这篇文章将从零开始,实现一个简洁的 LLM-JEPA (Large Language Models Meet Joint Embedding Predictive Architectures) 训练脚本。我们的目标是理解 JEPA 的核心思想:对同一文本创建两个视图,并预测被遮蔽片段的嵌入表示,使用表示对齐损失进行训练。
通过逐行解析代码,我们将阐明每个函数的设计意图,并将其与论文的核心思想对应起来。这个实现力求清晰而非完整,旨在帮助你掌握这套方法的基础,并便于你根据自己的实验需求进行修改。
代码概览
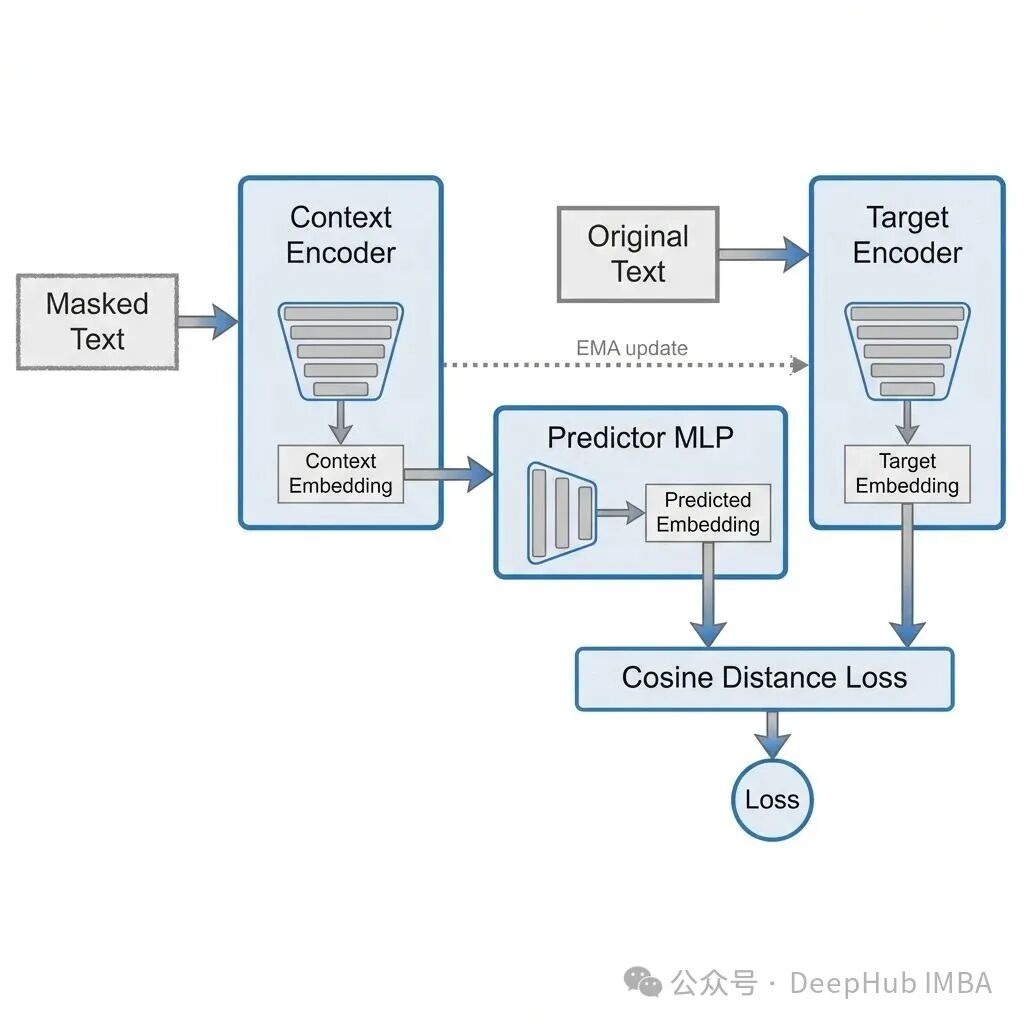
整个训练脚本集成在一个文件中。其核心流程是:接收原始文本,创建两个视图。Context 视图会将某些片段替换为 [MASK],而 Target 视图则保持原始文本不变,仅在遮蔽位置计算损失。可训练的 Context 编码器负责预测 Target 编码器在遮蔽位置的表示。Target 编码器是 Context 编码器的 EMA(指数移动平均)副本,不参与梯度更新。损失函数采用预测嵌入与目标嵌入之间的余弦距离。
运行示例如下:
# 小型冒烟测试(无需下载,随机初始化模型)
python llm_jepa_train.py --smoke_test
# 使用 Hugging Face 模型骨干进行训练
python llm_jepa_train.py --model_name distilbert-base-uncased --steps 200 --batch_size 8
# 在自己的文本文件上训练
python llm_jepa_train.py --model_name distilbert-base-uncased --text_file data.txt --steps 2000
这是一个用于理解和参考的简洁实现,并非完整的项目仓库。编码器部分使用了 Transformers 库。
import argparse
import math
import os
import random
from dataclasses import dataclass
from typing import List, Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
try:
from transformers import AutoTokenizer, AutoModel, AutoConfig
except Exception:
AutoTokenizer = None
AutoModel = None
AutoConfig = None
# -----------------------------
# Utilities
# -----------------------------
def set_seed(seed: int):
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def pick_device(device_str: str) -> torch.device:
if device_str == "auto":
return torch.device("cuda" if torch.cuda.is_available() else "cpu")
return torch.device(device_str)
# -----------------------------
# Span masking (simple + effective)
# -----------------------------
def sample_span_mask(
seq_len: int,
mask_ratio: float,
mean_span_len: int,
special_positions: Optional[set] = None,
) -> torch.BoolTensor:
"""
Returns a boolean mask of length seq_len indicating which positions are masked.
We mask contiguous spans until we reach approximately mask_ratio of tokens.
"""
if special_positions is None:
special_positions = set()
mask = torch.zeros(seq_len, dtype=torch.bool)
if seq_len <= 0:
return mask
target_to_mask = max(1, int(round(seq_len * mask_ratio)))
masked = 0
attempts = 0
max_attempts = seq_len * 4
while masked < target_to_mask and attempts < max_attempts:
attempts += 1
span_len = max(1, int(random.expovariate(1.0 / max(1, mean_span_len))))
span_len = min(span_len, seq_len)
start = random.randint(0, seq_len - 1)
end = min(seq_len, start + span_len)
span_positions = [i for i in range(start, end) if i not in special_positions]
if not span_positions:
continue
newly = 0
for i in span_positions:
if not mask[i]:
mask[i] = True
newly += 1
masked += newly
return mask
def apply_mask_to_input_ids(
input_ids: torch.LongTensor,
attention_mask: torch.LongTensor,
tokenizer,
mask_ratio: float,
mean_span_len: int,
) -> Tuple[torch.LongTensor, torch.BoolTensor]:
"""
Masks spans inside non-special, non-padding tokens.
Returns:
masked_input_ids: input ids with masked tokens replaced by [MASK]
pred_mask: boolean mask over positions where we apply JEPA loss
"""
assert input_ids.dim() == 1
seq_len = int(attention_mask.sum().item())
# Identify special token positions (CLS, SEP, etc.) in the visible region
special_positions = set()
for i in range(seq_len):
tid = int(input_ids[i].item())
if tid in {
tokenizer.cls_token_id,
tokenizer.sep_token_id,
tokenizer.pad_token_id,
}:
special_positions.add(i)
pred_mask = sample_span_mask(
seq_len=seq_len,
mask_ratio=mask_ratio,
mean_span_len=mean_span_len,
special_positions=special_positions,
)
masked_input_ids = input_ids.clone()
mask_token_id = tokenizer.mask_token_id
if mask_token_id is None:
raise ValueError("Tokenizer has no mask_token_id. Use a model with [MASK].")
# Replace masked positions with [MASK]
masked_input_ids[:seq_len][pred_mask] = mask_token_id
# pred_mask should be full length (includes pads as False)
full_mask = torch.zeros_like(attention_mask, dtype=torch.bool)
full_mask[:seq_len] = pred_mask
return masked_input_ids, full_mask
# -----------------------------
# Dataset
# -----------------------------
class TextLinesDataset(Dataset):
def __init__(self, texts: List[str]):
self.texts = [t.strip() for t in texts if t.strip()]
def __len__(self) -> int:
return len(self.texts)
def __getitem__(self, idx: int) -> str:
return self.texts[idx]
def load_texts_from_file(path: str, max_lines: Optional[int] = None) -> List[str]:
texts = []
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if max_lines is not None and i >= max_lines:
break
texts.append(line.rstrip("\n"))
return texts
def default_tiny_corpus() -> List[str]:
return [
"The cat sat on the mat and looked at the window.",
"A quick brown fox jumps over the lazy dog.",
"Deep learning models can learn useful representations from raw data.",
"Rocket Learning builds AI tools for education in India.",
"Transformers use attention to mix information across tokens.",
"Self-supervised learning can reduce the need for labels.",
"JEPA trains models to predict embeddings, not tokens.",
"Bengaluru is a major tech hub in India.",
"A good system design balances simplicity and scalability.",
"Reading code carefully helps you understand how an idea is implemented.",
]
@dataclass
class Batch:
input_ids: torch.LongTensor # [B, L]
attention_mask: torch.LongTensor # [B, L]
masked_input_ids: torch.LongTensor # [B, L]
pred_mask: torch.BoolTensor # [B, L] positions to compute loss on
def collate_jepa(
batch_texts: List[str],
tokenizer,
max_length: int,
mask_ratio: float,
mean_span_len: int,
) -> Batch:
toks = tokenizer(
batch_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
input_ids = toks["input_ids"] # [B, L]
attention_mask = toks["attention_mask"] # [B, L]
masked_input_ids_list = []
pred_mask_list = []
for b in range(input_ids.size(0)):
mi, pm = apply_mask_to_input_ids(
input_ids[b],
attention_mask[b],
tokenizer,
mask_ratio=mask_ratio,
mean_span_len=mean_span_len,
)
masked_input_ids_list.append(mi)
pred_mask_list.append(pm)
masked_input_ids = torch.stack(masked_input_ids_list, dim=0)
pred_mask = torch.stack(pred_mask_list, dim=0)
return Batch(
input_ids=input_ids,
attention_mask=attention_mask,
masked_input_ids=masked_input_ids,
pred_mask=pred_mask,
)
# -----------------------------
# Model: Encoder + Predictor + EMA target encoder
# -----------------------------
class PredictorMLP(nn.Module):
def __init__(self, dim: int, hidden_mult: int = 4, dropout: float = 0.0):
super().__init__()
hidden = dim * hidden_mult
self.net = nn.Sequential(
nn.Linear(dim, hidden),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden, dim),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)
class LLMJEPA(nn.Module):
def __init__(self, encoder: nn.Module, dim: int, ema_m: float = 0.99, pred_hidden_mult: int = 4):
super().__init__()
self.context_encoder = encoder
self.target_encoder = self._copy_encoder(encoder)
self.predictor = PredictorMLP(dim=dim, hidden_mult=pred_hidden_mult, dropout=0.0)
self.ema_m = ema_m
for p in self.target_encoder.parameters():
p.requires_grad = False
@staticmethod
def _copy_encoder(enc: nn.Module) -> nn.Module:
import copy
return copy.deepcopy(enc)
@torch.no_grad()
def ema_update(self):
m = self.ema_m
for p_ctx, p_tgt in zip(self.context_encoder.parameters(), self.target_encoder.parameters()):
p_tgt.data.mul_(m).add_(p_ctx.data, alpha=(1.0 - m))
def forward(
self,
masked_input_ids: torch.LongTensor,
input_ids: torch.LongTensor,
attention_mask: torch.LongTensor,
pred_mask: torch.BoolTensor,
) -> torch.Tensor:
"""
Returns JEPA loss (scalar).
We compute:
z_ctx = context_encoder(masked_input)
z_tgt = target_encoder(full input)
pred = predictor(z_ctx)
loss over positions in pred_mask
"""
out_ctx = self.context_encoder(input_ids=masked_input_ids, attention_mask=attention_mask)
z_ctx = out_ctx.last_hidden_state # [B, L, D]
with torch.no_grad():
out_tgt = self.target_encoder(input_ids=input_ids, attention_mask=attention_mask)
z_tgt = out_tgt.last_hidden_state # [B, L, D]
pred = self.predictor(z_ctx) # [B, L, D]
# Select masked positions
# pred_mask: [B, L] bool
masked_pred = pred[pred_mask] # [N, D]
masked_tgt = z_tgt[pred_mask] # [N, D]
if masked_pred.numel() == 0:
# Safety: if a batch ends up with no masked tokens, return zero loss
return pred.sum() * 0.0
masked_pred = F.normalize(masked_pred, dim=-1)
masked_tgt = F.normalize(masked_tgt, dim=-1)
# Cosine distance
loss = 1.0 - (masked_pred * masked_tgt).sum(dim=-1)
return loss.mean()
# -----------------------------
# Training
# -----------------------------
def build_hf_encoder(model_name: str):
if AutoModel is None:
raise RuntimeError("transformers is not installed. pip install transformers")
config = AutoConfig.from_pretrained(model_name)
encoder = AutoModel.from_pretrained(model_name, config=config)
dim = int(config.hidden_size)
return encoder, dim
def build_random_encoder(vocab_size: int = 30522, dim: int = 256, layers: int = 4, heads: int = 4):
"""
For smoke tests only: small Transformer encoder (random init).
Requires a tokenizer with vocab mapping for ids.
"""
encoder_layer = nn.TransformerEncoderLayer(d_model=dim, nhead=heads, batch_first=True)
transformer = nn.TransformerEncoder(encoder_layer, num_layers=layers)
class TinyEncoder(nn.Module):
def __init__(self):
super().__init__()
self.emb = nn.Embedding(vocab_size, dim)
self.pos = nn.Embedding(512, dim)
self.enc = transformer
def forward(self, input_ids, attention_mask):
B, L = input_ids.shape
pos_ids = torch.arange(L, device=input_ids.device).unsqueeze(0).expand(B, L)
x = self.emb(input_ids) + self.pos(pos_ids)
# attention_mask: 1 for keep, 0 for pad
# transformer expects src_key_padding_mask: True for pad
pad_mask = attention_mask == 0
h = self.enc(x, src_key_padding_mask=pad_mask)
return type("Out", (), {"last_hidden_state": h})
return TinyEncoder(), dim
def save_checkpoint(path: str, model: LLMJEPA, optimizer: torch.optim.Optimizer, step: int):
os.makedirs(os.path.dirname(path), exist_ok=True)
torch.save(
{
"step": step,
"context_encoder": model.context_encoder.state_dict(),
"target_encoder": model.target_encoder.state_dict(),
"predictor": model.predictor.state_dict(),
"optimizer": optimizer.state_dict(),
},
path,
)
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--model_name", type=str, default="distilbert-base-uncased", help="HF encoder backbone")
parser.add_argument("--text_file", type=str, default="", help="Path to a newline-separated text file")
parser.add_argument("--max_lines", type=int, default=50000)
parser.add_argument("--max_length", type=int, default=128)
parser.add_argument("--mask_ratio", type=float, default=0.3)
parser.add_argument("--mean_span_len", type=int, default=5)
parser.add_argument("--ema_m", type=float, default=0.99)
parser.add_argument("--pred_hidden_mult", type=int, default=4)
parser.add_argument("--batch_size", type=int, default=8)
parser.add_argument("--lr", type=float, default=2e-5)
parser.add_argument("--weight_decay", type=float, default=0.01)
parser.add_argument("--steps", type=int, default=500)
parser.add_argument("--warmup_steps", type=int, default=50)
parser.add_argument("--log_every", type=int, default=25)
parser.add_argument("--save_every", type=int, default=200)
parser.add_argument("--save_path", type=str, default="checkpoints/llm_jepa.pt")
parser.add_argument("--device", type=str, default="auto")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--smoke_test", action="store_true", help="No downloads, tiny random encoder, tiny corpus")
args = parser.parse_args()
set_seed(args.seed)
device = pick_device(args.device)
if args.smoke_test:
if AutoTokenizer is None:
raise RuntimeError("transformers is required even for smoke_test (for tokenizer).")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
# Ensure mask token exists
if tokenizer.mask_token_id is None:
raise ValueError("Tokenizer must support [MASK]. Use a masked LM tokenizer.")
texts = default_tiny_corpus()
ds = TextLinesDataset(texts)
encoder, dim = build_random_encoder(vocab_size=int(tokenizer.vocab_size), dim=256, layers=4, heads=4)
model = LLMJEPA(encoder=encoder, dim=dim, ema_m=0.95, pred_hidden_mult=2).to(device)
lr = 1e-4
else:
if AutoTokenizer is None:
raise RuntimeError("transformers is not installed. pip install transformers")
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
if tokenizer.mask_token_id is None:
raise ValueError(
"This tokenizer has no [MASK]. Pick a masked-encoder model (BERT/DeBERTa/DistilBERT)."
)
if args.text_file:
texts = load_texts_from_file(args.text_file, max_lines=args.max_lines)
else:
texts = default_tiny_corpus()
ds = TextLinesDataset(texts)
encoder, dim = build_hf_encoder(args.model_name)
model = LLMJEPA(encoder=encoder, dim=dim, ema_m=args.ema_m, pred_hidden_mult=args.pred_hidden_mult).to(device)
lr = args.lr
# DataLoader
def _collate(batch_texts):
return collate_jepa(
batch_texts=batch_texts,
tokenizer=tokenizer,
max_length=args.max_length,
mask_ratio=args.mask_ratio,
mean_span_len=args.mean_span_len,
)
dl = DataLoader(ds, batch_size=args.batch_size, shuffle=True, drop_last=True, collate_fn=_collate)
# Optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=args.weight_decay)
# Simple warmup + cosine schedule
def lr_at(step: int) -> float:
if step < args.warmup_steps:
return float(step + 1) / float(max(1, args.warmup_steps))
progress = (step - args.warmup_steps) / float(max(1, args.steps - args.warmup_steps))
progress = min(max(progress, 0.0), 1.0)
return 0.5 * (1.0 + math.cos(math.pi * progress))
model.train()
running = 0.0
step = 0
data_iter = iter(dl)
while step < args.steps:
try:
batch = next(data_iter)
except StopIteration:
data_iter = iter(dl)
batch = next(data_iter)
# Move to device
input_ids = batch.input_ids.to(device)
attention_mask = batch.attention_mask.to(device)
masked_input_ids = batch.masked_input_ids.to(device)
pred_mask = batch.pred_mask.to(device)
# LR schedule
scale = lr_at(step)
for pg in optimizer.param_groups:
pg["lr"] = lr * scale
loss = model(
masked_input_ids=masked_input_ids,
input_ids=input_ids,
attention_mask=attention_mask,
pred_mask=pred_mask,
)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
# EMA update after optimizer step
model.ema_update()
running += float(loss.item())
step += 1
if step % args.log_every == 0:
avg = running / float(args.log_every)
running = 0.0
print(f"step {step:6d} | loss {avg:.4f} | lr {optimizer.param_groups[0]['lr']:.6g}")
if step % args.save_every == 0:
save_checkpoint(args.save_path, model, optimizer, step)
print(f"saved checkpoint to {args.save_path} at step {step}")
save_checkpoint(args.save_path, model, optimizer, step)
print(f"training done. final checkpoint: {args.save_path}")
if __name__ == "__main__":
main()
这个脚本在训练什么?
这是一个面向文本的 JEPA 风格表示预测器。它接收普通文本行,并为每个样本创建两个不同的视图。
- 遮蔽视图 (Context View):与原始句子相同,但其中连续的片段被替换成了
[MASK] 标记。
- 原始视图 (Target View):保持原始文本不变,没有进行任何遮蔽。
那么训练流程是怎样的呢?遮蔽视图会经过一个可训练的 Context 编码器,而原始视图则经过一个不可训练的 Target 编码器。核心目标是训练一个预测器,让 Context 编码器输出的表示,能够预测 Target 编码器输出的表示。但关键在于,损失只在被遮蔽的那些位置上计算。Target 编码器的参数会通过 EMA(指数移动平均)方式缓慢更新,以保持训练的稳定性。
这种设计的精妙之处在于,它鼓励模型学习如何“填补语义空缺”,即从上下文中推理出缺失部分的抽象含义,而不是去死记硬背地预测具体的下一个词(token)。这种在表示空间(embedding)进行预测的思路,正是 JEPA 区别于传统语言模型的核心。
关键代码解析
set_seed 函数
def set_seed(seed: int):
random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
这个函数确保了实验的可复现性。random.seed(seed) 固定 Python 内置的随机操作(例如我们后面会看到的 span 遮蔽采样);torch.manual_seed(seed) 固定 PyTorch 在 CPU 上的随机性;torch.cuda.manual_seed_all(seed) 则固定 CUDA 内核的随机性。由于模型初始化和遮蔽策略都是随机的,如果不设置种子,每次运行的结果都可能不同。
pick_device 函数
def pick_device(device_str: str) -> torch.device:
if device_str == "auto":
return torch.device("cuda" if torch.cuda.is_available() else "cpu")
return torch.device(device_str)
它返回一个 PyTorch 设备对象。如果传入 --device auto,脚本会自动检测并使用可用的 GPU,否则回退到 CPU。你也可以直接指定 --device cpu 或 --device cuda。确保张量和模型在同一个设备上是 PyTorch 训练的基本要求。
sample_span_mask 函数
def sample_span_mask(seq_len, mask_ratio, mean_span_len, special_positions=None)
这是整个脚本中最重要的函数之一。它的目标是创建一个布尔掩码(Boolean Mask),用来标记序列中哪些位置应该被遮蔽。参数含义如下:
seq_len: 真实的 token 数量(不包括 padding)。mask_ratio: 遮蔽比例,例如 0.3 表示遮蔽大约 30% 的 token。mean_span_len: 连续遮蔽的 span(片段)的平均长度。special_positions: 永远不应该被遮蔽的特殊位置集合(如 CLS、SEP、PAD 等 token)。
内部逻辑是:先创建一个全为 False 的掩码,然后计算需要遮蔽的 token 数量:target_to_mask = max(1, int(round(seq_len * mask_ratio)))。即使序列很短,也至少遮蔽 1 个 token。
接下来进入循环,不断采样 span 直到遮蔽数量达标。每个 span 的长度是从指数分布中采样的:span_len = max(1, int(random.expovariate(1.0 / max(1, mean_span_len))))。这种采样方式会产生大量短 span 和少量长 span,比较符合自然文本中信息缺失的分布。然后随机选择一个起始位置,过滤掉该 span 内的特殊 token,将剩余位置标记为 True。
遮蔽策略对表示学习的质量至关重要。Span 遮蔽(而非随机遮蔽单个 token)能迫使模型必须从更广泛的上下文信息中去推断连续缺失内容的语义,从而学习到更有意义的表示。
def apply_mask_to_input_ids(input_ids, attention_mask, tokenizer, mask_ratio, mean_span_len)
这个函数处理单个样本。它接收原始的 token ids,输出两个东西:
masked_input_ids: 将遮蔽位置替换为 [MASK] 对应 token id 后的新 ids。pred_mask: 一个布尔掩码,标记哪些位置需要计算 JEPA 损失。
首先,它计算可见序列的真实长度:seq_len = int(attention_mask.sum().item())。attention_mask 中,真实 token 为 1,padding 为 0。
接着,识别特殊 token(如 CLS, SEP)的位置,这些位置不能参与遮蔽。然后调用 sample_span_mask 函数采样出需要遮蔽的位置(pred_mask)。将这些位置的 token id 替换为分词器的 mask_token_id:masked_input_ids[:seq_len][pred_mask] = mask_token_id。
最后返回的 pred_mask 是扩展到完整序列长度的,padding 位置均为 False。这样,JEPA 损失就只会在我们主动遮蔽的那些位置上计算,其他位置则被忽略。
TextLinesDataset 类
class TextLinesDataset(Dataset):
def __init__(self, texts):
self.texts = [t.strip() for t in texts if t.strip()]
一个极其简单的数据集实现,它存储一个文本行列表,并自动过滤掉空行和首尾空白。__len__ 返回行数,__getitem__ 返回单条文本字符串。load_texts_from_file 用于从文件逐行读取文本,并可限制最大行数,在指定 --text_file 参数时使用。default_tiny_corpus 则提供了一个内置的小型测试数据集。
Batch 数据类
@dataclass
class Batch:
input_ids
attention_mask
masked_input_ids
pred_mask
使用 dataclass 来封装一个批次的数据,这比直接返回元组清晰得多,大大提升了代码的可读性。
collate_jepa 函数
这是 DataLoader 在创建批次时调用的关键函数。输入是一个批次的原始文本列表。它首先使用分词器(tokenizer)进行分词、填充(padding)和截断(truncation):toks = tokenizer(batch_texts, padding=True, truncation=True, max_length=max_length, return_tensors="pt"),产生 input_ids 和 attention_mask。
然后,对批次中的每一个样本,调用 apply_mask_to_input_ids 来生成其遮蔽版本 masked_input_ids 和预测掩码 pred_mask。最后将所有样本的结果堆叠(stack)起来,返回一个 Batch 对象。
DataLoader 本身是按样本读取数据的,但模型训练需要批处理。所有的分词、填充和遮蔽操作都在这个函数中有序完成。
PredictorMLP 类
预测器头,结构非常简单:
nn.Linear(dim, hidden)
nn.GELU()
nn.Dropout()
nn.Linear(hidden, dim)
它的作用是将 Context 编码器输出的表示,映射到 Target 编码器输出的表示空间。你可以把它看作一个学习出来的适配器(adapter),帮助对齐两个编码器产生的嵌入向量。
LLMJEPA 模型类
这是主模型的包装器,包含四个核心部分:
context_encoder: 可训练的 Transformer 编码器。target_encoder: context_encoder 的深拷贝副本,但被设置为不可训练(requires_grad = False)。predictor: 上面提到的 MLP 预测器。ema_m: EMA 更新的动量因子。
_copy_encoder 方法使用 copy.deepcopy 来确保 Target 编码器和 Context 编码器拥有完全相同的初始状态。
ema_update 方法负责缓慢更新 Target 编码器的权重:p_tgt = m * p_tgt + (1 - m) * p_ctx。当 m=0.99 时,Target 编码器的变化非常缓慢,这有助于稳定训练过程,并降低表示坍塌(representation collapse)的风险。
forward 方法的流程如下:
- 将遮蔽视图
masked_input_ids 输入 context_encoder(可训练),得到上下文表示 z_ctx。
- 在
torch.no_grad() 上下文中,将原始视图 input_ids 输入 target_encoder(无梯度),得到目标表示 z_tgt。
- 使用
predictor 处理 z_ctx,得到预测表示 pred。
- 关键一步:利用
pred_mask,只选取被遮蔽位置的向量进行计算:
masked_pred = pred[pred_mask] # [N, D]
masked_tgt = z_tgt[pred_mask] # [N, D]
这里从 [B, L, D] 的形状中提取出了 [N, D],其中 N 是这个批次中所有被遮蔽 token 的总数。
- 对
masked_pred 和 masked_tgt 进行归一化(F.normalize),然后计算余弦距离作为损失:
loss = 1.0 - (masked_pred * masked_tgt).sum(dim=-1)
return loss.mean()
归一化意味着我们只关心向量的方向(语义相似度),而不关心其模长。
build_hf_encoder 函数
加载 Hugging Face 上的预训练编码器,并返回模型及其隐藏层维度(从 config.hidden_size 读取)。
build_random_encoder 函数
此为冒烟测试(smoke test)专用。它会从头构建一个小型的 Transformer 编码器,包括嵌入层、位置编码和编码器层堆栈。注意,它只是一个普通的编码器架构,并非掩码语言模型。返回的对象具有 .last_hidden_state 属性,这是为了匹配 Hugging Face 模型输出的格式,方便后续代码统一处理。
总结与资源
这个实现刻意追求清晰易懂,因此没有包含更复杂的功能,如自定义注意力掩码、多视图数据集或混合训练目标。但它作为一个理解 JEPA 核心机制和快速上手的参考实现,是非常合适的。
原始的 LLM-JEPA 论文(https://arxiv.org/abs/2509.14252)进行了更深入的工作,例如将 JEPA 的嵌入预测目标与传统的 token 预测目标相结合,并利用了文本-代码等天然配对的视图。这些设计对于提升模型在下游任务上的性能非常重要,但也增加了复杂性,容易让人看不清最核心的机制。
本文的代码实现聚焦于 PyTorch 和自监督学习的核心思想,希望帮助你跨越从论文理论到动手实践的门槛。在 云栈社区 中,你还可以找到更多关于 深度学习 前沿架构和实战技巧的讨论与分享。
 发表于 2026-2-3 10:50:10
|
查看: 192|
回复: 0
发表于 2026-2-3 10:50:10
|
查看: 192|
回复: 0
