
还记得在今年五一期间引发广泛讨论的 KAN 吗?这项由 MIT 团队提出的 Kolmogorov-Arnold Networks 因其独特的可解释性潜力吸引了大量关注。论文第一作者刘子鸣曾详细解读其能力与边界。就在北京时间 8 月 20 日,Max Tegmark 团队正式发布了其拓展工作——KAN 2.0,开源代码库也从 pykan 0.1 更新到了 0.2。这不仅仅是一次网络架构的升级,更标志着一种旨在深度整合 AI 与科学 的全新研究范式的提出。

论文题目: KAN 2.0: Kolmogorov-Arnold Networks Meet Science
论文地址: https://arxiv.org/abs/2408.10205
近年来,人工智能在蛋白质折叠预测、自动化定理证明等具有清晰目标的任务中取得了显著成就。在这些“应用驱动”的场景中,AI 通常作为一个高性能的黑箱优化器。然而,科学探索中还有大量“好奇心驱动”的部分——研究过程更多是探索性的,目标往往不那么明确,但所发现的基础知识却可能成为未来技术的基石。
好奇心和应用的驱动力,导致了截然不同的问题。以 AlphaFold 为例,尽管其预测准确率极高,但由于模型本身是黑箱,我们无从知晓它是否、以及究竟“发现”了哪些我们尚不知晓的蛋白质折叠规律。因此,KAN 2.0 的作者们呼吁,需要一种支持好奇心驱动科学的新型 AI 工具,它对交互性和可解释性有极高的要求。
初代 KAN 通过将高维函数分解为多个一维函数,并对这些函数进行符号回归,为实现可解释性提供了一种路径。但 KAN 2.0 的团队认为,这种将可解释性等同于“符号化表达”的定义可能过于狭隘。在化学、生物学等领域,复杂的现象未必总能或总需要用简洁的符号公式来描述;发现关键的特征和模块化的结构本身,可能就是足够的“解释”。
另一个关键问题是:我们能否将科学领域的先验知识注入到 KAN 中?科学发现常常依赖于领域知识,有时甚至在数据极少或没有数据的情况下也能进行。KAN 2.0 的目标之一,就是探索如何用 KAN 来表达这些先验知识,并结合数据,最终从 KAN 中提炼出新的科学见解。
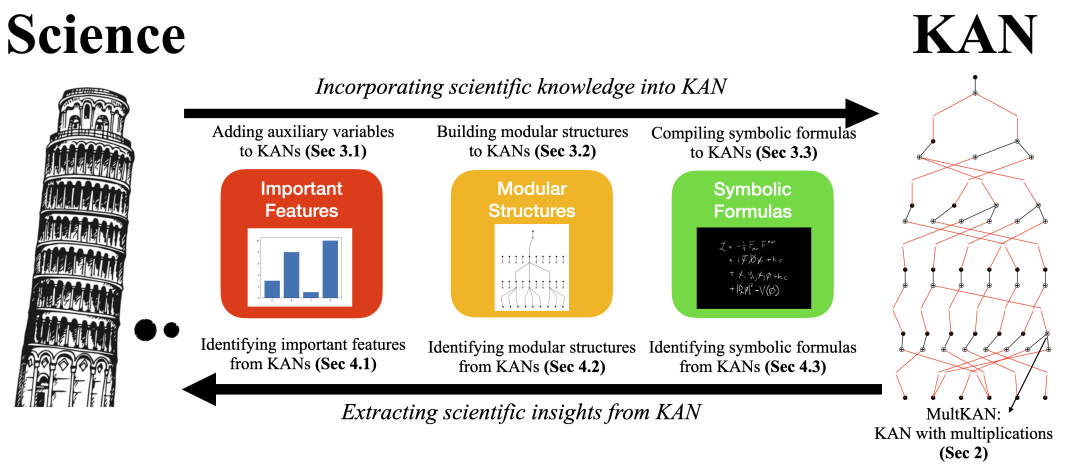
KAN 2.0 的整体研究思路如下图所示。其核心是在第二节提出了一个增强版的 KAN——MultKAN,它在原有架构中引入了乘法操作。由于乘法在科学定律中无处不在,加入乘法节点能使学习到的网络结构更加简洁。初代 KAN 可视为 MultKAN 的一个特例,在 KAN 2.0 的讨论中,“KAN”默认指代的就是 MultKAN。
在此基础之上,作者构建了一个双向框架:
- 从科学到 AI:在论文第三节,探讨了如何将三种科学知识注入 KAN,包括辅助变量(特征)、模块化结构和符号公式。
- 从 AI 到科学:在论文第四节,反向展示了如何从训练好的 KAN 中提取重要特征、识别模块化结构以及发现符号公式。
这一完整的双向循环,构成了 KAN 2.0 所倡导的“AI + Science”范式。
当前 AI 与科学结合的一个主要挑战在于范式冲突:主流 AI 基于连接主义,而传统科学依赖于符号主义。KAN 2.0 提出的框架,正是试图在两者之间架起一座桥梁。论文第五章通过一系列案例,展示了 KAN 在发现守恒量、函数对称性、拉格朗日量以及材料本构定律等具体科学问题上的应用潜力。
这项工作不仅升级了工具,更重要的是提出了一种可交互、可注入知识、可提取洞见的研究方法论。它试图让 AI 不再是科学发现过程中的黑箱“工人”,而是能够与科学家对话、接受指导并反馈理解的“伙伴”。对这项研究的 开源代码 和后续进展感兴趣的朋友,可以持续关注相关动态。关于人工智能与各科学领域交叉的更多深度讨论,也欢迎在云栈社区的技术板块进行交流。 |  发表于 2026-3-16 01:32:19
|
查看: 101|
回复: 0
发表于 2026-3-16 01:32:19
|
查看: 101|
回复: 0
