,亲手推开另一扇技术范式的大门。
人们常说,暴力出奇迹,但暴力本身也有极限。Transformer架构存在一个天生的算力瓶颈:文本长度增加10倍,所需计算量可能增加100倍。这正是今天训练GPT-4级别模型需要耗费天价成本的原因之一。
Altman显然看到了这堵墙,但他认为,推翻这堵墙的工具已经握在手中。访谈中有一句关键的话:“现在的模型终于聪明到可以辅助人类去做这种级别的科研了。”
这意味着,寻找下一代AI架构这件事本身,已经可以让AI来参与和加速。逻辑链条非常清晰:模型越强 → 科研效率越高 → 新架构被发现的概率越大 → 新架构反过来让模型更强。一个自我加速的飞轮,正在形成。
Altman的这种判断,源于他对技术范式转换的敏锐嗅觉。他回忆道,2012年AlexNet横空出世时,他和多数人一样觉得“挺酷”,但并未完全意识到其颠覆性。直到深度学习模型规模不断膨胀,达到某个临界点后,他才猛然发觉——这东西就像一颗正在逼近的小行星,潜力巨大,但世界却鲜有警觉。
于是,OpenAI在2015年成立,核心信念就是:将深度学习的规模推向极致,看看会发生什么。尽管当时被许多前辈视为“疯狂”甚至“骗局”,但结果已众所周知。GPT-2让他第一次见到计算机做出了前所未有的事情,随后GPT-3、GPT-4接连惊艳世界。站在正确的范式上持续投入,回报是指数级的。
现在,同样的直觉被投射到了下一个范式上。Transformer不是终点,就像LSTM不是终点。他建议,如果现在是一名研究者,应该死磕这个方向,去寻找“能挖出核弹级突破”的地方,并且要重度依赖大模型作为科研助手。

Greg公寓里的白板:一个改变世界的夜晚
访谈中最生动的部分,是Altman对OpenAI草创时期的回忆。第一天上班,团队聚集在联合创始人Greg Brockman的公寓里。早上九、十点钟,八九个人陆续到达,坐在沙发上,面面相觑。
然后有人开口:“好吧,咱们干点啥?”有人提议写论文,又有人说得先弄块白板。于是他们当即在亚马逊下单,加急配送。Altman坦言当时内心一阵恐慌:这既不像正经的创业公司,也不像任何能成事的组织。
但他随即说了一句极具个人风格的话:在那种时刻,你只要深呼吸,相信如果身边聚集的都是最优秀的人,事情总会迎刃而解。他赌对了。
就在第一周,后来成为OpenAI前四年核心理念的大部分点子,都被写在了那块白板上,尽管当时他们自己都觉得这些想法“不靠谱”。他们最初根本没想过做产品,自认为只是一个纯粹的研发实验室。
但后来两件事变得越来越清晰:第一,这条路蕴含的经济价值远超想象;第二,实现目标所需的资金不是几十亿,而是数以千亿计。
真正让Altman建立起坚定信仰的转折点是GPT-2。他说记不清具体的发布日期,但永远记得第一次与那个模型对话的夜晚。“它做出了我以前从未见过计算机能做出的事情。”那一刻他确信,就是它了。

斯坦福访谈全景:奥特曼的十个关键判断
除了对架构的预言和创业往事,Altman在这场访谈中密集输出了大量观点,几乎每一条都值得深思。
- AGI两年内降临:他直接告诉台下的大二学生:“等你们毕业时,你们将踏入一个已经拥有AGI的世界。”人类的底层驱动力不会变,但科学研究将被高度自动化,创业和就业的意义将被彻底改写。
- 编程智能体是下一个“ChatGPT时刻”:下一个引爆点是什么?Altman毫不犹豫:编程AI智能体。紧随其后的是AI在所有知识型工作中执行任务的能力,而这一天已不远。
- “一人公司”将挑战中型企业:未来会出现大量由一人或少数几人组成的微型初创公司,其影响力和营收甚至能与今天的中大型企业媲美。他认为这比iPhone问世带来的机会更巨大。
- AI CEO?不是不可能:谈及AI的社会影响时,他说:“我绝不会自欺欺人地认为,在不远的未来不会出现一个比我更适合执掌OpenAI的AI CEO。”如果有的公司或国家全力拥抱AI而别人没有,竞争力差距将是碾压级的。
- 人类的适应力被严重低估:Altman并非末日论者。他认为AGI听起来颠覆,但身处其中的感觉不会那么惊悚。人类渴望创造、竞争和连接的内在驱动力不会消失,未来永远有事可做。
- 别怕与OpenAI竞争:当被问及OpenAI可能成为终极巨头时,他坦诚回应:当年所有人都说不可能与谷歌竞争,但OpenAI做到了。未来必然会有比OpenAI更成功的公司诞生,而且他们绝不会走一模一样的路。
- 烧钱快,但不慌:面对“OpenAI烧钱速度恐怖”的提问,他很淡定:如果今年投入100亿是为了明年赚300亿,全球有大把资本愿意做这笔买卖。
- 自研芯片是认真的,但不想自建数据中心:OpenAI有庞大的定制芯片计划,并对自家的推理芯片感到兴奋。但对于自建数据中心,他直言“真的一万个不想干这苦力活”,更倾向于将设计做到极致,合作完成。
- 社交产品将被底层重塑:AI的机会远不止给现有软件“塞个AI进去”。他举例,想象由AI智能体代表用户在虚拟空间自主交流、交换信息,这才是对社交产品底层逻辑的颠覆。
- 知道很容易,做到更难了:这是他博客首篇文章就写过的观点,他认为在AI时代这更成立了。获取知识越来越容易,但把事情做成的竞争也变得空前激烈。顶尖高手们发现,用好强大的AI工具以保持领先,比以往任何时候都更具挑战。
Altman的预言并非空中楼阁。“后Transformer”的竞赛早已打响,进展比许多人想象得更快。
最高调的挑战者是Mamba。Albert Gu和Tri Dao在2023年底提出的这一架构,彻底绕开了Transformer核心的“注意力机制”,转而采用状态空间模型(SSM)处理序列。简单来说,Transformer需要让序列中的每个词与其他所有词进行交互,而Mamba通过维护一个固定大小的记忆状态,在线性时间内完成计算,推理吞吐量据称可提升5倍。到2026年初,Mamba已演进至第三代。
产业界的动作更能说明趋势。英伟达在2025年发布的Nemotron-H系列模型中,用Mamba层替换了92%的注意力层,实现了推理速度3倍的提升,且精度不降反升。至2025年底,其全线新模型均已切换至Mamba-Transformer混合架构。此外,AI21 Labs的Jamba、IBM的Bamba、微软的Phi-4-mini-flash-reasoning等模型也纷纷加入混合架构的阵营。
还有更前沿的探索方向:Liquid AI公司开发的液态神经网络,灵感来源于仅拥有302个神经元的秀丽隐杆线虫。它使用微分方程驱动神经元,不仅能在推理时继续学习、实时适应环境变化,甚至能用极少的参数量(例如19个神经元)控制自动驾驶任务。其在2026年1月发布的LFM2.5模型,以远小于Transformer的参数量跑出了令人瞩目的性能。
回顾历史,从LSTM到Transformer的每一次架构级迁徙,都释放了数量级的能力增长,并催生了定义时代的公司。上一次迁徙,诞生了OpenAI。那么下一次呢?
Altman自己都说:总有一天会有比OpenAI更大更成功的公司出现。或许此刻,未来的创始人正坐在某个房间里,对着一块白板,写下第一个看似不靠谱的想法。而这一次,他手中多了一件前所未有的利器——AI本身。
这些前沿动态和深度思考,正是云栈社区的人工智能板块所持续关注和探讨的核心议题。从Transformer的演进到下一代架构的猜想,技术的每一次脉动都值得我们共同追踪与思辨。
参考资料:
 发表于 2026-3-17 03:24:13
|
查看: 361|
回复: 0
发表于 2026-3-17 03:24:13
|
查看: 361|
回复: 0
