人工智能的蓬勃发展正在引发一场深层次的能源危机。你知道吗?未来AI的耗电量甚至可能超过一些中等规模国家的总用电量。随着全球数据中心竞相满足AI对算力那近乎永无止境的需求,一场关于计算架构的根本性变革正在悄然发生。
这其中的一个核心解决方案,便是寻求用一种更高效的物质——光——来逐步取代几十年来一直为计算提供动力的传统电气互连。
根据高盛(Goldman Sachs)的预测,到2030年,全球数据中心的电力需求将激增160%,达到每年945太瓦时。这个数字是什么概念?它相当于日本全国一年的总电力消耗。
问题的根源远不止软件层面的效率低下。据彭博社报道,一个典型的大型AI训练设施内部可能装有数十万颗NVIDIA H100这样的高性能芯片。单颗H100芯片的功耗就高达700瓦,这几乎是普通家用电视机功耗的八倍。如果再算上维持其稳定运行所必需的庞大冷却系统,一些超大规模数据中心的耗电量,足以抵得上3万户普通家庭的用电总和。这也促使了一些科技巨头开始严肃地考虑,是否要投资建设专用的核电站来为自己供电。
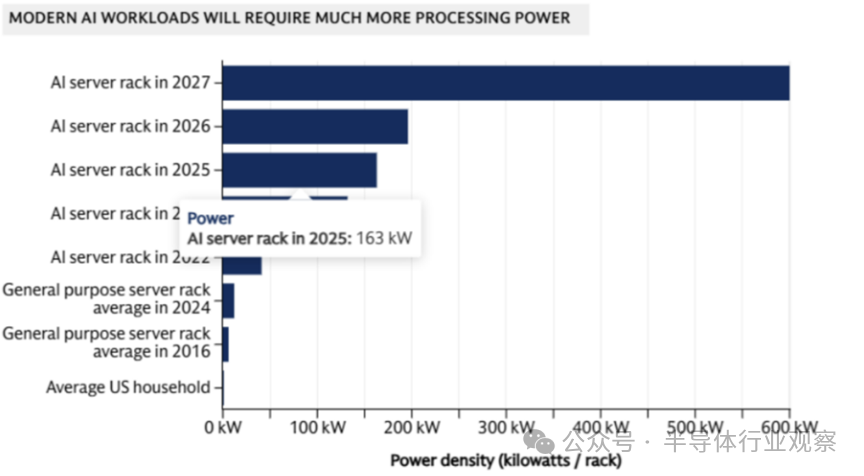
图表显示了AI服务器机架惊人的功率密度增长趋势,远超通用服务器和家庭用电。
应对这一挑战,已经无法通过小修小补来实现,它需要我们从根本上重新思考芯片的设计以及它们彼此连接的方式。硅光子学——这项利用光子(光粒子)来传输数据的技术——有望在传输速度和能源效率上,对传统的电互连实现显著的超越。现代精密的半导体制造工艺,使得这种技术转变成为可能,为实现下一代既节能又高性能的计算系统铺平了道路。
硅光子学:从“电线”到“光路”的根本转变
硅光子学技术重新定义了数据在计算系统中的传输方式。它不再依赖铜线中电子的移动,而是利用光子在集成于芯片之上的硅基波导中穿梭。你可以把这些硅波导想象成纳米尺寸的光纤,它们被直接“雕刻”在芯片内部。
这种转变带来的效率提升是革命性的。据研究,光互连在传输每比特数据时,仅消耗0.05至0.2皮焦耳的能量。相比之下,相同传输距离下,电互连的能耗要高出一个甚至几个数量级。随着传输距离的增加(即便只是在单个芯片封装内部),光子学的能效优势会变得更具压倒性。
市场的反应也印证了其前景。自2023年底以来,全球最大的芯片代工厂台积电已连续发表多篇关于硅光子学集成技术的研究论文。该公司已公开宣布与英伟达(NVIDIA)建立合作,旨在将光互连架构集成到下一代AI计算产品中。行业分析机构Yole Group预测,硅光子学市场规模将从2023年的约9500万美元,暴增至2029年的8.63亿美元以上,年复合增长率高达45%,反映出该技术即将迎来的快速商业化落地。
“内存墙”与电互连的物理极限
这场能源危机的背后,其实是一个存在已久的根本性瓶颈:互连技术的发展速度,远远跟不上处理器性能的飞跃。
在过去的二十年里,硬件(如CPU/GPU)的峰值浮点运算能力(FLOPS)提升了惊人的6万倍。然而,作为数据仓库的DRAM内存,其带宽仅增长了约100倍。而负责在不同芯片、不同板卡之间搬运数据的互连带宽,同期也只增长了30倍左右。
这就造成了工程师们常说的“内存墙”——数据在处理器和内存之间传输的速度太慢,导致强大的计算单元经常“吃不饱”,性能无法得到充分利用。在需要海量数据吞吐的AI训练和推理场景中,数据集必须在GPU、高带宽内存(HBM)及其他加速器之间高速流动,这些互连限制就成了最关键的“卡脖子”环节。
过去几十年行之有效的解决方案——简单地缩小铜线的尺寸并提高布线密度——如今正在逼近物理极限。铜线越做越细、数量越多,其电阻导致的功耗和发热就越大,信号完整性也越难控制。数据中心的供电系统每一次进行电压转换都会产生损耗,而长距离、高密度的铜互连则在整个系统中持续放大着这些损耗。
现代AI芯片架构追求的是“堆栈内部高速访问”。芯片变得更薄,互连技术从硅通孔(TSV)演进到混合键合(Hybrid Bonding),目标都是让内存模块以前所未有的速度直接“贴”在处理器上。但是,当这种高速内存连接在需要访问另一个处理器时,仍必须经过电路板上的铜线“长途跋涉”,其带宽优势便会大打折扣。
从可插拔模块到共封装光学
硅光子技术本身并非横空出世的新事物。事实上,它早已通过可插拔光模块的形式,在连接数据中心机架的光通信网络中默默工作了多年。这些成熟系统采用独立的硅光子学芯片,搭配外置的激光器和光学透镜,封装成一个可以热插拔的模块。
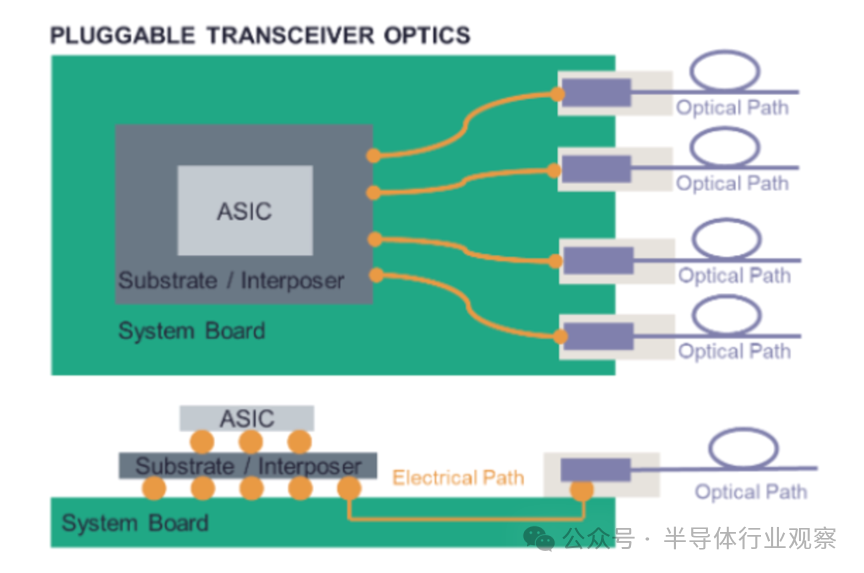
传统的可插拔光模块通过电气接口与系统板上的ASIC芯片连接。
但AI的需求正将光子技术推向一个更深层次的集成阶段。技术不再满足于仅仅连接独立的系统机柜,而是必须更进一步,与处理器、内存等核心计算单元直接集成在同一封装内。这种思路被称为“共封装光学”(Co-Packaged Optics, CPO)。它旨在将光互连的“入口”尽可能推进到计算发生的核心地带,从而在最大化带宽的同时,将能耗降到最低。
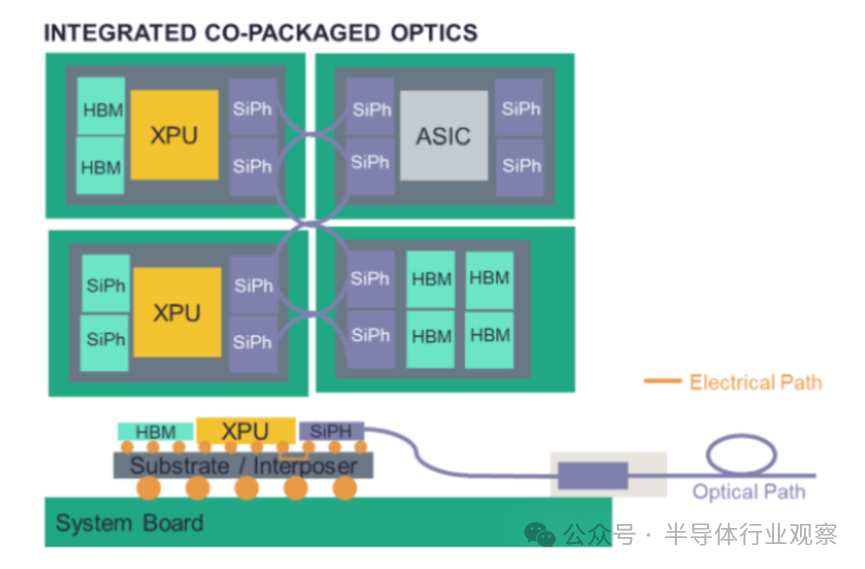
CPO架构中,硅光子引擎与XPU/ASIC、HBM等高价值芯片集成在同一封装基板上。
然而,挑战也随之而来,核心在于可靠性。传统的可插拔模块如果损坏,可以像更换U盘一样轻松拔下替换。但CPO系统中的光组件直接与价值数万美元的GPU和HBM内存集成在一起,一旦发生故障,维修难度和成本将呈指数级上升。这也是为什么目前主要芯片开发商的相关产品仍多处于试点验证阶段,他们在进行大规模部署前,必须对其长期可靠性进行极为审慎的评估。
制造挑战与未来影响
硅光子学之所以备受产业界青睐,一个重要原因是它能够最大限度地利用现有的、庞大的半导体制造(CMOS)基础设施。目前大多数硅光子器件仍采用相对成熟的45纳米至65纳米工艺节点制造,这比最先进的逻辑芯片工艺落后好几代。原因在于,光波导、调制器、探测器等元件的物理尺寸相对较大,对制程微缩的要求不像晶体管那么极致。
但这绝不意味着制造简单。恰恰相反,其工艺要求极为严苛。要制造出高效低损的硅波导,需要在晶圆上“雕刻”出纳米级的光通道,并且侧壁必须异常光滑,任何微小的粗糙都会导致光子散射,造成信号损耗。这要求蚀刻等工艺具备远超传统CMOS制造的精度水平。
在市场迫切需求的强力驱动下,加上巨额资本的涌入和过去三十年在光子学领域的技术积累,商业化的进程正在加速。一些行业路线图中曾预测2035年才能实现的能力,如今已被领先的制造商提前攻克。
其影响范围将远超数据中心围墙。随着光互连技术变得日益成熟和经济,它有望彻底改变从自动驾驶汽车的传感器融合,到边缘计算设备的实时处理等多种场景。这项最初为了支撑可持续AI扩张而发展的技术,最终可能会重塑几乎所有电子系统内部的通信范式。

硅光子技术在通信、计算、传感等广阔市场均有应用潜力。
现在最大的悬念是,这项技术能够以多快的速度实现规模化部署。随着领先的制造商已投入数十亿美元,试点系统开始进入数据中心测试,那个曾经看似遥远的“光速计算”未来,正变得触手可及。
硅光子学代表的不仅是一项技术升级,更是一次根本性的范式转移。它很可能将决定,在下一阶段的数字革命中,哪些公司能够占据引领地位。正如当年铜互连技术的成熟开启了个人电脑和互联网时代一样,光互连技术正携带着突破AI算力与能耗屏障的钥匙。
对于整个科技行业而言,当我们在努力应对由AI指数级增长所带来的可持续发展挑战时,硅光子学提供了一条难得的路径:它让我们不必在追求极致性能和保护环境责任之间做出痛苦的取舍。通过以“光”的精准和高效取代“电”的损耗与局限,这项技术让我们看到了一个可能性——在继续推动智能边界向前拓展的同时,显著降低其对地球的能源索取。
 发表于 2026-2-2 06:08:53
|
查看: 239|
回复: 0
发表于 2026-2-2 06:08:53
|
查看: 239|
回复: 0
