在阅读深度学习相关的文章或论文时,你是否也经常被这几个术语绕晕?它们被频繁提及,却又似乎界限模糊:
- 前馈神经网络(Feedforward Neural Network)
- FNN(Fully Connected Neural Network)
- MLP(Multi-Layer Perceptron)
这几个词常常被混着使用,有时候看起来像是同义词,有时又似乎有所区别。于是,一个典型的困惑就产生了:它们到底是不是一回事?如果不是,区别又在哪里?
这篇文章,我们将从概念层级、结构差异和历史起源三个维度出发,把这个问题彻底讲清楚。
一、核心结论先行
如果你只想快速了解三者关系,可以直接看这个结论:
前馈神经网络是一个描述“信息流动方式”的大类;
FNN 是其中一种“连接方式”的具体实现;
MLP 是 FNN 最经典、最教科书式的多层实例。
用一句更直观的集合关系来概括,那就是:
MLP ⊂ FNN ⊂ 前馈神经网络
但为什么会产生这么多名字?它们具体指代什么?我们一步一步来剖析。
二、什么是前馈神经网络(Feedforward Neural Network)?
前馈神经网络描述的是一种信息传播的范式,它的核心定义非常简单:
信息从输入层开始,经过若干中间层,单向地流向输出层,整个过程中不存在任何回环或状态反馈。
抓住这个关键点就足够了:
- ❌ 没有循环连接
- ❌ 没有时间依赖
- ❌ 没有“上一时刻的状态”需要记忆
只要满足“信息单向流动,无反馈”这一条件,它就可以被归入前馈网络的范畴。
这里有一个非常重要的认知纠正:“前馈”不等于“全连接”。
许多现代网络架构都是前馈网络,但它们并不一定是全连接的:
- CNN(卷积神经网络):是前馈网络(信息单向传播)。
- Vision Transformer:是前馈网络。
- Transformer 中的 FFN(前馈网络)模块:顾名思义,也是前馈网络。
但它们都利用了特定的结构(如卷积、注意力)进行局部或稀疏连接,而非层间全连接。
所以,“前馈”是一个在概念层级上更大的分类,它只关心信息流的方向。
三、什么是 FNN(Fully Connected Neural Network)?
FNN 强调的则是另一件事:网络层之间的连接方式。
它特指相邻两层之间是全连接(Dense / Linear)的。
在 FNN 中,上一层的每一个神经元都与下一层的每一个神经元相连。假设上一层有 n 个神经元,下一层有 m 个神经元,那么它们之间的权重参数数量就是 n × m。
这是一种最“直接”、也最“暴力”的连接方式,其特点是:
- 不利用输入数据的空间结构(不像 CNN 那样关注局部特征)。
- 不利用时间序列结构(不像 RNN 那样处理时序依赖)。
- 直接在特征维度上进行任意的线性组合与变换。
因此,我们可以明确:FNN 是前馈网络的一种具体实现方式(即,用全连接的方式来实现信息的前向传播)。
四、什么是 MLP(Multi-Layer Perceptron)?
MLP,即多层感知机,可以理解为 FNN 的经典形态。
它是由多层全连接层,以及层间的非线性激活函数所构成的前馈网络。
一个典型的 MLP 结构如下:
Input → Linear → Activation → Linear → Activation → ... → Output
它的关键特征包括:
- 至少含有一层隐藏层(这是“多层”的体现)。
- 每一层都是全连接层(这是 FNN 的属性)。
- 激活函数(如 ReLU, Sigmoid)引入了非线性,使得网络能够拟合复杂函数。
从现代的视角来看:MLP 就是最标准、最教科书式的 FNN。当人们提到 FNN 时,脑海中浮现的往往是 MLP 的结构。
五、追根溯源:MLP 的诞生
要深刻理解 MLP,有必要回顾一下它的历史。
- 单层感知机(Perceptron)
1957年,Frank Rosenblatt 提出了感知机模型。它本质上是一个线性分类器,其数学表达通常如下:
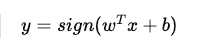
但它的能力有限,**只能解决线性可分的问题**。
-
致命缺陷:XOR 问题
单层感知机无法解决简单的“异或”问题,这个缺陷在当时几乎给神经网络研究判了“死刑”。
-
救星:多层感知机(MLP)
后来人们意识到,只要引入隐藏层和非线性激活函数,就可以将线性不可分的问题在更高维的空间中进行拆解和解决。这就是 MLP 的核心思想。
而真正让 MLP 从理论走向实践、变得可训练的关键,是反向传播算法。它使得“多层”、“全连接”、“非线性”这些特性第一次在工程上变得可行。
六、为什么今天还在反复讨论 MLP?
你可能会问,现在 Transformer、CNN、GNN 层出不穷,为什么还要反复讲这个“古老”的 MLP?
原因其实很深刻:
-
它是现代模型的基石组件
几乎你叫得上名的模型,最后都会用到 MLP 或它的变体:
- CNN 最后的分类头(全连接层)。
- Transformer 中的 FFN 模块(本质上就是一个 MLP)。
- GNN 中的节点更新网络。
- 强化学习中的策略网络或价值网络头部。
它们都可以看作是 MLP 被嵌入到不同结构范式中所扮演的角色。
-
它是“模型表达能力”的核心载体
在一个模型中,结构性模块(如 Attention、Conv)决定了信息如何流动和交互;而 MLP 则决定了这些信息能被计算、转换成多复杂的表示。
这也解释了为什么在大语言模型(LLM)中,FFN(MLP)模块往往占据了总参数量的 50% 以上,是绝对的参数量大户。
七、关系总览:一张表厘清
| 名称 |
关注重点 |
概念层级 |
| 前馈神经网络 |
信息单向流动,无反馈 |
最大概念(描述信息流范式) |
| FNN |
层间全连接的结构 |
中间概念(描述连接方式) |
| MLP |
多层全连接+非线性的具体实现 |
具体实例(最经典的 FNN) |
八、最终总结
用一句话概括三者的关系:
前馈神经网络描述的是“信息有没有循环”,
FNN 描述的是“神经元之间怎么连”,
MLP 则是最经典、最广为人知的那一种全连接前馈网络。
理解了这三者的层次关系,再回过头去看 Transformer 论文里的 FFN、大模型架构图中的 MLP Block,你会发现它们并不神秘,也不陌生。MLP 从未过时,它只是换了一个更宏大的舞台,继续扮演着计算与表达的核心角色。这也正是基础概念的价值——它们构成了我们理解一切复杂系统的坚实基石。在像云栈社区这样的技术论坛中深入探讨这些基础,能帮助开发者更好地掌握前沿技术的本质。
相关阅读(原文已存在且强相关的技术外链,予以保留):
 发表于 2026-2-5 05:42:39
|
查看: 480|
回复: 0
发表于 2026-2-5 05:42:39
|
查看: 480|
回复: 0
