在一轮磕磕绊绊的硬件升级失败后,我又回到了老显卡的怀抱,并通过系统更新最终将驱动和 CUDA 版本提升到了 12.6。本文将详细记录在 Windows 10 22H2 系统上,搭建一套可用于并行编程与深度学习开发环境的过程,重点说明 CUDA 12.6 安装时的注意事项、cuDNN 的配置方法以及 PyTorch GPU 版本的正确安装与验证。
我的最终环境配置如下:
- 操作系统:Windows 10 22H2
- 开发工具:Visual Studio 2019 / 2022
- Python 环境:Anaconda3 (Python 3.13)
- 核心组件:CUDA 12.6 + cuDNN 8.9.7.29 + PyTorch 2.10.0 (CUDA 12.6)
二、CUDA 12.6 的安装与关键选项
CUDA 12.6 的基础安装步骤与前文所述基本一致,但在安装路径设置上更为简洁,通常只需指定一个主路径。强烈建议新手不要更改默认安装路径(通常为 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\),这能为后续的 cuDNN 配置和其他工具识别减少很多麻烦。
安装完成后,你可以使用 nvcc -V 等命令验证基础 CUDA 是否安装成功。然而,我遇到了一个问题:安装完成后,在 Visual Studio 2019 或 2022 中新建项目时,找不到 CUDA 12.6 的运行时项目模板。
查询资料后,有建议重装的,也有建议手动配置相关文件的。检查 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\extras\ 目录,发现其中根本没有 visual_studio_integration 文件夹。这意味着 Visual Studio 扩展支持没有被安装或安装失败。回想安装过程,我确实取消了“Visual Studio Integration”这个可选组件的安装。
于是,我重新运行 CUDA 安装程序,这次执行“修改”或“重装”,并仅选择安装“Visual Studio Integration”这一个组件,如下图所示:
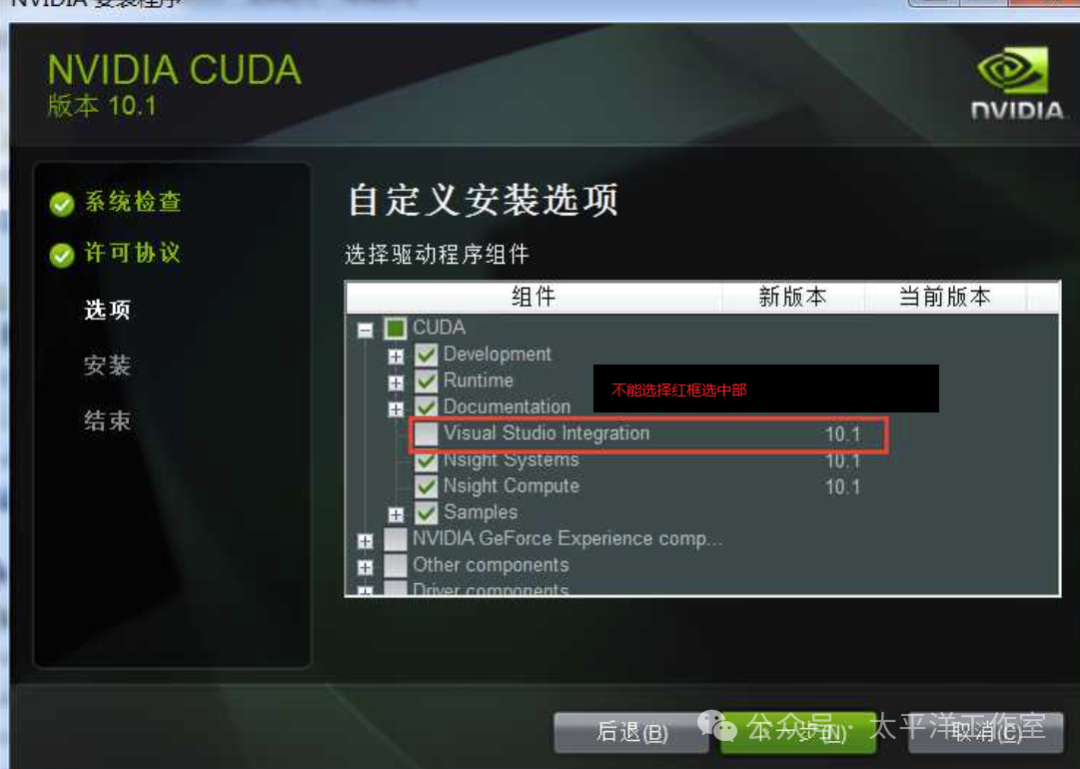
重新安装此组件后,再次启动 VS 2019/2022,新建项目时便出现了“CUDA 12.6 Runtime”模板。
重要提示:高版本 CUDA 安装程序通常会自动配置系统环境变量(如 CUDA_PATH、PATH),无需像网上许多旧教程那样手动添加。如果你检查环境变量,会发现它们已经设置好了。
三、cuDNN 的安装与“静默”配置
为了使用 GPU 加速的深度学习库,需要安装与 CUDA 版本对应的 cuDNN。我选择了 cuDNN 8.9.7.29 for CUDA 12.x。注意,cuDNN v8.9.x 是一个压缩包(Archive)版本,而非 exe 安装程序。
安装方法非常简单,属于“静默”配置:
- 解压下载的
cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip 文件。
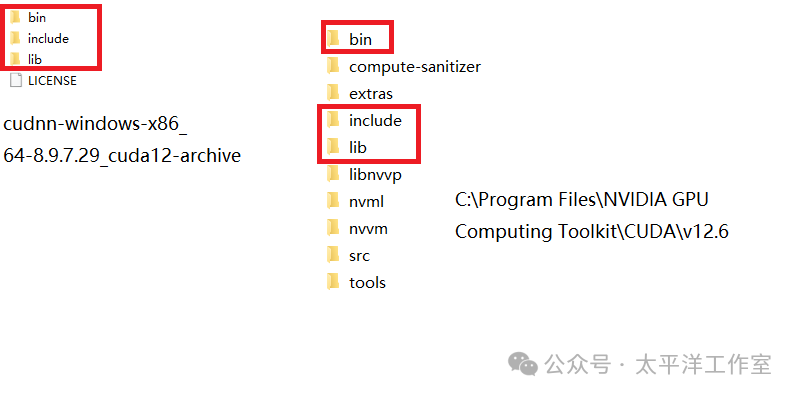
- 将其
bin、include、lib 目录下的所有文件,分别复制到 CUDA 的安装目录(如 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6\)下对应的同名文件夹中。
- 如果提示有重复文件,选择合并或替换即可。
操作完成后,目录结构应类似于下图:
完成后,cuDNN 本身没有明显的验证方式,通常需要依赖 PyTorch 或 TensorFlow 等框架来测试其是否正常工作。
四、PyTorch GPU 版的安装与“网络攻坚战”
PyTorch 的安装过程可谓一波三折。推荐使用 Anaconda 创建独立的虚拟环境进行安装,便于管理和隔离。
步骤 1:创建虚拟环境
conda create -n pytorch_gpu_env python=3.13 # 根据你的Anaconda Python版本调整
conda activate pytorch_gpu_env
步骤 2:获取安装命令
访问 PyTorch 官网,选择与你的环境匹配的配置。对于 CUDA 12.6,官网会生成类似下图的命令:
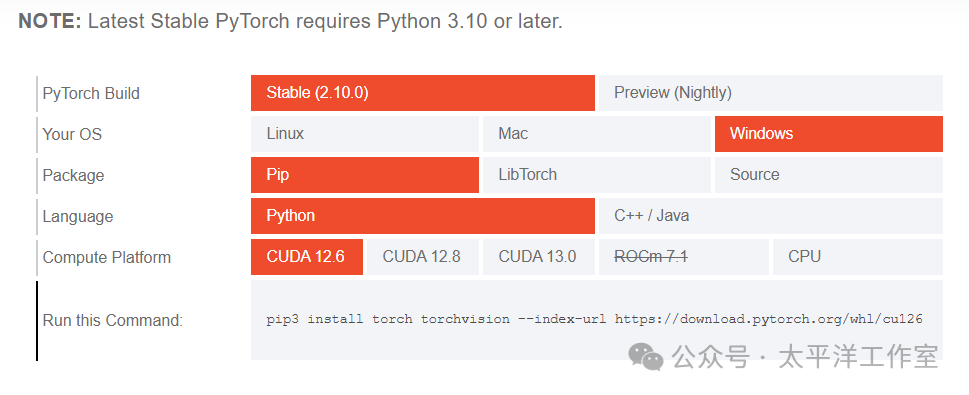
将底部生成的命令复制下来,例如:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
步骤 3:执行安装(可能需要“科学上网”)
在激活的虚拟环境命令行中粘贴并执行上述命令。然而,由于网络问题,你可能会遇到 SSL 错误或连接被重置的情况。
我尝试了更换为国内镜像源(如清华源),虽然安装成功了,但安装的居然是 CPU 版本。最后,通过“科学上网”方式,一分钟内就顺利完成了 GPU 版本的安装。这大概是国内开发者必须面对的“特色”难题之一。
步骤 4:验证安装
安装成功后,使用以下 Python 脚本进行验证,它可以全面检查 PyTorch、CUDA 和 cuDNN 的状态:
import torch
import sys
print("=" * 50)
print("PyTorch安装信息:")
print(f"PyTorch版本: {torch.__version__}")
print(f"CUDA可用: {torch.cuda.is_available()}")
print(f"CUDA版本: {torch.version.cuda}")
print(f"cuDNN启用: {torch.backends.cudnn.enabled}")
print(f"GPU数量: {torch.cuda.device_count()}")
if torch.cuda.is_available():
print(f"当前GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU内存: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
# 测试cuDNN
x = torch.randn(1, 3, 224, 224, device='cuda')
try:
# 尝试一个使用cuDNN的操作
x = torch.nn.functional.conv2d(x, torch.randn(64, 3, 3, 3, device='cuda'))
print("cuDNN操作测试: 成功")
# 再次检查版本
print(f"cuDNN版本: {torch.backends.cudnn.version()}")
except Exception as e:
print(f"cuDNN操作测试失败: {e}")
如果一切配置正确,你将看到类似下面的输出,其中关键项均为 True 并显示了正确的版本号:
==================================================
PyTorch安装信息:
PyTorch版本: 2.10.0+cu126
CUDA可用: True
CUDA版本: 12.6
cuDNN启用: True
GPU数量: 1
当前GPU: NVIDIA GeForce GTX 960
GPU内存: 4.29 GB
cuDNN操作测试: 成功
cuDNN版本: 91002
安装中断处理:pip 安装支持断点续传。如果安装因网络中断,重新执行命令即可继续。
完全卸载:如果安装混乱想重来,最彻底的方法是删除整个虚拟环境:
conda remove -n pytorch_gpu_env --all
五、旧有 CUDA 项目的兼容性测试
在 VS2019/2022 中打开一个旧版本(如 CUDA 9.1)的 CUDA 项目,可能会直接报错,因为找不到旧版 CUDA 的工具链。理论上,Windows 可以支持多版本 CUDA 并存,通过环境变量或项目设置来指定版本。但本次我未保留旧版本,因此选择了直接在新环境上测试。
新建一个“CUDA 12.6 Runtime”项目,将一段包含内核函数和流回调的测试代码(一段标准的向量加法示例)拷贝进去。这段代码涉及了内存管理、异步操作和回调函数等概念。
编译运行正常,但出现了一个链接警告:
LINK : warning LNK4098: 默认库“LIBCMT”与其他库的使用冲突;请使用 /NODEFAULTLIB:library
这与运行时库(MT/MD)的选择有关。消除警告的方法如下:
- 在 Visual Studio 中,右键点击项目 -> “属性”。
- 转到“配置属性” -> “链接器” -> “命令行”。
- 在“其他选项”框中添加:
/NODEFAULTLIB:LIBCMT /NODEFAULTLIB:LIBCMTD
- 重新编译,警告即会消失。
六、总结
至此,我们成功在 Windows 10 系统上搭建了基于 CUDA 12.6、cuDNN 和 PyTorch 的完整 GPU 开发与深度学习环境。整个过程的关键点在于:
- CUDA安装:务必勾选“Visual Studio Integration”组件,否则 VS 中无法创建 CUDA 项目。
- cuDNN配置:对于压缩包版本,手动合并文件到 CUDA 目录即可。
- PyTorch安装:官网生成命令最准确,但国内网络环境可能需要特殊方式才能成功安装 GPU 版本。
- 环境验证:使用提供的验证脚本,可以一目了然地确认所有组件是否正确安装并协同工作。
这套环境已经能够满足大多数并行计算和深度学习模型的实验与开发需求。未来可以在此基础上进一步配置 LibTorch (C++ API) 或 TensorFlow 等框架,充分利用 GPU 的算力。如果在配置过程中遇到其他问题,欢迎在云栈社区的技术论坛与大家交流探讨。
 发表于 2026-2-3 07:16:12
|
查看: 338|
回复: 0
发表于 2026-2-3 07:16:12
|
查看: 338|
回复: 0
