当大模型推理消耗的电力即将超过一个国家的用电量时,一群研究者开始从代码本身寻找答案。如果你关注人工智能,那么一组数据可能让你印象深刻:到2026年,全球数据中心的用电量预计将翻一番,超过整个加拿大的全国用电量,其中AI训练和推理是主要的驱动力。
在数据中心内部,成千上万的GPU夜以继日地进行着矩阵乘法和注意力计算。然而,大多数软件工程师并非硬件专家。他们依赖TensorFlow、PyTorch等高级框架,这些框架虽然方便,却将底层硬件的复杂性完全隐藏。当开发者编写自定义的CUDA内核以求更高性能时,他们往往只能依赖经验或简单的启发式规则,结果常常是:性能或许达标,但能量效率惨不忍睹。
问题在于,当前基于运行时剖析的自动化调优工具,需要实际执行内核成百上千次来测量能耗,这对于拥有巨大配置空间的LLM工作负载来说,在时间和能源成本上都是不可接受的。这就形成了一个恶性循环:效率低下的代码被大量部署,在长达数月的训练和数十亿次的推理中持续浪费着巨大的能源。
有没有一种方法,能让开发者在不实际运行代码的情况下,就能预测并优化GPU内核的能耗?一篇题为《FlipFlop: A Static Analysis-based Energy Optimization Framework for GPU Kernels》的论文给出了肯定答案。研究者来自达尔豪斯大学和IBM,项目已在GitHub开源。
一、核心思路:当静态分析遇见能耗建模
面对GPU能效优化的困境,研究团队提出了一个根本性问题:我们能否在不运行代码的情况下,预测一个GPU内核的能耗?
他们的答案是FlipFlop——一个基于静态分析的GPU内核能量优化框架。其核心思想既大胆又直观:通过分析GPU内核的中间表示代码(PTX),提取其内存访问模式、控制流特征和指令混合度,再结合一个经过硬件校准的混合性能-功耗模型,直接在开发阶段预测出能效最优的线程块配置和功耗限制。
这意味着,优化过程从“试错”转变为“预测”。
为何是“静态分析”?
静态分析,即在不执行程序的情况下分析其代码结构。在编译器领域这已是成熟技术,但将其用于跨层级的GPU能耗预测,却是一个创新。传统的运行时剖析面临三大成本:
- 剖析开销:执行数百个内核变体本身就消耗大量时间和能源。
- 能源浪费:在寻找最优配置的过程中,无数非最优配置的运行会在海量token处理中累积成巨大浪费。
- 冷启动延迟:当硬件平台更换时,整个优化过程必须从头再来。
FlipFlop的静态分析方法从根本上消除了这些成本。它不需要内核执行,仅通过分析PTX(Parallel Thread Execution)代码就能做出预测。PTX是英伟达的并行线程执行指令集,是一种低级的、面向GPU的中间表示,它保留了足够多的硬件相关信息,同时又比机器码更具可分析性。
二、四阶段流水线:从代码解析到最优推荐
FlipFlop并非一个简单的预测器,而是一个系统性的、四阶段的建模与优化流水线。
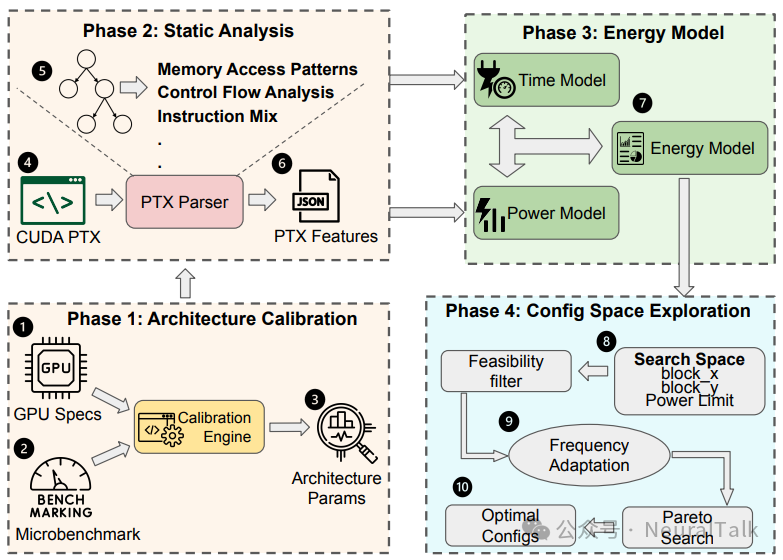
阶段一:PTX代码特征提取
FlipFlop首先解析CUDA内核编译产生的PTX代码,提取关键特征:
- 内存访问模式:识别加载、存储指令,分析其地址模式,判断是否存在合并访问的机会。
- 指令混合度:统计浮点运算、整数运算、特殊函数单元等不同类型指令的比例。
- 控制流图:分析分支和循环结构,估算潜在的线程发散程度。
- 资源需求:估算内核对寄存器、共享内存等稀缺资源的需求量。
这些静态特征构成了内核的“行为指纹”。
阶段二:硬件特定校准
FlipFlop的模型需要扎根于具体的硬件。为此,框架包含一个一次性的、轻量级的硬件校准阶段。研究团队设计了一组精密的微基准测试,来测量目标GPU的各种关键参数,如功能单元功率系数、内存延迟、并发扩展性等。这些校准数据将抽象的模型参数与具体的硬件行为联系起来,确保了预测的准确性和可移植性。校准过程只需执行一次。
阶段三:性能与功耗耦合建模
这是FlipFlop的大脑。它将前两个阶段的输出融合进两个紧密耦合的模型中:
- 性能模型:预测给定线程块配置下的执行时间。它考虑了内存访问时间(关键,特别考虑了内存合并效率)、计算时间、同步开销和内核启动开销。
- 功耗模型:预测内核运行时的动态功耗。它将总功耗分解为各个功能单元的活动功耗与静态漏电功耗。最具创新性的是其“形状感知”修正:该模型考虑了线程块的几何形状对内存合并效率的影响,从而修正功耗预测。
阶段四:配置空间探索与帕累托最优推荐
最后,FlipFlop在一个由线程块维度和GPU功耗限制构成的高维配置空间中进行智能搜索。它首先过滤掉不符合硬件约束的配置,然后使用上述模型快速评估剩余每个配置的预期执行时间和能耗。
最终,FlipFlop输出的是一个帕累托最优配置集合。在这个集合中,没有任何一个配置能在不损害另一方面的情况下,进一步降低能耗或缩短时间。开发者可以在此集合中根据实际需求进行最终选择。
三、性能实测:数字背后的震撼
研究团队在英伟达RTX 5000 Ada和RTX 3070等多款GPU上,对FlipFlop进行了全面评估。
RQ1:联合调优的力量有多大?
研究者测试了序列长度从128到8192的多头注意力内核。结论是颠覆性的:单纯追求高占用率的配置,其能耗往往远离最优。
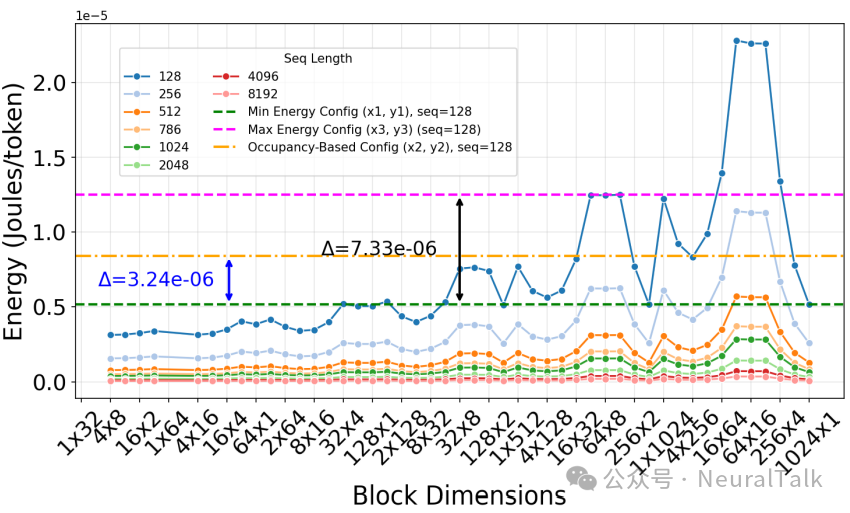
结果表明,最优配置(如2×32线程块在100W功率限制下)相比占用率启发式方法可实现高达79%的能耗降低,且不同序列长度呈现出显著的非单调趋势,证明了同时调节线程块几何形状和功率限制对能量优化的必要性。
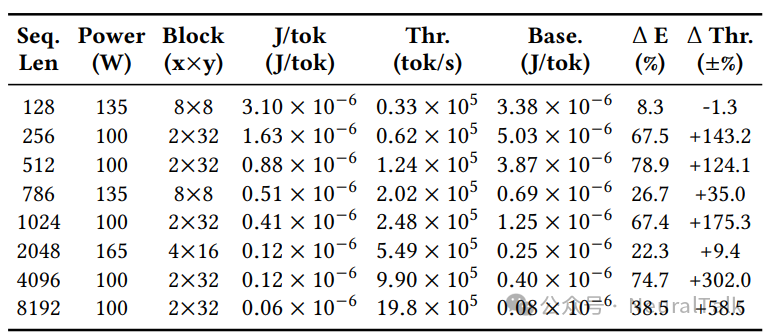
具体数据显示,在序列长度为512时,FlipFlop推荐的100W功耗、2x32线程块配置,相比默认250W功耗下的占用率推荐配置,能耗降低了惊人的78.9%,同时吞吐量还有所提升。这揭示了一个关键洞见:更高的功耗和更多的线程并不总是意味着更高的能效。通过降低功耗限制并匹配合适的线程块形状,可以让GPU运行在能效曲线的“甜点区”。
RQ2:静态预测的准确性如何?
研究者将FlipFlop的预测结果与通过Kernel Tuner进行详尽运行时剖析得到的真实测量值进行对比。
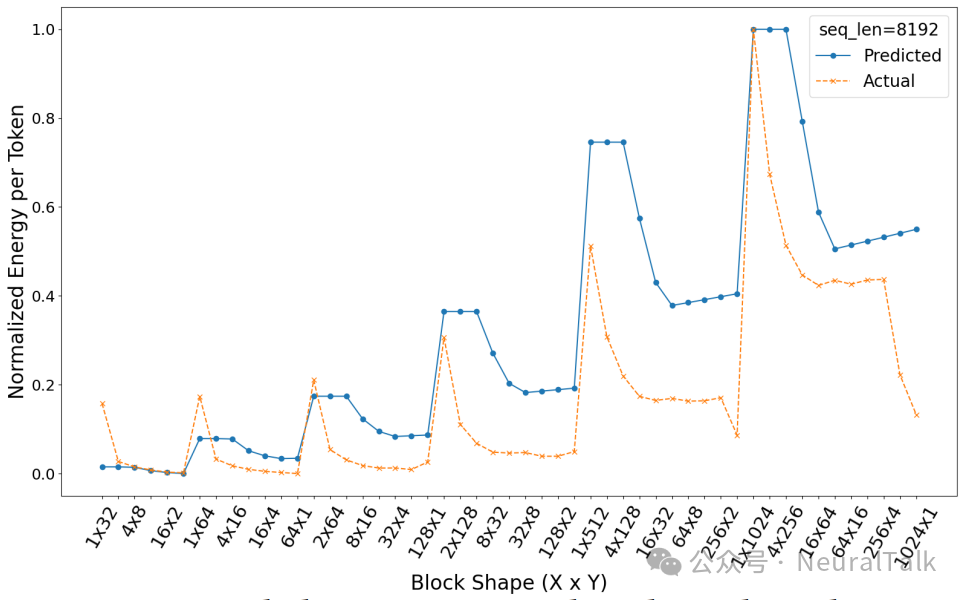
通过斯皮尔曼秩相关系数验证,FlipFlop的能耗预测在多个序列长度上相关系数 ρ 均超过 0.84,表现出极强的预测能力。更重要的是,FlipFlop 推荐的前 20 个配置,覆盖了实际最优前 20 个配置的 94%。 这意味着,开发者只需评估 FlipFlop 推荐的极少数配置,就能以极高的概率找到真正能效优异的配置,省去了超过90%的无效尝试。
RQ3:为开发者节省了多少?
在优化单个内核时,FlipFlop将需要评估的配置数量平均减少了93.4%。

这种减少直接转化为资源节约:每次优化会话节省14.3分钟计算时间和188,680焦耳能量,相当于减少了约19.4克二氧化碳当量的排放。对于需要优化数百个内核的大型模型而言,这种节约将呈现数量级的放大。
四、技术定位:与现有工具的对比
在GPU优化领域,FlipFlop通过独特的组合,占据了属于自己的生态位。下表清晰地展示了其独特性:
| 方法/类型 |
代表工作 |
能量感知 |
形状敏感 |
功耗建模 |
预执行 |
免剖析 |
| FlipFlop (静态分析) |
本文 |
是 |
是 |
是 |
是 |
是 |
| GPU 静态分析 |
Alavani et al., Lou & Muller |
部分 |
否/部分 |
否 |
是 |
是 |
| 分析与模拟模型 |
GPUWatch, Hong & Kim |
是 |
部分 |
是 |
是 |
否(需模拟) |
| 框架与运行时 |
PyTorch Inductor, Zeus |
部分 |
否 |
部分 |
否 |
否 |
| 剖析型自动调优器 |
Kernel Tuner, CLTune |
是 |
是 |
否 |
否 |
否 |
FlipFlop 的独特之处在于:
- 内核级、预执行的静态分析:在运行前,在单个内核粒度进行分析。
- 能量与形状的双重敏感:明确建模线程块几何形状对能耗的影响。
- 显式的功耗建模:拥有一个可解释的、基于硬件的功耗模型。
- 真正的“免剖析”:核心推荐完全基于静态分析,无需任何内核执行。
相比之下,像Kernel Tuner这样的工具虽然功能强大,但严重依赖运行时剖析;而像GPUWatch这样的模拟器虽然能提供周期级精确度,但模拟开销使其无法用于快速探索巨大配置空间。FlipFlop则在准确性与效率之间找到了一个平衡点。
五、现实案例:优化 CodeLlama 推理
为了展示FlipFlop在真实场景中的威力,研究者进行了案例研究:优化 CodeLlama 7B 模型的推理过程。
一名希望为边缘设备部署CodeLlama的工程师,使用低级CUDA编程优化多头注意力内核。如果没有FlipFlop,他可能需要测试成千上万个配置。而使用FlipFlop,静态分析从海量组合中筛选出了仅仅6个有前途的候选配置。
在这6个配置中,FlipFlop推荐的 64×16 线程块形状表现最佳。与默认配置相比,它在处理164个编程问题时:
- 能耗降低 15.7% (5510.7 J vs 6536.0 J)
- 延迟降低 14.0% (27.97 s vs 32.51 s)
这一改进源于二维线程布局更好地契合了内核的内存访问模式,减少了共享内存体冲突,提升了全局内存的合并访问效率。这个案例证明,仅通过线程块形状的优化,无需修改算法,就能实现显著的能效提升。
六、总结与展望
在AI计算需求指数级增长,而能源约束日益收紧的时代,FlipFlop的出现意义重大。它用优雅的静态分析方法,穿透了硬件的“黑箱”,让开发者能以最低的代价洞察内核的能耗本质。
更高的算力不等于更高的能效,合适的“形状”与“节奏”往往比单纯的“蛮力”更重要。FlipFlop不仅是一个工具,更代表了一种将能源效率深度嵌入软件开发生命周期的新范式。它民主化了硬件优化,使得构建在性能与能效间智能平衡的弹性系统变得更加可能。
随着研究团队计划将FlipFlop扩展到更广泛的AI与科学计算内核,这种 “静态分析+智能建模” 的路径,将在构建绿色、可持续的计算基础设施中,扮演越来越关键的角色。对于深入探索GPU编程与高性能计算的开发者而言,这类工作提供了宝贵的思路和实用的工具。如果你想了解更多前沿的AI与系统优化技术,欢迎访问云栈社区进行交流与探讨。
 发表于 2026-2-2 07:25:30
|
查看: 234|
回复: 0
发表于 2026-2-2 07:25:30
|
查看: 234|
回复: 0
