近期,Meta 团队在 arXiv 上发布了一篇关于广告推荐系统中长序列建模的重要论文《LLaTTE: Scaling Laws for Multi-Stage Sequence Modeling in Large-Scale Ads Recommendation》。该方法通过创新的离线-在线两阶段架构,在 Facebook Feed 和 Reels 的 A/B 测试中取得了转化率提升 4.3% 的显著效果。本文将为你解读其核心思想与关键实践发现。
论文地址:https://arxiv.org/pdf/2601.20083
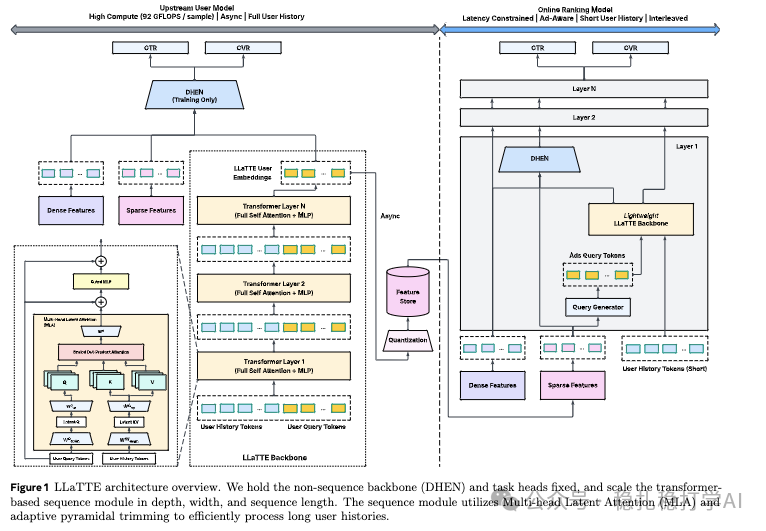
方法核心:两阶段 LLaTTE 架构
LLaTTE 的核心思想是采用“离线预计算 + 在线调用”的两阶段范式来处理超长用户行为序列。
离线 LLaTTE 模型负责处理完整的用户历史序列,生成高质量的用户兴趣表征(Embedding),并将其量化后缓存。在线 LLaTTE 模型则处于严格的延迟约束下,它接收包括离线预计算表征在内的多种特征,进行快速推理。
这种设计的巧妙之处在于,它将高计算成本的超长序列建模负担转移到了离线阶段,而在线阶段仅需进行轻量级的计算,从而在效果和效率之间取得了良好平衡。
1. 离线模型:全序列建模与表征缓存
离线模型的目标是学习一个通用的、与当前推荐目标(Target Item)无关的用户表征,以便能够缓存和复用。
- Token化:将用户历史行为中的每个 Item 转化为令牌(Token),使用的特征包括时间戳、类型、项目ID、业务类型和元数据等。同时,模型会构建一个查询(Query)序列,其元素来源于用户特征、上下文特征等,特意排除了与当前候选商品相关的特征。这种“非 Target-Aware”的设计是实现表征可缓存的关键。
- Transformer 层:为了提升效率,模型采用了源自 DeepSeek-V2 的多头潜在注意力(Multi-head Latent Attention, MLA)机制来代替标准的全注意力,后接门控 MLP。这样的层会堆叠多层。
- 表征生成与缓存:模型最终只保留处理后的查询令牌,将其展平拼接后,输入一个 LoRA MLP,得到固定维度的多个用户兴趣表征。这些表征与其他的稠密(Dense)、稀疏(Sparse)特征一同输入一个固定的非序列骨干网络(如 DHEN),最终输出 CTR、CVR 等预估目标。与此同时,生成的用户兴趣表征会被量化,并异步存储到缓存中。一个重要细节是:用户表征的更新触发时机是用户发生转化行为时,这保证了信息的时效性。
2. 在线模型:低延迟适配与高效推理
在线模型结构与离线模型相似,但为了满足极致的延迟要求,进行了多项优化:
- Query 序列包含 Target:与离线阶段不同,在线模型的 Query 序列可以包含当前候选商品的特征,实现更精准的 Target-Aware 交互。
- 金字塔式序列修剪(Pyramidal Trimming):受 OneTrans 启发,模型在 Transformer 层的不同深度,对键(Key)和值(Value)序列进行动态修剪,如同金字塔般自上而下逐步缩短序列长度,显著减少计算量。这与 OneTrans 主要修剪 Query 序列的策略有所不同。
- 受限的序列长度:为了控制延迟,在线模型处理的用户历史序列长度被限制在 400 以内。
下图清晰地展示了 LLaTTE 的整体架构设计:
关键发现与实践洞察
除了提出新方法,这篇论文更宝贵的价值在于分享了在大规模生产系统中探索长序列建模的“经验法则”,这些洞察对于后续的深度学习模型设计具有重要指导意义:
- 离线预计算模式可行:在 Meta 的超大规模广告推荐场景下,验证了“离线预计算用户表征 + 在线调用”这一工程模式的可行性和巨大潜力,为行业提供了可靠的实践路径。
- 序列长度是最高效的缩放杠杆:实验验证了模型性能提升的杠杆优先级:序列长度 > 模型深度 > 模型宽度。优先增加模型所能看到的历史长度,是性价比最高的选择。
- 语义特征是有效缩放的前提:论文明确指出,推荐系统的性能遵循可预测的幂律缩放规律,但实现有效缩放的前提是引入语义特征。如果序列中的 Item 只有 ID 而没有丰富的语义信息(如文本、图像特征),那么即使增大模型规模,也主要是在记忆模式而非学习泛化表征。加入语义特征后,模型缩放的性能增益斜率几乎翻倍。
- 模型宽度是深度的基础:研究发现,只有当模型宽度(隐藏层维度 d)达到一个基础阈值(如 d≥256)后,继续增加模型深度(层数)才会带来显著收益。否则,增加深度近乎是浪费算力。
这些发现直击了长序列建模中的核心挑战,解释了为何许多尝试效果不佳,而 Meta 的方案能取得成功,其关键在于同时利用了超长序列、足够深宽的网络模型以及丰富的语义特征。
总结
LLaTTE 的工作为我们展示了如何通过精巧的算法与系统设计,将Transformer 等强大模型应用于工业级推荐系统。其两阶段架构、基于 MLA 的高效注意力机制以及金字塔修剪等优化,为处理长序列问题提供了切实可行的方案。更重要的是,文中关于缩放定律、特征重要性等实证性洞察,为后续的研究与工程实践指明了方向。对于正在探索长序列建模或大规模推荐系统优化的团队而言,这篇论文无疑是一份极具参考价值的技术蓝图。更多关于前沿技术架构的讨论,欢迎访问 云栈社区 与广大开发者交流。 |  发表于 2026-1-31 02:25:26
|
查看: 305|
回复: 0
发表于 2026-1-31 02:25:26
|
查看: 305|
回复: 0
