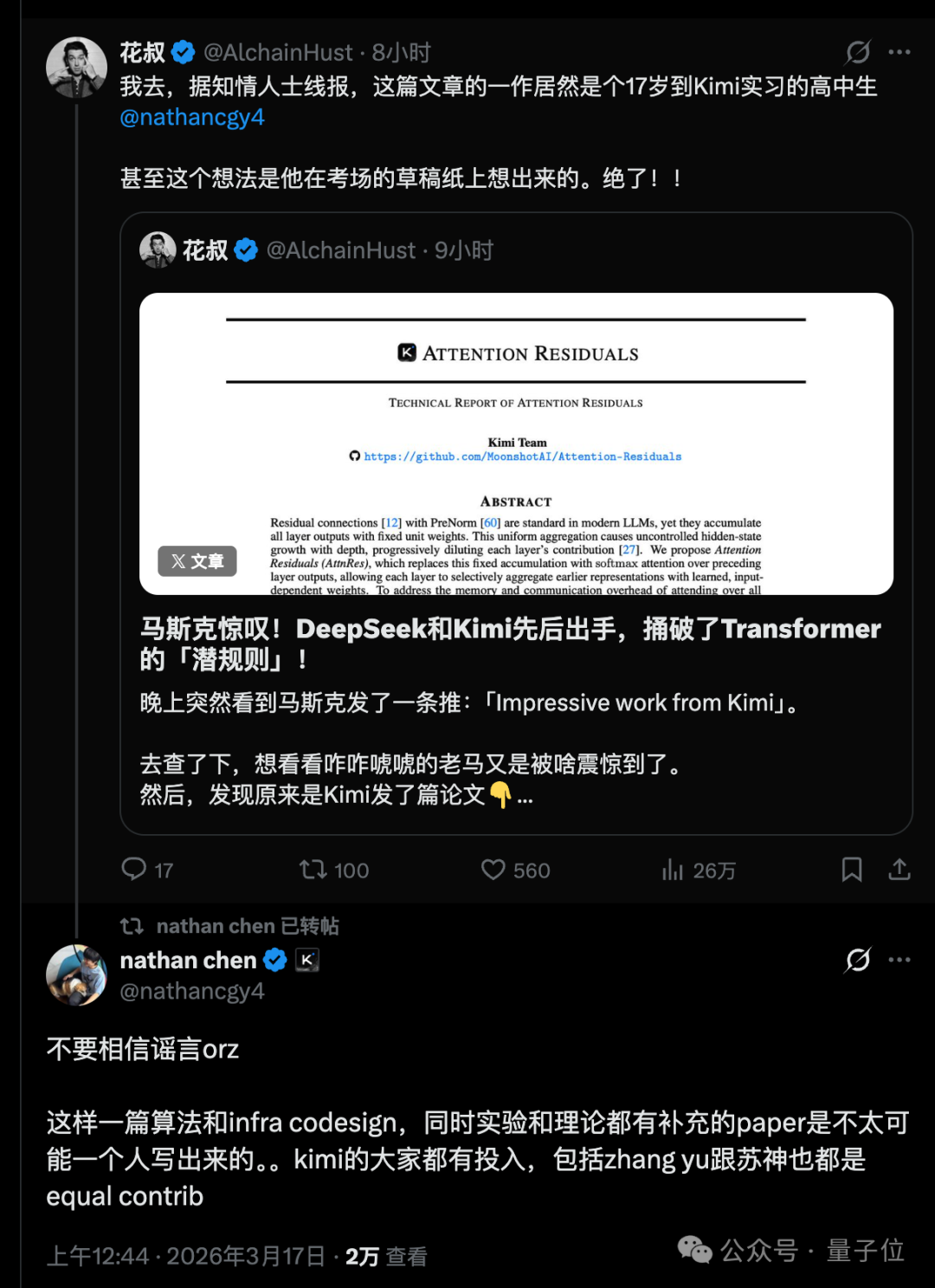
一篇关于革新深度维度信息聚合方式的技术论文,因其创新的思路和显著的工程效果,吸引了包括埃隆·马斯克在内的业界关注。更引人注目的是,论文的共同一作之一,是一名年仅17岁的高中生。
这项来自 Kimi Moonshot AI 团队的技术,名为 Attention Residuals (AttnRes)。它的核心思想是重新思考 Transformer 架构中深度方向的信息聚合方式。
这并非凭空想象,其灵感来源于一个有趣的观察。Ilya Sutskever 曾说过,LSTM(长短期记忆网络)可以看作是一个旋转了90度的 ResNet(残差网络)。
既然如此,那么后来在序列建模领域取代了LSTM的注意力机制,是否也能“旋转90度”,应用到深度维度上呢?Kimi团队给出了肯定的答案,并实现了它。
马斯克与Karpathy的关注
这项工作的价值很快得到了验证。马斯克在社交媒体上转发了相关消息,并评论道“Impressive work from Kimi”。

不仅如此,AI领域的知名研究者 Andrej Karpathy 也对此进行了引申思考。他提出了一个有趣的观点:随机梯度下降(SGD)本身也可以被视为一种 ResNet,并质疑我们对“Attention is All You Need”这篇开创性论文的理解是否足够深入。

残差连接的局限与“深度注意力”的构想
要理解 Attention Residuals,首先得看清当前主流 Transformer 架构中标准残差连接(Standard Residuals)的局限。
在现代大语言模型普遍采用的 PreNorm(前置归一化)范式下,残差连接的工作原理是:第 N 层的输出 = 第 N 层的计算结果 + 第 N-1 层的输出。这种操作一路累加,使得每一层理论上都能“看到”前面所有层的信息。
但问题在于,这种累加是固定且均匀的。每一层对最终表示的贡献权重都是 1。这就好比一个记忆力超群却不懂取舍的人,把所有经历都以相同的强度塞进大脑。结果是,随着网络深度增加,早期层的信息贡献被严重稀释,难以被有效检索。论文中将此称为“PreNorm 稀释问题”。
更棘手的是,这种无差别的累加会导致隐藏状态的范数随着网络深度无界增长,可能引发训练不稳定。
月之暗面团队的思路很直接:既然问题出在“无差别累加”,那就让网络自己学会“选择性回忆”。他们观察到了一个关键的对偶性:网络处理序列时的“时间维度”和堆叠层时的“深度维度”,在数学结构上是同构的。
既然在时间维度上,注意力机制 可以让当前位置选择性地关注序列中之前任何位置的信息,那么在深度维度上,为什么不能让当前层选择性地关注之前任何层的输出呢?
于是,Attention Residuals 应运而生:
- Query:当前层生成一个可学习的伪查询向量。
- Key/Value:所有前面层的输出。
- 聚合:使用注意力机制计算权重,对前面的层输出进行加权求和,替代简单的相加。

工程挑战与解决方案:Block AttnRes
然而,直接应用上述“完全注意力残差”会带来巨大的计算开销。对于一个 L 层的网络,每一层都需要对前面所有 L-1 层计算注意力,复杂度高达 O(L²),这在实践中是无法接受的。
为此,论文提出了 Block Attention Residuals 作为高效的解决方案。核心思想是将连续的若干层打包成一个“块”,并对块内的信息进行压缩。
具体操作如下:
- 将 L 层网络划分为 B 个块。
- 每个块结束时,将其内部多个层的输出信息压缩成一个单一的“摘要”向量。
- 后续层在进行注意力计算时,只需要关注这些块级摘要向量以及当前块内实时的层输出,而无需关注历史上每一个单独的层。
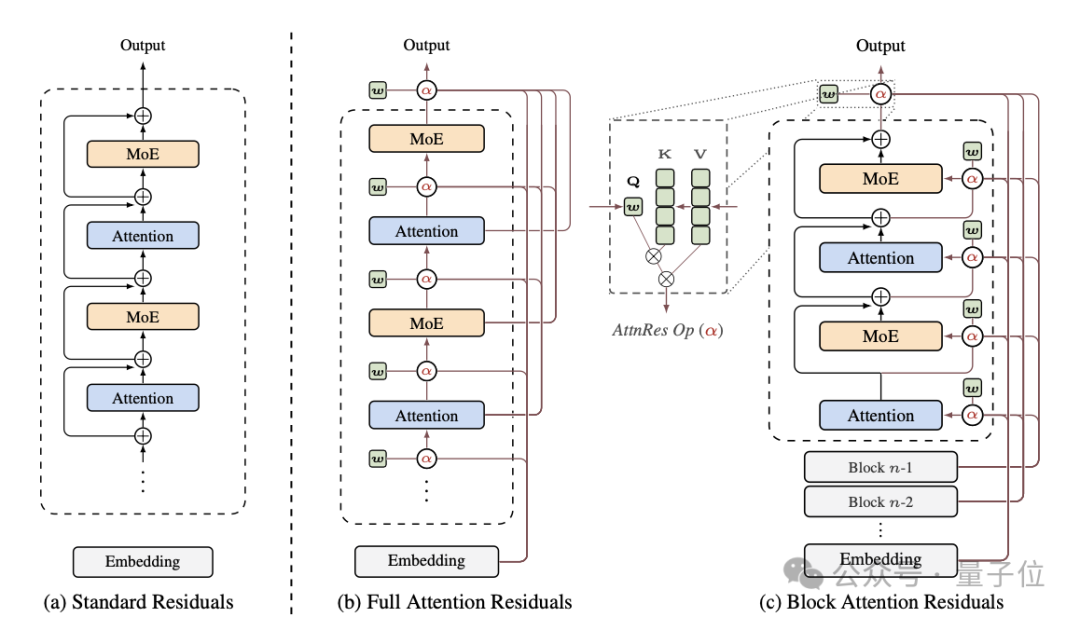
通过这种方法,注意力计算的复杂度从 O(L²) 降低到了 O(L·B)。在实践中,B 可以设置得很小(例如 8 或 16),从而在保持性能的同时大幅降低了内存和通信开销。团队还配合了一系列工程优化,如缓存式流水线通信、序列分片预填充等,以确保其高效运行。
实际效果:在Kimi Linear模型上验证
理论需要实践检验。团队在他们自研的 Kimi Linear 48B 模型上进行了大规模验证。这是一个采用线性注意力的混合专家模型,总参数量480亿,激活参数量为30亿。
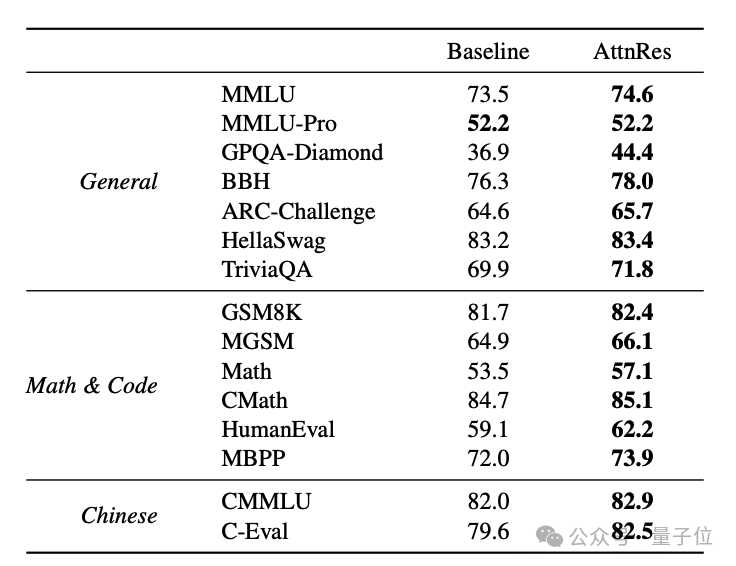
实验结果表明,在相同的计算预算下,使用 Attention Residuals 的模型在下游任务上能获得更好的性能。反之,要达到相同的性能水平,所需的训练计算量减少了约 20% ,这相当于获得了 1.25 倍的训练效率提升,而推理延迟仅增加不到2%。
从具体任务来看,在数学推理、代码生成以及多语言理解等多项基准测试中,AttnRes 模型均持平或略优于基线模型。
最重要的是,Attention Residuals 被设计为一个“即插即用”的模块,可以直接替换现有 Transformer 中的标准残差连接,而无需改动网络的其他部分。这种对 Transformer 架构的深刻反思与改进,正是其价值所在。如果你对这类前沿的模型架构探索感兴趣,可以到 人工智能 板块了解更多深度讨论。
背后的年轻作者:17岁的高中生
这项引人注目的工作,其共同一作名单中出现了一个特别的名字:陈广宇,一位年仅17岁的高中生。
论文的另外两位共同一作是 Kimi 团队的关键人物:提出 RoPE 旋转位置编码的苏剑林,以及 Kimi Linear 的第一作者张宇。团队后来澄清,这是一项需要算法与基础设施协同设计、实验与理论相互补充的复杂工作,是集体智慧的结晶。但一名高中生能深度参与其中并与两位资深研究者共列一作,已然非同寻常。
陈广宇的成长轨迹颇具启发性。大约一年前,他对大模型还知之甚少。通过一场北京的黑客松,他结识了创业导师,并由此决定转向钻研底层技术。在资深研究员的指导下,他从阅读经典论文、追踪 GitHub 上的热门开源项目开始,逐步构建自己的知识体系。一次在社交媒体上分享的技术思考,甚至为他赢得了一家硅谷AI初创公司的实习机会。
在经历了硅谷的高强度实习后,他于去年11月正式加入月之暗面。吸引他的,正是 Kimi 团队在高效注意力机制(如 Flash Linear Attention)上的前沿工作。可以说,他是被最底层的技术所吸引,并最终投身于最核心的研发之中。这样的成长故事,也常在 开发者广场 被大家津津乐道。

他的经历或许不是一个“天才速成”的神话,而更像是一个被前沿技术点燃兴趣,并通过持续学习和实践,一步步将兴趣转化为扎实能力,最终走进大模型研发核心舞台的路径。对于广大开发者和技术爱好者而言,关注并参与这类 开源实战 项目,正是提升能力、跟上时代步伐的重要方式。
这项研究不仅为 Transformer 架构的优化提供了新思路,其背后的团队故事也展示了 AI 研发领域的多样性与活力。技术的突破往往源于对基础组件的重新审视,而人才的涌现则没有固定的模板。想了解更多类似的深度技术解析和行业动态,欢迎持续关注 云栈社区。
论文地址:
https://github.com/MoonshotAI/Attention-Residuals/
参考链接:
https://mp.weixin.qq.com/s/gRR99pEDWb5qsk2a2hwe2w
https://nathanchen.me/public/About%20me.html
 发表于 2026-3-18 15:17:38
|
查看: 151|
回复: 0
发表于 2026-3-18 15:17:38
|
查看: 151|
回复: 0
