Kimi 团队(MoonshotAI)近期发布了一篇新论文《Attention Residuals》,提出了一个看似简单却影响深远的改进:用注意力机制替换 Transformer 中沿用多年的固定残差连接。结果令人惊讶——仅凭这一改动,模型就获得了等效于多花 25% 算力训练的效果。

这篇论文讲了什么?
Attention Residuals(AttnRes) 是 MoonshotAI(Kimi 背后的公司)发布的一项新研究。论文的作者包括 Chen Guangyu、Zhang Yu、Su Jianlin 等人(值得注意的是,Su Jianlin 就是大名鼎鼎的苏剑林,RoPE 旋转位置编码的提出者)。
论文的核心主张非常清晰:Transformer 中使用了快十年的标准残差连接存在根本性问题,而他们提出了一个即插即用(drop-in replacement) 的替代方案——用学习到的注意力机制替换固定权重的残差累加。
Attention Residuals GitHub 仓库(673 stars)
问题出在哪?——PreNorm 残差连接的困境
要理解 AttnRes 的创新,首先要理解它要解决的问题。
在当今几乎所有的大模型中,残差连接(Residual Connection)都遵循同一个简单规则:把当前层的输出和上一层的输出直接相加。这个设计从 2015 年 ResNet 论文至今,几乎没有变过。
但随着模型变得越来越深,这种「均匀累加」策略暴露出了根本性问题:
- 贡献稀释:每一层的输出以相同的权重(1.0)累加到主流中。当模型有 30+ 层时,早期层的贡献被后续层严重稀释。
- 幅度爆炸:隐藏状态的幅度随深度无界增长——这是 PreNorm 架构的一个已知问题。
- 无差别对待:不同的输入 token 可能需要不同层的信息,但标准残差连接对所有 token 一视同仁。

类比理解:标准残差连接就像是让一个学生在考试时,被强制要求把所有课本的内容等权重地混合在一起回答问题。而 AttnRes 则允许学生根据具体问题,有选择性地重点参考最相关的章节。
AttnRes 怎么解决?——用注意力替换固定累加
AttnRes 的核心思想优雅而简洁:让每一层通过注意力机制「选择性地」聚合之前所有层的输出,而不是机械地全部相加。
具体来说,对于第 l 层,AttnRes 的输出 h_l 计算如下:
h_l = Σ(i=0 to l-1) α_{i→l} · v_i
其中:
α_{i→l} = softmax(w_l · v_i / √d) # 注意力权重
w_l ∈ R^d # 每层一个可学习的 pseudo-query
v_i # 第 i 层的输出表示
关键点在于:
- 权重
α 不是固定的 1.0,而是通过 softmax 注意力动态计算的——不同的 token 会对不同层给出不同的权重。
- 每一层只增加一个可学习的向量
w_l(pseudo-query),参数量增加可以忽略不计。
- 由于使用了 softmax 归一化,输出幅度天然有界——从根本上解决了 PreNorm 的幅度爆炸问题。
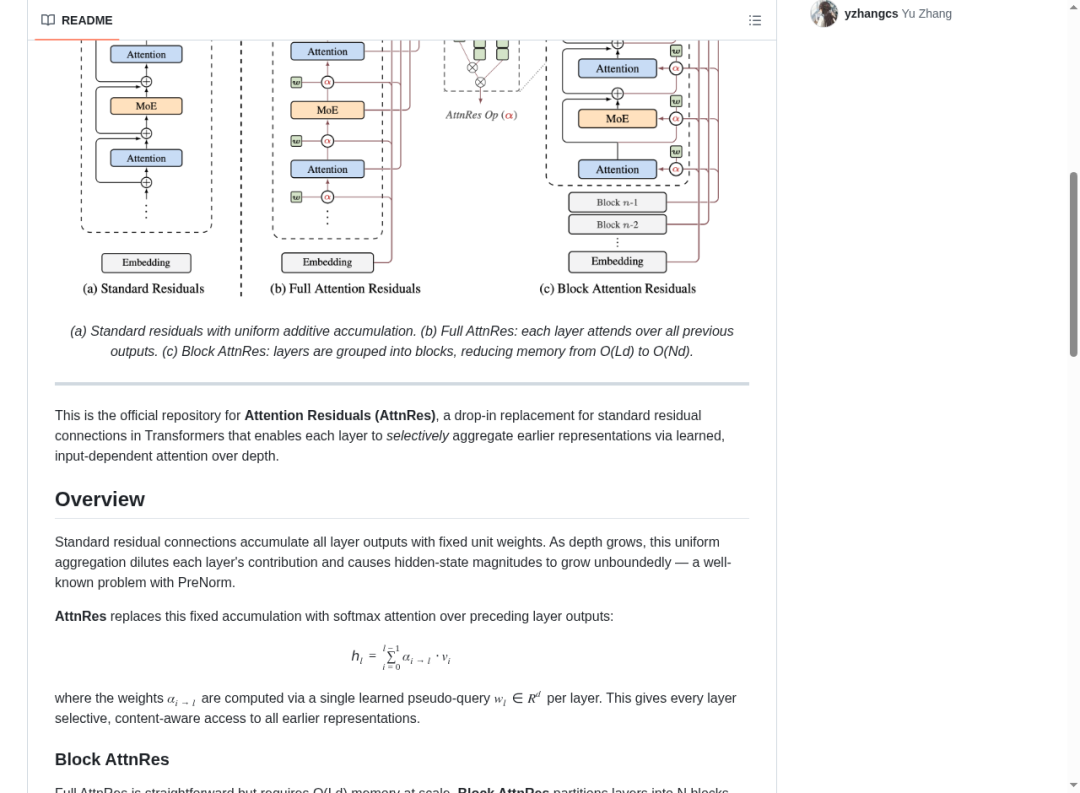
三种残差连接对比:(a) 标准残差——固定权重累加;(b) Full AttnRes——每层注意力聚合所有前序输出;(c) Block AttnRes——块间注意力聚合
Block AttnRes——从理论走向实用
Full AttnRes 的效果很好,但有一个实际问题:它需要保存所有前序层的输出,内存复杂度为 O(Ld)(L 为层数,d 为隐藏维度)。对于 30+ 层的大模型,这是一笔不小的开销。
为此,论文提出了 Block AttnRes——一个务实的工程方案:
- 将 L 层划分为 N 个块(约 8 个块)。
- 块内仍使用标准残差连接(不增加开销)。
- 注意力机制仅应用于块级表示之间。
- 内存降至 O(Nd)——仅需保存块级输出。
关键发现:实验表明,仅使用约 8 个块(而非全部 30+ 层),Block AttnRes 就能恢复 Full AttnRes 的绝大部分收益,同时保持边际开销(marginal overhead)——这使其成为一个真正的即插即用方案。
实验结果——数字说话
Scaling Laws:等效 1.25x 更多计算量
在不同计算预算下的 Scaling Law 实验中,AttnRes 始终优于 baseline。最关键的发现是:Block AttnRes 达到了 baseline 用 1.25 倍计算量才能达到的 loss 水平——相当于白捡了 25% 的 计算效率。
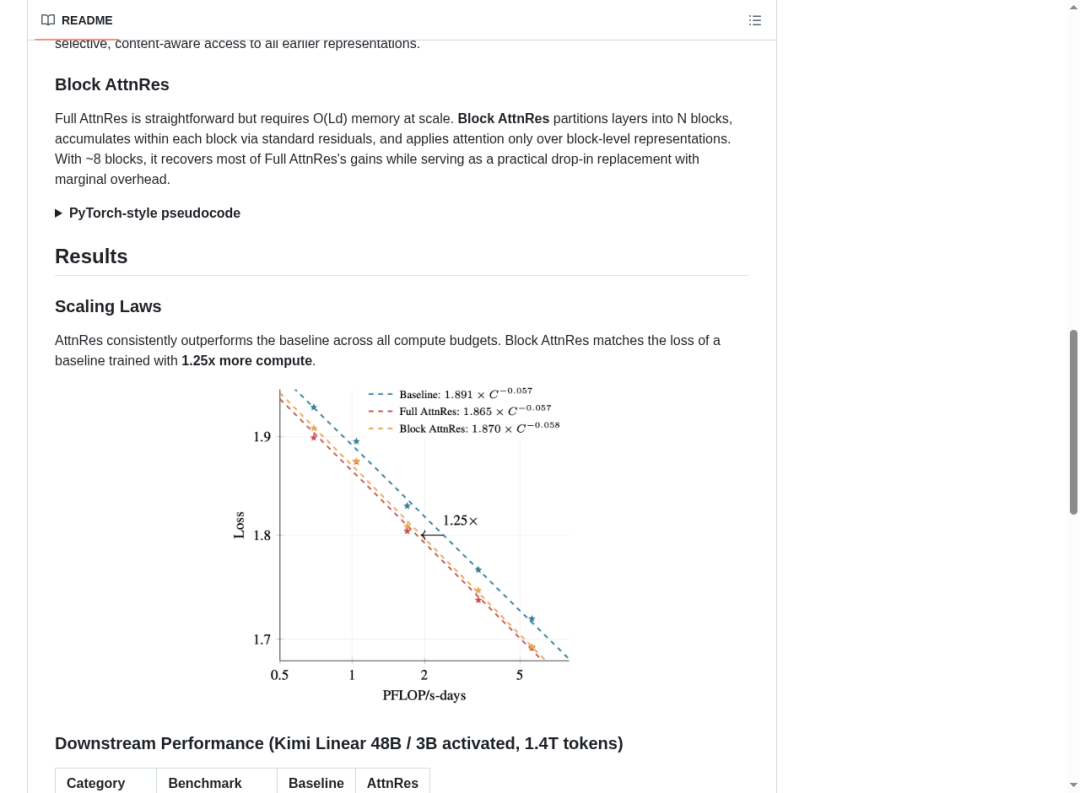
Scaling Laws 对比:AttnRes(红/橙线)在所有计算预算下持续优于 Baseline(蓝线),Block AttnRes 等效于 1.25x 计算量
下游任务:全面提升
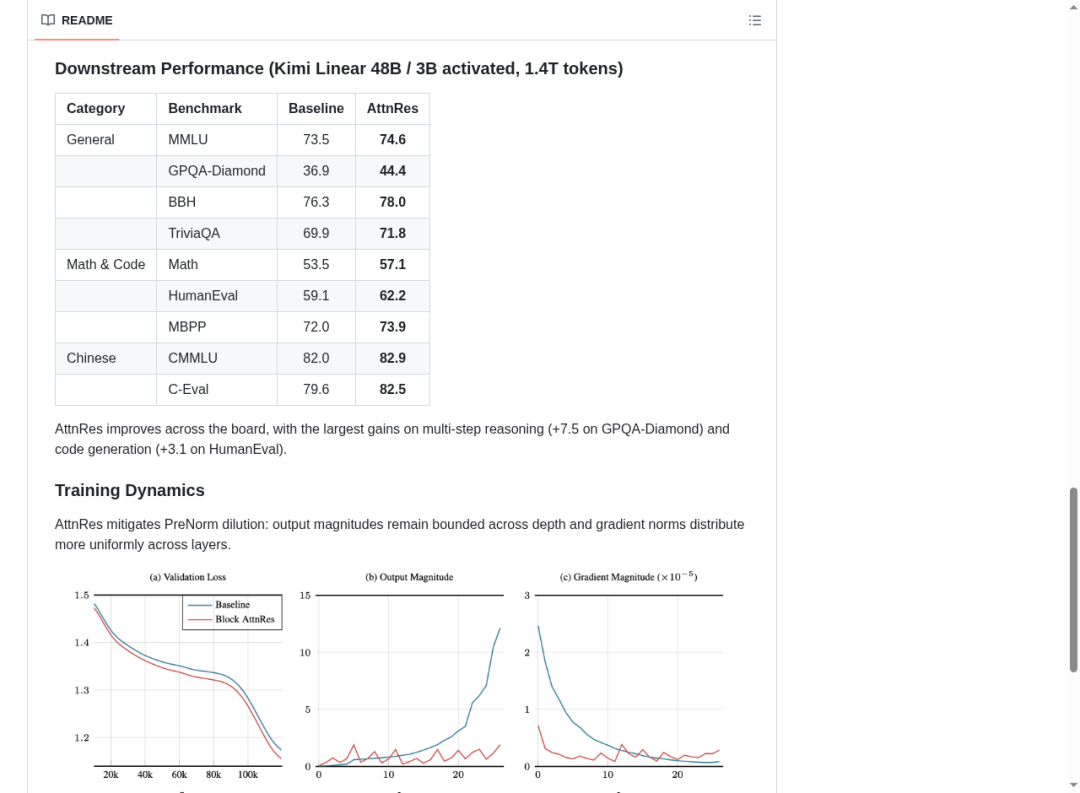
在 Kimi Linear(48B 总参数 / 3B 活跃,1.4T tokens 训练)上的下游任务评测结果令人印象深刻:
| 类别 |
基准测试 |
Baseline |
AttnRes |
提升 |
| 通用 |
MMLU |
73.5 |
74.6 |
+1.1 |
|
GPQA-Diamond |
36.9 |
44.4 |
+7.5 |
|
BBH |
76.3 |
78.0 |
+1.7 |
|
TriviaQA |
69.9 |
71.8 |
+1.9 |
| 数学与代码 |
Math |
53.5 |
57.1 |
+3.6 |
|
HumanEval |
59.1 |
62.2 |
+3.1 |
|
MBPP |
72.0 |
73.9 |
+1.9 |
| 中文 |
CMMLU |
82.0 |
82.9 |
+0.9 |
|
C-Eval |
79.6 |
82.5 |
+2.9 |
最亮眼的提升出现在多步推理(GPQA-Diamond +7.5)和数学(Math +3.6)上——这恰恰说明,选择性地利用深层特征对于需要复杂推理的任务尤为重要。
GitHub README 中的完整基准测试结果和训练动态分析
训练动态:从根本上解决 PreNorm 稀释
论文还展示了 AttnRes 如何从根本上改善训练动态。下面的三张图清楚地说明了变化:
- 验证损失(Validation Loss):Block AttnRes(红线)始终低于 Baseline(蓝线),训练过程更加平稳。
- 输出幅度(Output Magnitude):Baseline 的输出幅度在深层急剧爆炸(蓝色尖峰),而 AttnRes 保持平稳——这正是 softmax 归一化的威力。
- 梯度幅度(Gradient Magnitude):Baseline 的梯度在特定层出现异常集中(蓝色尖峰),而 AttnRes 的梯度分布更加均匀——这意味着更稳定的训练过程。
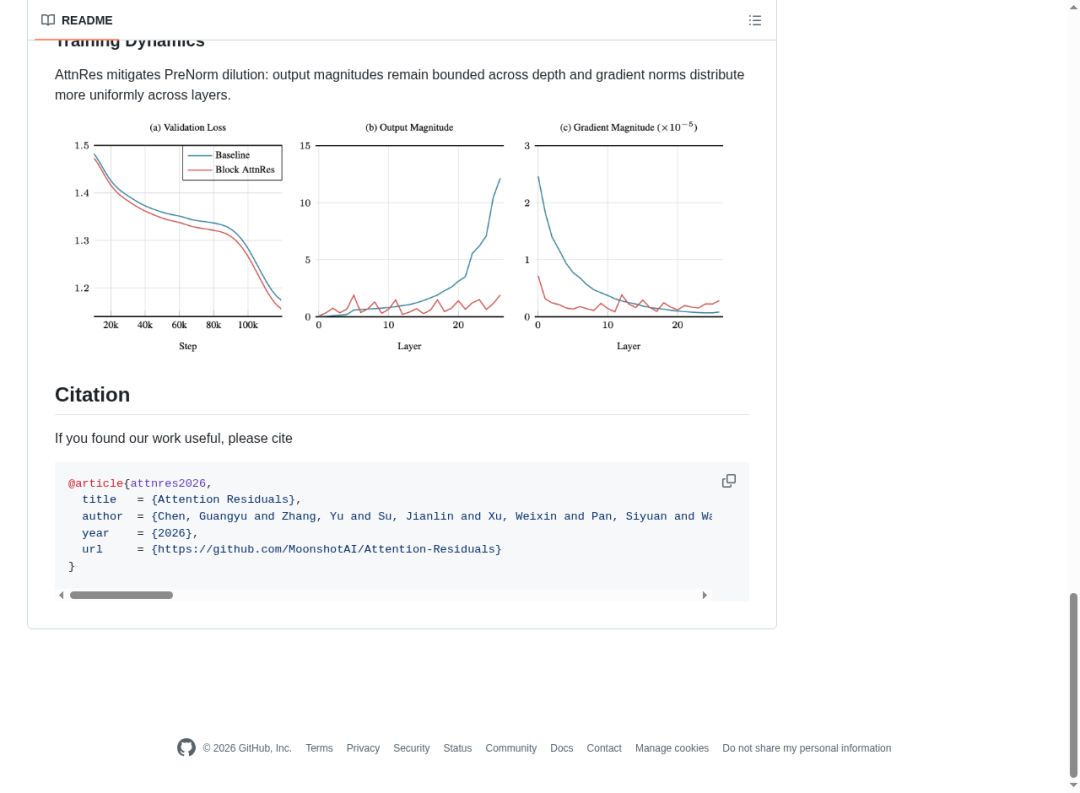
训练动态对比:(a) 验证损失;(b) 各层输出幅度——Baseline 在深层爆炸而 AttnRes 保持平稳;(c) 梯度幅度分布
为什么厉害?五大创新点
- 挑战了十年不变的基础组件——残差连接从 2015 年的 ResNet 至今几乎没有人动过。AttnRes 是第一个在大规模 LLM 上证明「残差连接可以而且应该被重新设计」的工作。
- 理论与实践的完美结合——Full AttnRes 给出了理论上最优的方案,Block AttnRes 则提供了工程上可行的落地路径。这种「先证明上界,再逼近上界」的研究范式非常漂亮。
- 即插即用,零侵入——不需要改模型的其他任何部分(注意力层、FFN、归一化方式等),只需要替换残差连接方式。这意味着任何现有模型都可以低成本尝试。
- 白捡 25% 算力的 Scaling Law 收益——在大模型训练动辄数百万美元的今天,等效 1.25x 的计算效率提升意味着巨大的经济价值。
- 在前沿模型上实战验证——不是在 toy model 上做实验,而是在 Kimi Linear 48B 这样的前沿生产模型上验证。这说明 MoonshotAI 有信心将这项技术用于下一代产品。
写在最后
Attention Residuals 的意义不仅在于它带来的性能提升,更在于它重新审视了一个我们早已习以为常的基础组件。当所有人都在注意力机制、激活函数、归一化方法上卷的时候,Kimi 团队转身对最基础的残差连接动了手术——而结果证明,越是基础的改进,越可能带来系统性的收益。
值得一提的是,论文的作者之一苏剑林(Su Jianlin)此前提出的 RoPE 旋转位置编码已经被 Llama、Qwen 等几乎所有主流大模型采用。如果 AttnRes 也能获得类似的广泛采用——考虑到它的即插即用特性和显著收益——那这将是 Kimi 团队对 LLM 基础架构的又一项重大贡献。
论文和代码:github.com/MoonshotAI/Attention-Residuals
这项研究对基础架构的思考与优化,正是技术社区持续探索的核心动力。对前沿 AI 技术架构与效率优化感兴趣的开发者,欢迎到 云栈社区 交流讨论。
 发表于 2026-3-18 05:10:50
|
查看: 208|
回复: 0
发表于 2026-3-18 05:10:50
|
查看: 208|
回复: 0
