当我们在《赛博朋克2077》的夜之城中流连忘返,或者惊叹于 ChatGPT 生成的精妙回答时,很少有人意识到这背后正在进行着怎样规模的数字狂欢。为了支撑现代图形渲染和人工智能,GPU 架构经历了一场从“方阵士兵”到“特种部队”的静默革命。本文将深入解剖 GPU 的微观架构,从 SIMD 的物理局限到 SIMT 的逻辑突围,并揭示 GPGPU 是如何凭借“极度并行”的哲学,成为现代 AI 产业的心脏。
第一章:不可思议的算力规模
在进入枯燥的架构图解之前,我们需要先建立一个量级概念。现代计算的规模,早已超出了人类直觉的想象范畴。
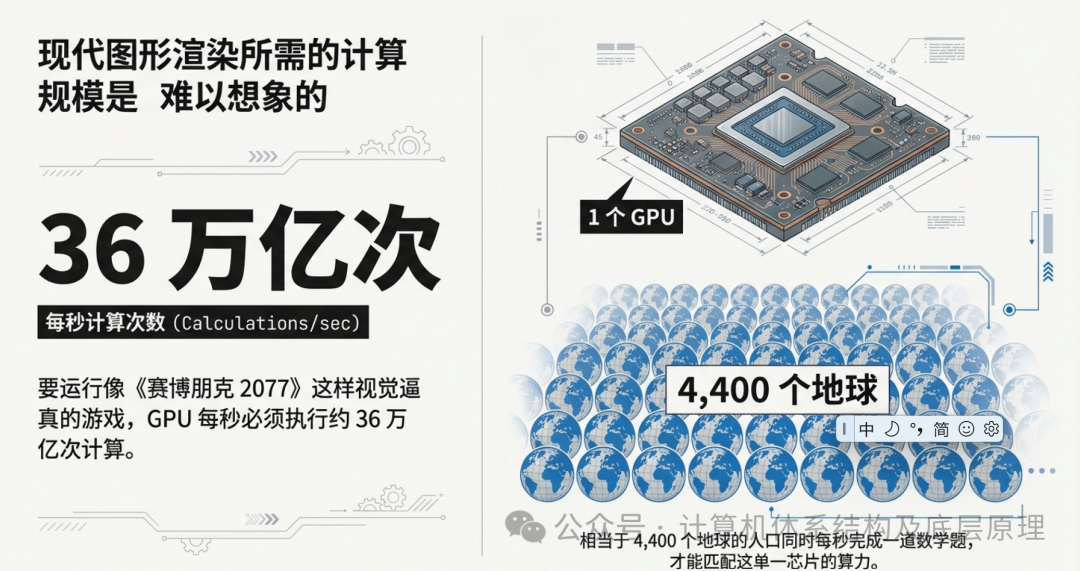
让我们把时间拨回 1996 年,那是《超级马里奥 64》诞生的年代。那时的 3D 游戏简单纯粹,多边形棱角分明,算力需求约为每秒 1 亿次计算(100 Million Ops)。而在仅仅二十多年后的 2020 年,为了在 4K 分辨率下流畅运行光追大作《赛博朋克 2077》,显卡每秒必须执行惊人的 36 万亿次运算(36 Trillion Ops)。

36 万亿次,这个数字冷冰冰的,没有任何实感。为了让你理解这个量级,我们做一个疯狂的各种假设:
如果我们将全地球 4,400 个 平行宇宙中的所有人口(约 34 万亿人)集合起来,每个人每秒钟做一道复杂的数学题,那么这 4,400 个地球的全人类总算力,才刚刚能匹配一颗 RTX 3090 芯片的运算能力。
这种恐怖的算力增长,并不是靠单纯提高核心频率实现的(摩尔定律已近黄昏),而是源于一种计算哲学的根本性胜利——极度并行(Embarrassingly Parallel)。
第二章:喷气机与远洋货轮 —— CPU 与 GPU 的本质分歧
要理解 GPU 的架构,首先要明白它为什么长得和 CPU 完全不一样。
CPU(中央处理器)的设计理念是“全能与低延迟”。它像是一架超音速喷气式客机。它的核心数量很少(通常 8-24 核),但每个核心都极其强壮,主频极高,并且拥有复杂的控制逻辑,能够处理各种突发的、逻辑混乱的任务(比如运行操作系统、响应鼠标点击、打开复杂的网页)。它的目标是快——让单个乘客(指令)以最快速度到达目的地。
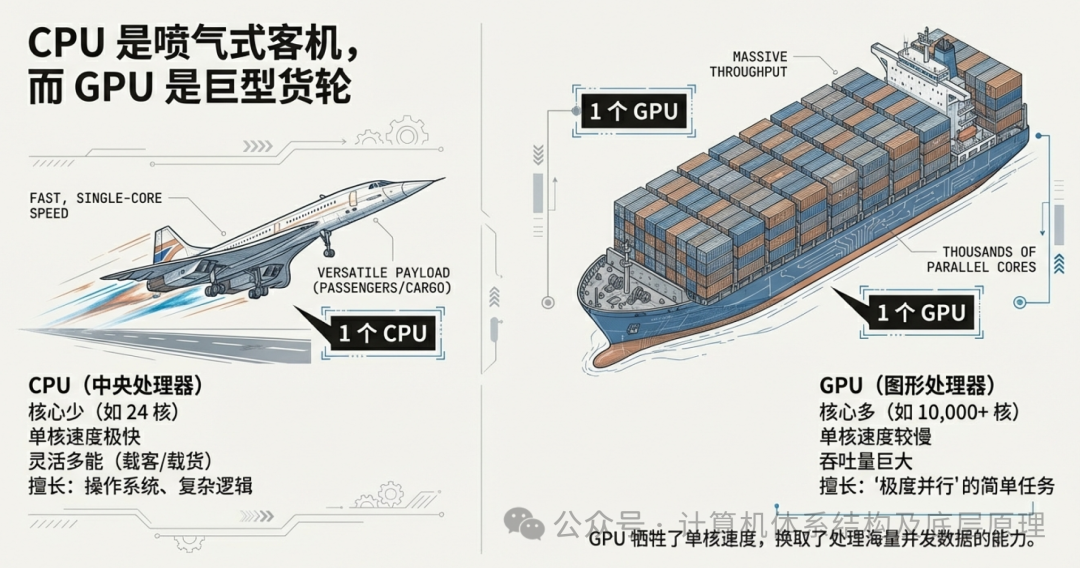
而 GPU(图形处理器)则是为了完全不同的目的而生。它是一艘巨型远洋货轮。它的单核速度并不快,甚至有些迟钝,但它拥有成千上万个核心(如 RTX 3090 拥有 10,000+ 个核心)。它的目标不是让一个集装箱快速到达,而是一次性运送十万个集装箱。
这种设计是为了解决一类特定的问题:极度并行问题。
在图形渲染中,屏幕上有 800 万个像素(4K),或者场景中有 1000 万个多边形。改变一个像素的颜色,通常不需要知道另一个像素是什么颜色。这种“互不依赖、可无限拆分”的任务,就是 GPU 的主战场。
第三章:SIMD —— 整齐划一的“方阵士兵”
早期的 GPU 为了实现这种海量吞吐,采用了最简单粗暴的并行策略:SIMD(Single Instruction Multiple Data,单指令多数据)。
3.1 什么是 SIMD?
SIMD 的核心逻辑非常直观:既然有成千上万个数据需要做相同的处理,那为什么不发布一条指令,让大家同时执行呢?让我们来看一个经典的 3D 渲染案例:牛仔帽的坐标变换。
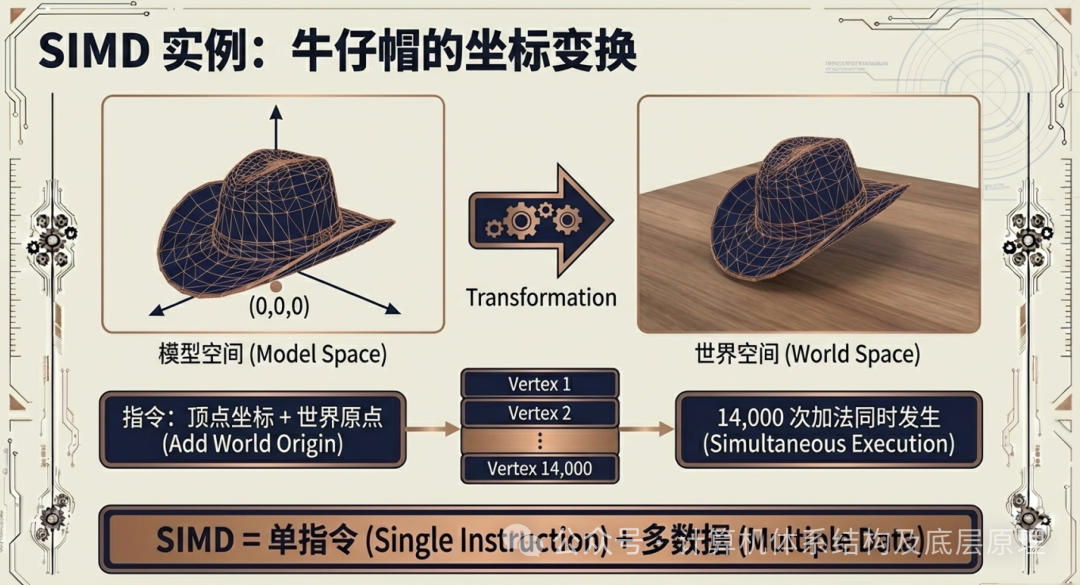
想象一个 3D 场景中的牛仔帽,它由大约 14,000 个顶点(Vertex)构成。在数据层面,这顶帽子只是一堆 (x, y, z)坐标的集合。现在,我们需要把这顶帽子从“模型空间”(以帽子中心为原点)移动到“世界空间”(以游戏场景中心为原点)。
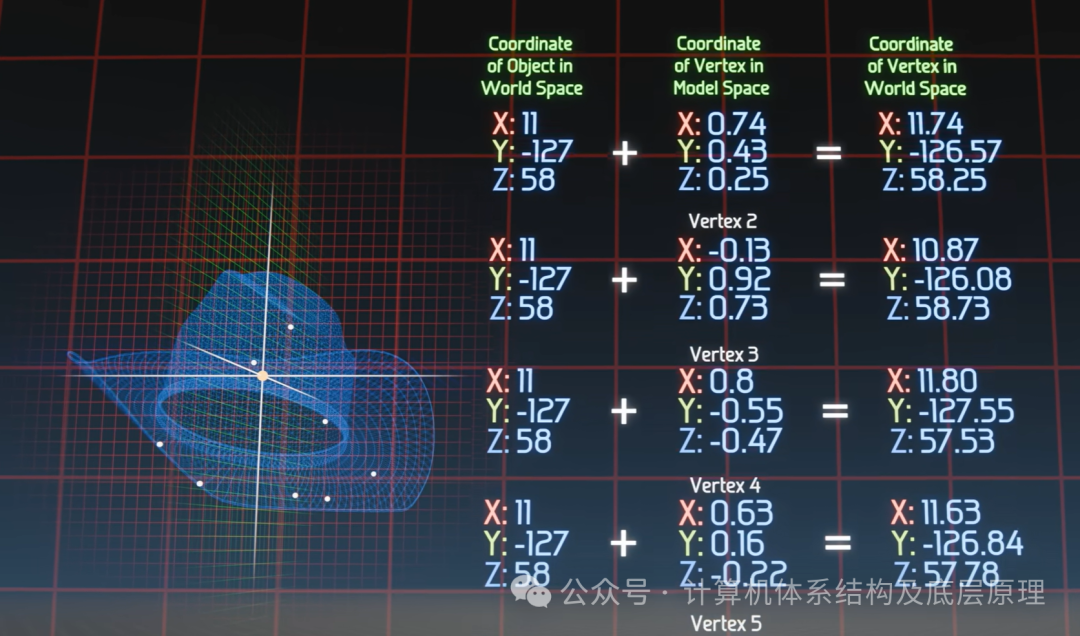
在数学上,这意味着我们需要对这 14,000 个顶点同时加上一个坐标偏移量 (dx, dy, dz)。
- 单指令(Single Instruction): “将当前坐标加上偏移量”。
- 多数据(Multiple Data): 这条指令被瞬间复制,并同时应用到帽子的 14,000 个顶点上。
在硬件内部,这就像是一个指挥官对着一万名士兵大喊:“向前一步走!”。一万名士兵(数据)在同一瞬间完成了动作。这就是 SIMD 的威力,它能在一个时钟周期内完成海量的加法运算。
而这仅仅是一帽子的顶点计算,一个3D场景如下图有5629个不同的Object 需要被计算。

然后所有的这些 Objects 形成了大约8,300,000个顶点坐标信息,最后需要25,000,000次坐标矩阵变化,这就显现出来SIMD的优势。

这些物体在3D世界里面作任何的动作,放大,缩小,旋转,坐标变换都要重新计算。

而且这些坐标变换只是3D Pipeline 的一个小步骤而已。 而每步都是大量的并行计算。
3.2 SIMD 的阿喀琉斯之踵:锁步(Lockstep)
然而,传统的 SIMD 有一个巨大的缺陷。在 SIMD 架构中,几十个线程被打包成一个“线程束”(Warp,在 NVIDIA 架构中通常为 32 个线程)。这个 Warp 就像是古希腊的重装步兵方阵。方阵中的所有士兵必须步调绝对一致(Lockstep)。如果所有士兵都走平路(执行简单的加法),那效率极高。但是,如果遇到复杂的逻辑分支(Branching)呢?
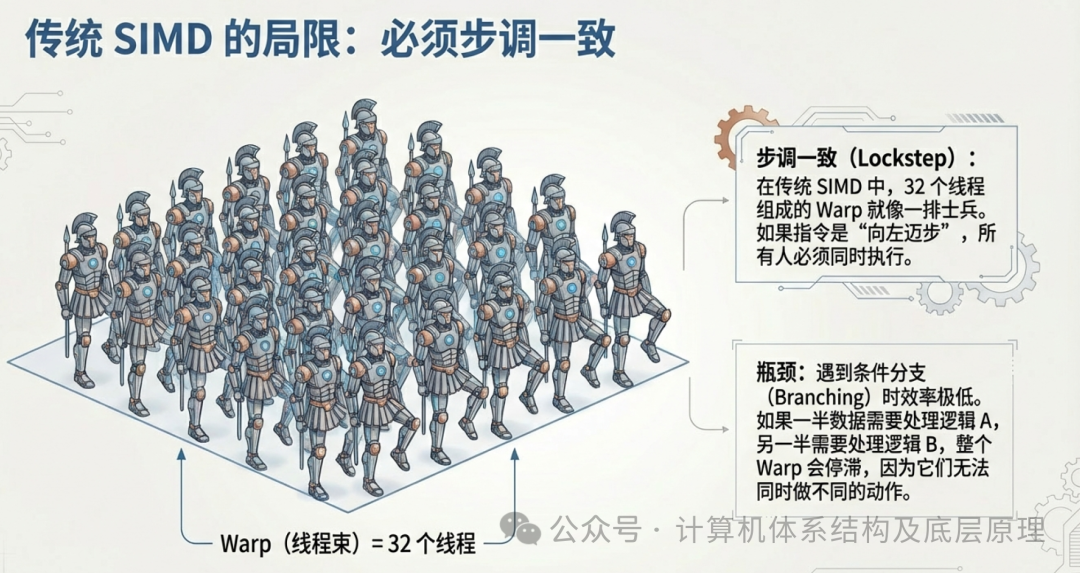
假设代码中出现了 if-else 语句:
- 如果顶点被光照亮(条件 A),则执行复杂的颜色计算。
- 如果顶点在阴影中(条件 B),则直接显示黑色。
在一个 Warp 中,可能有一半的线程满足条件 A,另一半满足条件 B。
在严格的 SIMD 锁步机制下,硬件无法同时执行这两种不同的动作。
- 首先,所有满足条件 A 的线程执行计算,而满足条件 B 的线程必须暂停(Stall)等待。
- 接着,满足条件 B 的线程执行,满足条件 A 的线程暂停。
- 最后,它们重新汇合。
这种现象被称为“线程束发散”(Warp Divergence)。一旦发生发散,GPU 的并行效率就会大打折扣,因为总有一部分核心在“摸鱼”等待队友。这使得传统 SIMD 极难处理复杂的非图形任务。
第四章:SIMT —— 赋予士兵“独立思考”的能力
为了解决 SIMD 的死板,NVIDIA 在其现代架构(大约从 2006 年 G80 架构开始萌芽,并在后续架构中不断完善)中引入了 SIMT(Single Instruction Multiple Threads,单指令多线程) 模型。这是 GPU 进化史上的分水岭。它让GPU从单纯的“绘图卡”变成了“通用计算器”。
4.1 从“木偶”到“特种兵”
SIMT 在保留了 SIMD 高吞吐优势(依然是大量线程执行同一指令流)的同时,引入了几个关键的变革,让线程获得了“自由”:
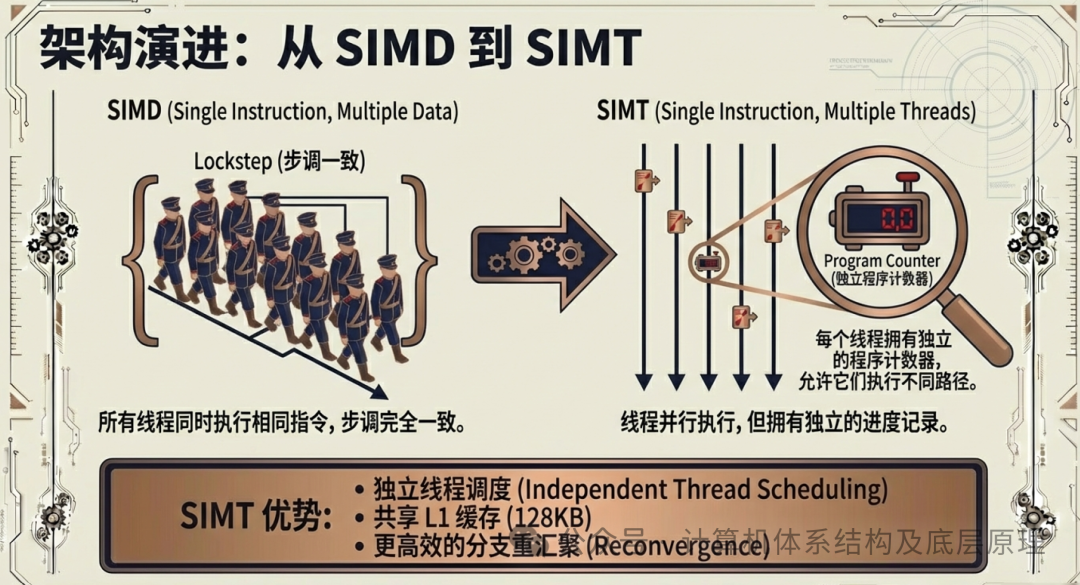
- 独立的程序计数器(Program Counter, PC):
在传统 SIMD 中,整个方阵共享一个大脑(PC),大家只能听同一个口令。而在 SIMT 中,每个线程(或者说每个最小执行单元)都拥有了独立的逻辑状态记录。这意味着虽然它们大部分时间依然同步行动,但每个线程都知道自己“走到哪一步了”。独立的线程调度(Independent Thread Scheduling):
当遇到 if-else 分支时,SIMT 架构允许线程暂时“分头行动”。现代 GPU(如 Volta 架构及之后)甚至引入了更高级的独立线程调度机制,硬件可以更灵活地管理不同分支的执行进度,并高效地在分支结束后进行重汇聚(Reconvergence)。
- 共享 L1 缓存与数据交换:
SIMT 允许一个流式多处理器(SM)内的线程共享高速 L1 缓存(在 GA102 中为 128KB)。这打破了数据孤岛。以前,士兵 A 算出的结果,士兵 B 很难直接拿来用。现在,通过共享内存,线程之间可以进行高效的数据协作。
总结来说: 如果说 SIMD 是踢正步的仪仗队,SIMT 就是佩戴了单兵通讯系统的特种作战群。他们依然听从总指挥的宏观调配(单指令),但在遇到具体地形障碍(逻辑分支)时,允许单兵进行战术机动,最后再从容归队。
这种灵活性,是 GPU 能够运行复杂的 AI 算法和通用计算程序的基石。
第五章:解剖怪兽 —— GA102 芯片的物理架构
理解了 SIMT 的逻辑,我们再来看看这种逻辑是如何固化为物理实体的。以 NVIDIA 的 GA102 核心(RTX 3090 的心脏)为例,这是一座由 283 亿个晶体管 构成的精密迷宫。
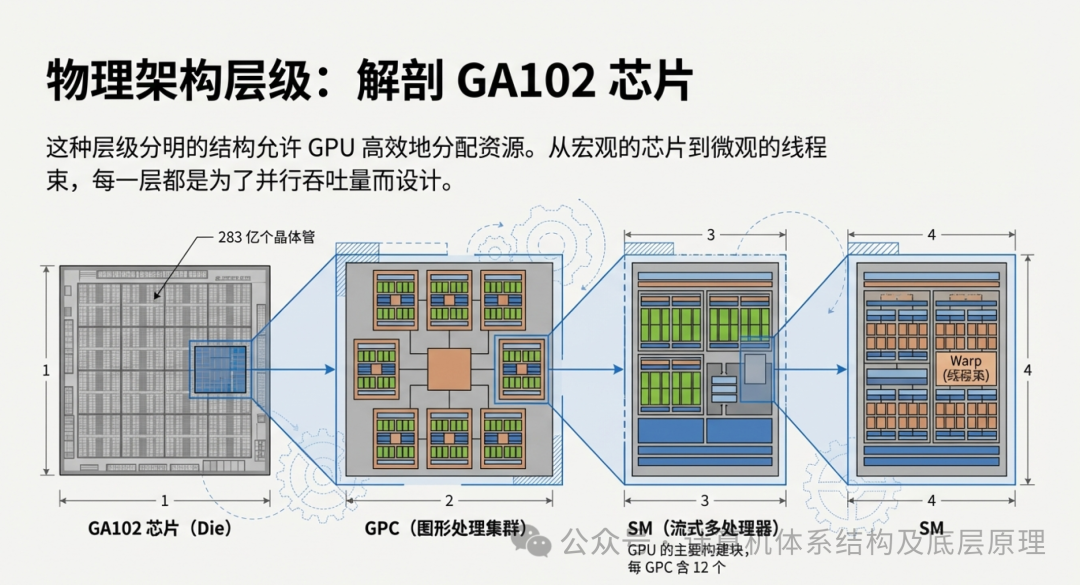
这座迷宫有着严格的层级结构,像极了俄罗斯套娃:
- GPC(图形处理集群): 整个芯片包含 7 个 GPC。你可以把每个 GPC 想象成一个独立的“工业区”。
- SM(流式多处理器): 每个 GPC 包含 12 个 SM。SM 是 GPU 的核心干活单位,相当于一个拥有全套设施的“大型车间”。 每个 SM 拥有自己的指令调度器、L1 缓存和寄存器堆。
- 关键点: SM 是 SIMT 模型执行的最小全功能模块。
- Warp(线程束): 每个 SM 被划分为 4 个分区,每个分区负责调度一个 Warp(32 个线程)。
- CUDA 核心: 这是最底层的“工人”。在 GA102 中,一个 SM 包含 128 个 CUDA 核心。
5.1 三种核心,三种使命
现代 GPU 不再只有一种核心。为了应对不同的数学问题,GA102 GPU SM 内部集成了三种专用的处理单元:
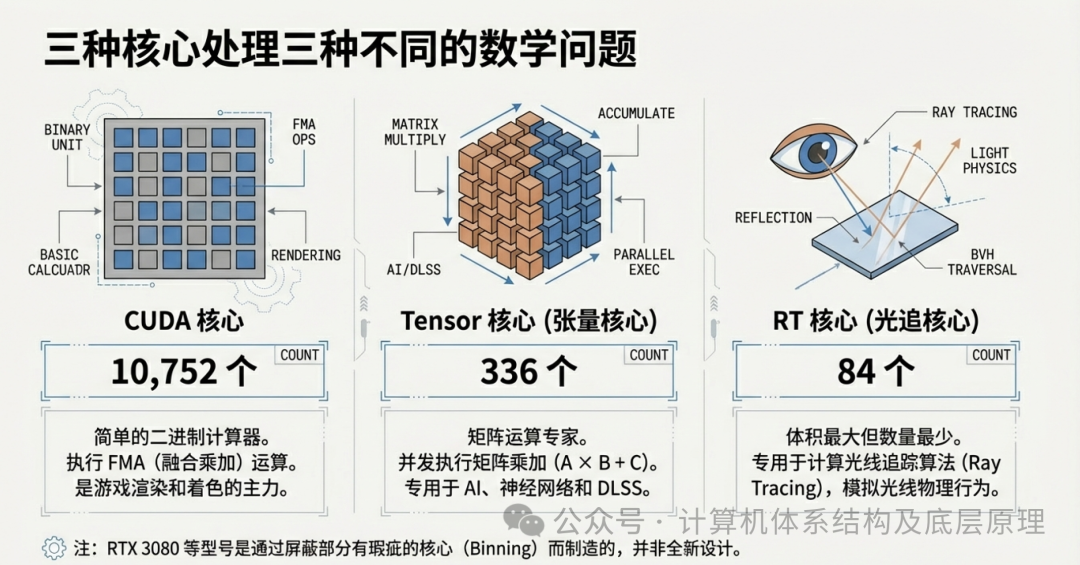
- CUDA Core(流处理器):
a. 数量: 10,752 个(RTX 3090 Ti)。
b. 职责: 通用计算的“万金油”。擅长做 FP32(单精度浮点)运算,也就是最基础的 A * B + C(FMA 运算)。它们是传统游戏渲染和通用计算的主力。
- RT Core(光追核心):
a. 数量: 84 个。
b. 职责: 极其特殊的专用电路。它们只做一件事:计算光线与三角形是否相交。这是光线追踪技术中最耗时的部分,如果用 CUDA 核心硬算,帧率会跌成 PPT。RT Core 的加入让实时光追成为可能。
- Tensor Core(张量核心):
a. 数量: 336 个。
b. 职责: AI 时代的真正主角。 我们稍后会详细讲它。
第六章:GPGPU 与 AI —— 极度并行的终极舞台
如果 GPU 只是为了玩游戏,那它永远只能是“显卡”。但 SIMT 的出现,开启了 GPGPU(General-Purpose computing on GPU,通用图形处理器计算) 的大门。人们发现,不仅是图形渲染,世界上还有很多问题在本质上是“极度并行”的。
其中最著名的两个应用,就是比特币挖矿和人工智能(AI)。
6.1 挖矿:暴力的彩票游戏
比特币挖矿本质上是在玩一个暴力猜数字的游戏(哈希碰撞)。你需要不断地尝试一个随机数(Nonce),代入 SHA-256 算法,看生成的结果是否前面有足够多的 0。
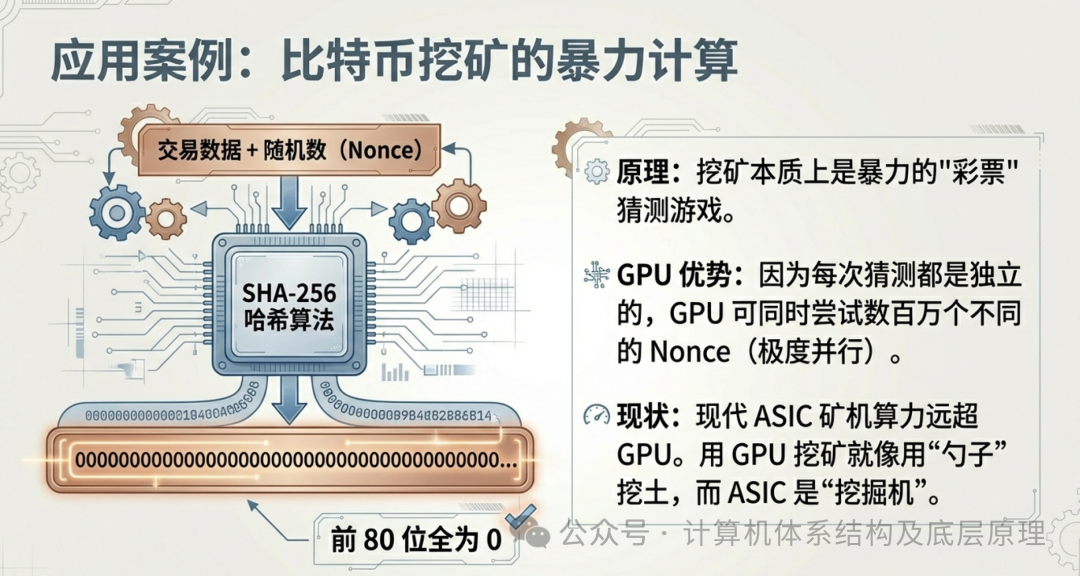
每一次猜测都是完全独立的。第一次猜错不影响第二次猜测。这简直是为 GPU 量身定做的任务。GPU 的数千个核心可以同时尝试数千个不同的随机数。这就是为什么前几年显卡价格飞涨的原因——它们是完美的数字矿铲。
6.2 AI 与张量核心:矩阵运算的艺术
然而,真正让 GPU 封神的,是 AI,特别是深度学习。
神经网络的本质是什么?无论是识别猫的图片,还是 GPT-4 写诗,其底层的计算 99% 都是矩阵乘法(Matrix Multiplication)。想象两个巨大的矩阵相乘。这涉及到成千上万次的“乘法求和”操作。而且,这些操作也是极度并行的——计算矩阵左上角的值,不需要等待右下角的值算完。
为了加速这种特定的运算,NVIDIA 在 GPU 中加入了 Tensor Core(张量核心)。
- 普通 CUDA 核心: 做一次乘法,再一次加法,需要多个时钟周期,像是在用计算器按 1 * 2 + 3。
- Tensor Core: 这是一个专用的矩阵计算器。它可以在一个时钟周期内,完成一个 4 4矩阵的完整乘加运算(D = A B + C)。在 AI 训练和推理中,这种效率的提升是指数级的。正是 Tensor Core 的存在,使得现在的 GPU 不再仅仅是图形渲染器,而是AI 加速器。
6.3 喂饱怪兽:HBM 与带宽的瓶颈
有了能在瞬间吞噬数据的 Tensor Core,传统的显存(VRAM)开始跟不上了。如果核心计算太快,而数据还在内存条上排队传输,核心就会闲置。这就是为什么顶级 AI 芯片(如 H100)不使用普通的 GDDR 显存,而是使用 HBM(High Bandwidth Memory,高带宽存储器)。
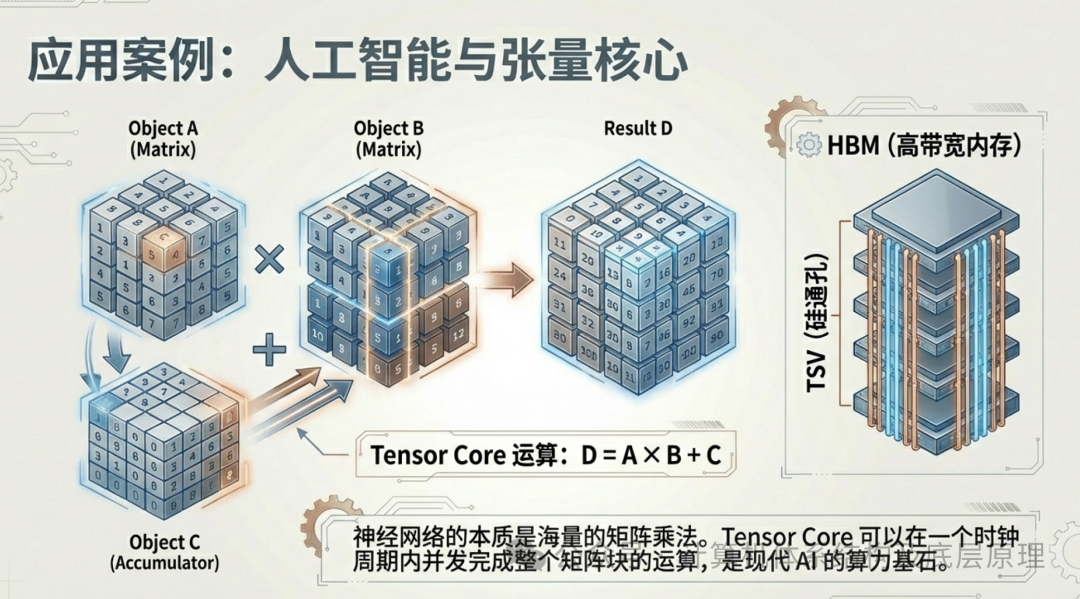
HBM 技术通过“硅通孔”(TSV)技术,像盖摩天大楼一样将存储芯片垂直堆叠起来,并直接安放在 GPU 核心旁边。这提供了像高速公路一样宽阔的数据通道(带宽可达数 TB/s),确保 Tensor Core 这头吞金兽永远有数据可以“吃”。
结语:从像素到智慧
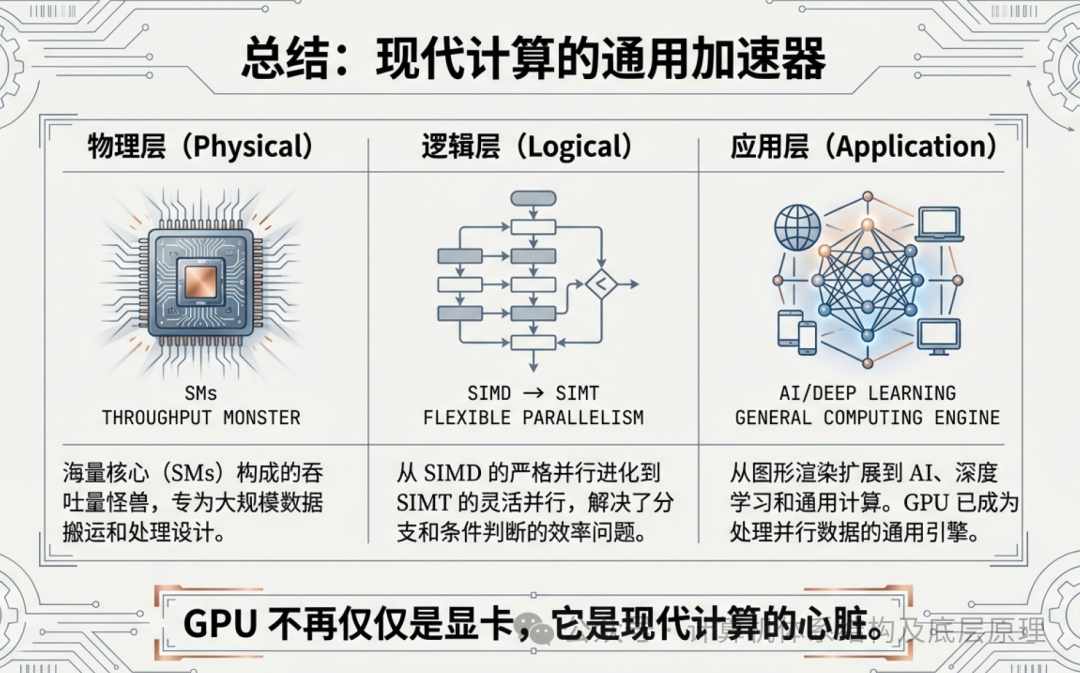
回顾 GPU 的发展史,我们看到了一条清晰的进化路线:
- SIMD 时代: 为了处理海量像素,GPU 变成了整齐划一的“方阵士兵”,牺牲了灵活性换取了极致的吞吐量。
- SIMT 时代: 为了处理更复杂的图形效果,GPU 引入了独立线程逻辑,变成了灵活的“特种部队”,无意中开启了通用计算的大门。
- AI 时代: 恰逢神经网络崛起,其对矩阵运算的极度并行需求,与 GPU 的架构完美契合。加上 Tensor Core 和 HBM 的硬件加持,GPU 最终成为了现代人工智能的物理基石。
今天,当我们谈论 GPU 时,我们谈论的不再仅仅是帧率和分辨率。我们谈论的是天气模拟、药物研发、自动驾驶以及通用人工智能的未来。那个曾经只为了让我们在屏幕上看到逼真爆炸效果的芯片,如今正在计算着人类的未来。这,就是架构演进的力量。
如果您对更多关于计算机系统架构的深度内容感兴趣,欢迎在云栈社区与众多技术爱好者一起交流探讨。
 发表于 2026-2-1 19:55:24
|
查看: 196|
回复: 0
发表于 2026-2-1 19:55:24
|
查看: 196|
回复: 0
