LLM在推理任务上表现出色,但在需要多步骤、长上下文的精确计算任务中,表现往往不尽如人意。如何解决这一矛盾?
一个被卡帕西点赞的新思路是:在Transformer模型内部直接构建一台原生的计算机。这一方法不依赖任何外部工具,而是将可执行程序内嵌于Transformer的权重中,并凭借创新的2D注意力头设计,将推理效率提升至对数复杂度,在普通CPU上即可实现每秒超过3万Token的流式输出。

当前顶尖的Transformer模型虽然在解决复杂推理问题上游刃有余,但面对长序列的精确计算时,其自回归解码机制的短板就暴露无遗——每生成一个新Token,都需要对整个历史序列进行注意力计算,导致计算开销随序列长度线性增长,让长程精确计算变得效率低下。
常见的两种解决方案是工具调用和智能体调度,但这本质上都是给模型挂载“外挂”,将计算能力外包出去。Percepta团队的研究则另辟蹊径:直接让Transformer自己成为一台计算机。
他们的核心创新点在于,在Transformer的权重中实现了一套现代化的RAM计算机以及一个WebAssembly (WASM) 解释器。WASM是一种高效的底层虚拟机指令集,像C、C++这样的高级语言代码都能被编译成WASM字节码。
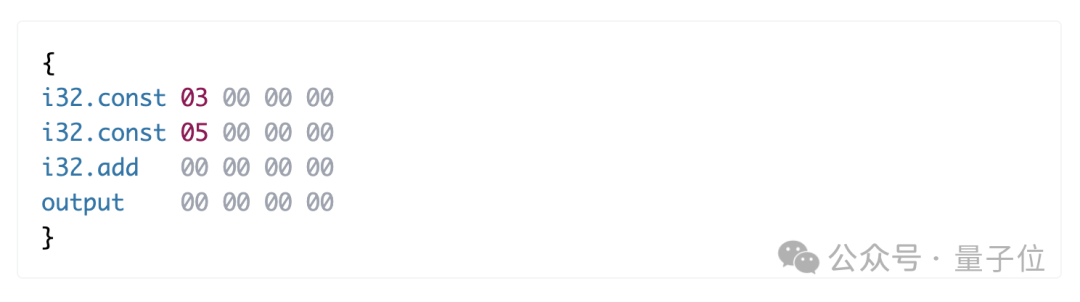
这意味着,任何标准化程序都能被编译成模型可识别和执行的Token指令序列。例如,当模型需要计算 3+5 时,它首先生成一段WASM字节码:
{i32.const 03 00 00 00
i32.const 05 00 00 00
i32.add 00 00 00 00
output 00 00 00 00 }
随后,模型切换到快速解码模式,在内部一步步执行这段程序,并将执行过程逐行输出为Token流:
03 00 00 00 commit(+1,sts=1,bt=0)
05 00 00 00 commit(+1,sts=1,bt=0)
08 00 00 00 commit(-1,sts=1,bt=0)
out(08)
halt

最终的计算结果会直接在模型的输出Token流中生成,无需等待外部工具的往返。整个过程完全透明,将计算从依赖外部工具的黑箱变成了可验证、可追溯的白盒过程。
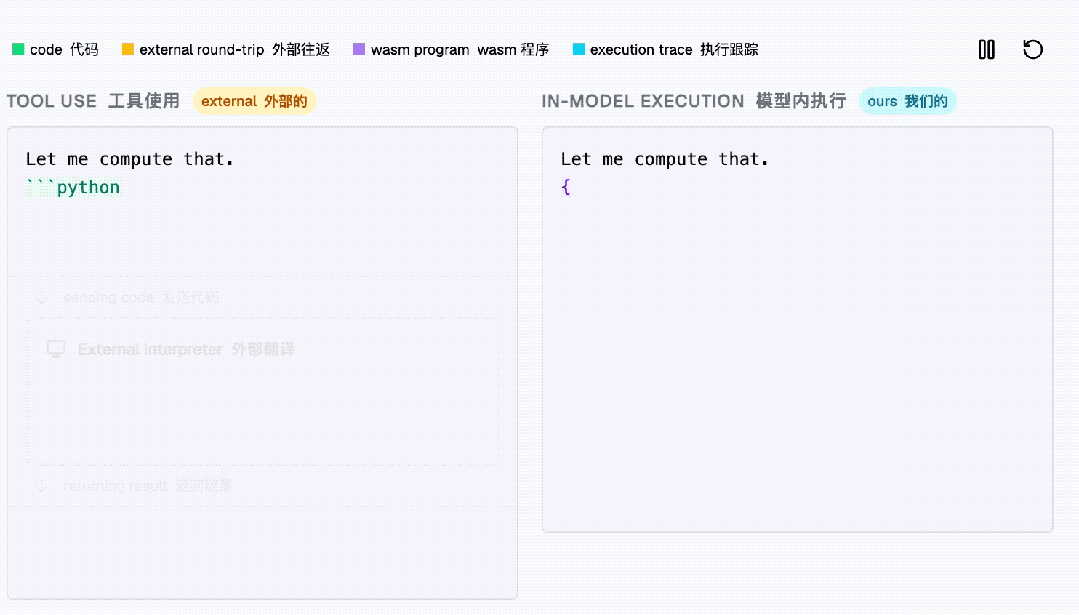
2D注意力头与HullKVCache:指数级效率提升
内置计算机解决了“能不能算”的问题,而如何高效地算则是另一个关键挑战。为此,研究团队对注意力机制进行了根本性的改造,设计了2维注意力头。
在2D注意力头中,每个历史Token的Key向量是二维的,当前Query向量则被视为二维平面上的一个方向。这样一来,“寻找与Query最匹配的Key”这一注意力核心问题,就被转化为了计算几何中的凸包极值查询——在由历史Key构成的二维凸包上,寻找沿Query方向最远的点。
基于此原理,模型可以在生成Token时动态维护历史Key的凸包结构。每一步的注意力查询都只需要在这个凸包上进行,从而将计算复杂度从传统的 O(n) 降低到了惊人的 O(log n)。

研究团队据此实现了 HullKVCache。该缓存在普通CPU上就实现了 31,037 Token/秒 的吞吐量,完成一段约9000行的指令序列仅需 1.3秒。相比之下,传统的KV缓存处理相同任务需要超过250秒,效率提升了近200倍。
更重要的是,HullKVCache完全基于标准的PyTorch Transformer架构实现,无需定制内核或复杂的稀疏掩码,仅需简单配置维度和注意力头数即可启用。
实战验证:求解世界最难数独与最小代价匹配
为了验证这套内置计算机系统的实际效能,研究团队选取了两个极具挑战性的长程精确计算任务。
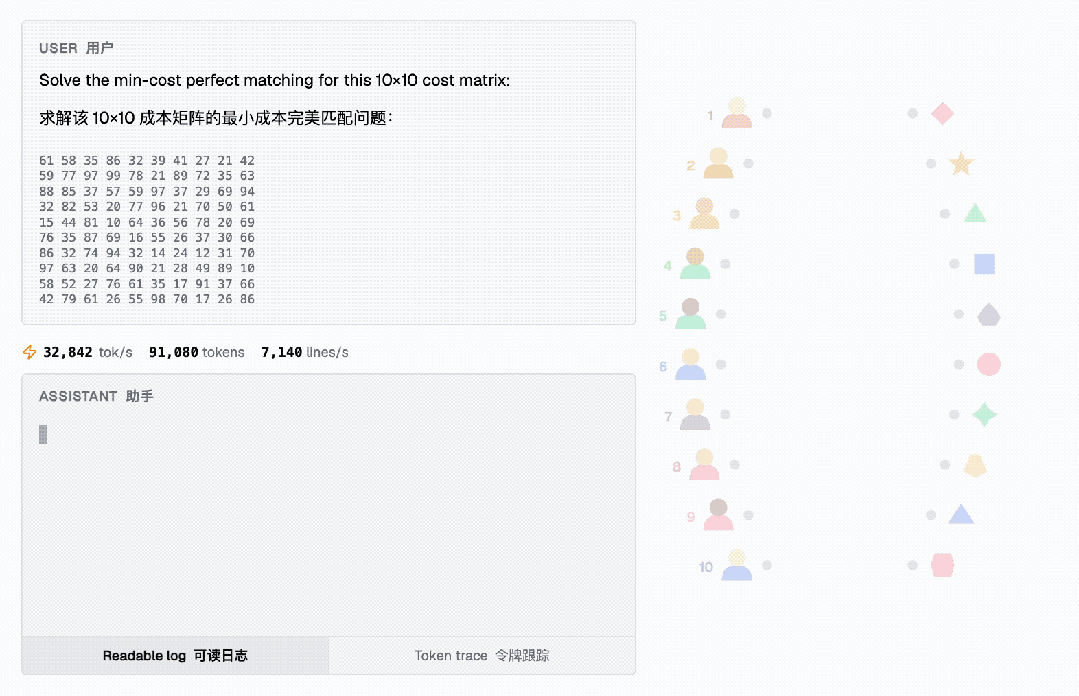
任务一:10x10最小代价完美匹配
模型在内部执行完整的匈牙利算法。它以自回归的方式生成计算轨迹,包括行分配、运行Dijkstra算法求最短增广路径、更新对偶变量等所有步骤。整个过程清晰可追溯,最终精准输出了最优匹配方案。该任务在CPU上达到了 33,583 Token/秒,7,301行/秒的指令输出效率。
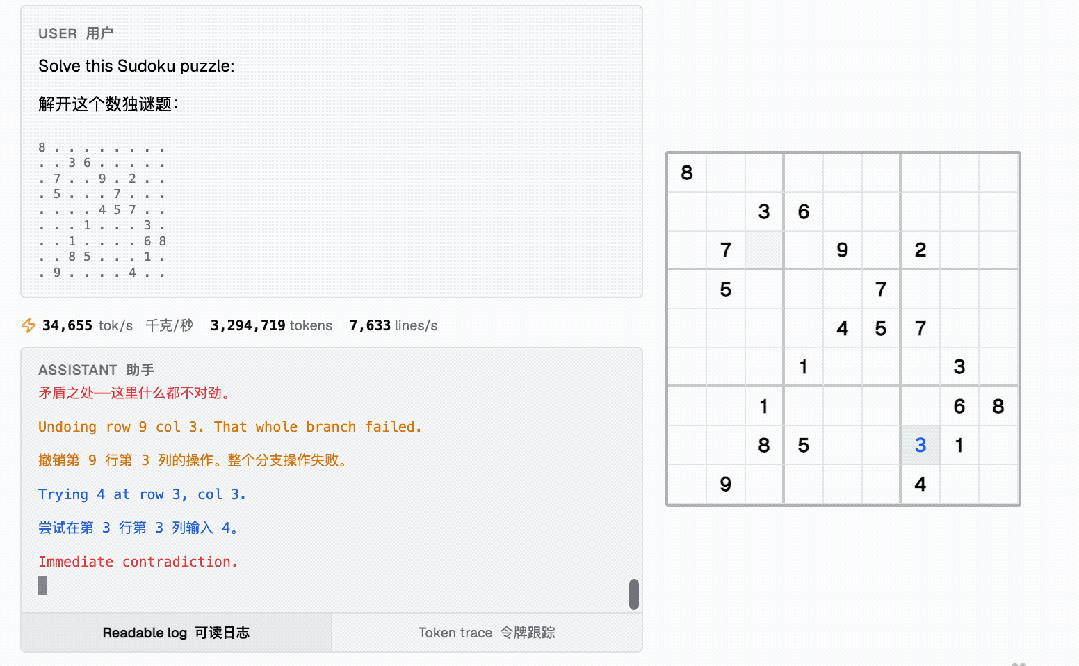
任务二:世界最难数独(Arto Inkala数独)
针对这个仅有21个提示数的“地狱级”数独,模型内部运行了一个完全正确的、编译后的数独求解器。求解器先进行约束传播,然后进入深度优先搜索与回溯阶段。每一次数字尝试、冲突检查、回溯撤销都以可读日志的形式自回归生成。最终,模型在约3分钟内实现了100%的精确求解,完美填满了整个数独盘面。
这项工作由雅典大学副教授、Percepta创始研究员Christos Tzamos领衔完成。它展示了一条让大模型获得强大、高效且透明计算能力的新路径,为人工智能解决更复杂的科学和工程问题打开了新的想象空间。对这项技术细节和未来应用感兴趣的开发者,欢迎在云栈社区的 人工智能 板块继续深入探讨。
 发表于 2026-3-18 09:02:23
|
查看: 102|
回复: 0
发表于 2026-3-18 09:02:23
|
查看: 102|
回复: 0
