在高性能计算领域,I/O瓶颈常常是制约系统充分发挥潜力的关键因素。无论是大数据分析中对海量数据的实时读取,还是基因测序中对庞大文件的处理,传统的I/O方式在速度和效率上都难以满足需求。那么,如何突破这一困境呢?Linux内核 5.1版本引入的io_uring框架,为我们带来了全新的高性能异步I/O解决方案。
一、传统 I/O 模型回顾
在深入了解 io_uring 之前,让我们先来回顾一下传统的 I/O 模型,剖析它们在应对高并发、高性能需求时所面临的挑战。
1.1 阻塞式 I/O
阻塞式 I/O 是最基础、最直观的 I/O 模型。在这种模型下,当应用程序执行 I/O 操作(如 read 或 write)时,进程会被阻塞,直到 I/O 操作完成。这就像在餐厅点餐后,必须坐在桌边一直等到食物上桌,期间什么也做不了。
以一个简单的文件读取操作为例:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#define BUFFER_SIZE 1024
int main(){
int fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
char buffer[BUFFER_SIZE];
ssize_t bytes_read = read(fd, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
perror("read");
close(fd);
return 1;
}
printf("Read %zd bytes: %.*s\n", bytes_read, (int)bytes_read, buffer);
close(fd);
return 0;
}
在这段代码中,read函数会阻塞进程,直到数据从文件中读取到缓冲区。如果文件很大或者读取过程中出现延迟,进程将长时间处于阻塞状态,无法处理其他任务。
在高并发的 Web 服务器场景中,如果使用阻塞式 I/O,每一个客户端连接都需要一个独立的线程来处理。当并发连接数增多时,线程资源将被大量消耗,系统性能会急剧下降。
1.2 非阻塞式 I/O
非阻塞式 I/O 模型下,当应用程序执行 I/O 操作时,如果数据尚未准备好,系统不会阻塞进程,而是立即返回一个错误(如 EWOULDBLOCK 或 EAGAIN)。应用程序可以继续执行其他任务,然后通过轮询的方式再次尝试 I/O 操作,直到数据准备好。
在 Linux 中,可以通过fcntl函数将文件描述符设置为非阻塞模式:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#define BUFFER_SIZE 1024
int main(){
int fd = open("example.txt", O_RDONLY | O_NONBLOCK);
if (fd == -1) {
perror("open");
return 1;
}
char buffer[BUFFER_SIZE];
ssize_t bytes_read;
while(1) {
bytes_read = read(fd, buffer, BUFFER_SIZE);
if (bytes_read == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据未准备好,继续执行其他任务或再次轮询
usleep(1000); // 稍微等待一下再轮询
continue;
} else {
perror("read");
close(fd);
return 1;
}
}
break;
}
printf("Read %zd bytes: %.*s\n", bytes_read, (int)bytes_read, buffer);
close(fd);
return 0;
}
非阻塞式 I/O 提高了系统的并发处理能力,但频繁的轮询会消耗大量的 CPU 资源。而且其编程复杂度较高,需要处理更多的错误和状态判断。
1.3 I/O 多路复用
I/O 多路复用允许一个进程同时监视多个 I/O 描述符,当其中任何一个描述符就绪时,进程就可以对其进行处理。常见的 I/O 多路复用技术有 select、poll 和 epoll。
以 select 为例:
#include <stdio.h>
#include <sys/select.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdlib.h>
#include <string.h>
#define BUFFER_SIZE 1024
#define FD_SETSIZE 1024
int main(){
int fd1 = open("file1.txt", O_RDONLY);
int fd2 = open("file2.txt", O_RDONLY);
if (fd1 == -1 || fd2 == -1) {
perror("open");
return 1;
}
fd_set read_fds;
FD_ZERO(&read_fds);
FD_SET(fd1, &read_fds);
FD_SET(fd2, &read_fds);
int max_fd = (fd1 > fd2) ? fd1 : fd2;
int ret = select(max_fd + 1, &read_fds, NULL, NULL, NULL);
if (ret == -1) {
perror("select");
close(fd1);
close(fd2);
return 1;
} else if (ret > 0) {
if (FD_ISSET(fd1, &read_fds)) {
char buffer1[BUFFER_SIZE];
ssize_t bytes_read1 = read(fd1, buffer1, BUFFER_SIZE);
if (bytes_read1 == -1) {
perror("read file1");
} else {
printf("Read from file1: %.*s\n", (int)bytes_read1, buffer1);
}
}
if (FD_ISSET(fd2, &read_fds)) {
char buffer2[BUFFER_SIZE];
ssize_t bytes_read2 = read(fd2, buffer2, BUFFER_SIZE);
if (bytes_read2 == -1) {
perror("read file2");
} else {
printf("Read from file2: %.*s\n", (int)bytes_read2, buffer2);
}
}
}
close(fd1);
close(fd2);
return 0;
}
poll 与 select 类似,但改进了文件描述符数量的限制。而 epoll 采用了事件驱动模型,在高并发场景下表现更为出色。然而,即使是 epoll,在面对超高并发场景时,也存在一定的性能瓶颈。
1.4 传统 I/O 模型的局限性
(1)系统调用开销高
传统 I/O 操作往往需要多次在用户态和内核态之间进行切换,每次切换都要保存和恢复现场,这些开销在高并发场景下会被放大,严重影响系统性能。
(2)数据拷贝次数多
在传统的 I/O 流程中,数据往往需要在多个缓冲区之间进行多次拷贝。每一次数据拷贝都需要占用 CPU 资源和内存带宽,特别是在处理大量数据时,会成为系统性能的瓶颈。
(3)异步处理能力不足
传统 I/O 模型在异步处理复杂操作时存在很大的困难。像 open()、accept() 等系统调用通常是同步执行的,应用程序在执行这些调用时会被阻塞,无法在等待的同时去执行其他任务,限制了系统的并发处理能力。
二、初识 io_uring
2.1 io_uring 是什么?
io_uring 是 Linux 内核 5.1 版本引入的高性能异步 I/O 框架,由资深内核开发者 Jens Axboe 开发。它旨在为 Linux 系统提供一个统一、易用、可扩展且高效的异步 I/O 解决方案。
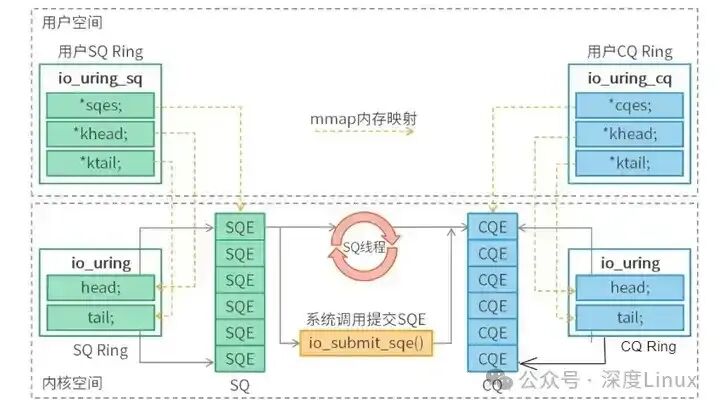
io_uring 的核心概念主要包括提交队列(SQ)、完成队列(CQ)、提交队列项(SQE)和完成队列项(CQE):
- 提交队列(SQ,Submission Queue):用于存放用户空间提交的 I/O 请求。它是一个环形队列,用户通过操作队列的 tail 指针来写入新的请求。
- 完成队列(CQ,Completion Queue):用于存放已经完成的 I/O 请求结果。内核在处理完 I/O 请求后,会将结果填充到 CQ 中。同样是环形队列,用户通过操作队列的 head 指针来读取完成的结果。
- 提交队列项(SQE,Submission Queue Entry):表示一个具体的 I/O 请求,包含了操作类型、文件描述符、缓冲区地址、偏移量、数据长度等信息。
struct io_uring_sqe {
__u8 opcode; // 操作类型,如 READ, WRITE, ACCEPT…
__u8 flags;
__u16 ioprio;
__s32 fd;
__u64 offset;
__u64 addr; // 用户缓冲区地址
__u32 len;
__u64 user_data; // 用户自定义数据(回调、标识等)
};
- 完成队列项(CQE,Completion Queue Entry):表示一个 I/O 请求的完成结果,包含返回值(成功时为字节数,失败时为 -errno)、用户自定义数据等信息。
struct io_uring_cqe {
__u64 user_data; // 与 SQE 中设置的一致
__s32 res; // 返回值:成功时为字节数,失败时为 -errno
__u32 flags;
};
SQ 和 CQ 通过内存映射(mmap)的方式映射到用户空间,使得用户态和内核态可以直接访问。用户是 SQ 的生产者,内核是消费者;内核是 CQ 的生产者,用户是消费者。
2.2 设计目标与理念
io_uring 的设计理念主要体现在以下几个方面:
- 减少系统调用开销:通过提交队列(SQ)和完成队列(CQ),应用程序可以将多个 I/O 请求一次性写入,然后通过一次系统调用通知内核处理,大大减少了系统调用的次数。
- 实现零拷贝:通过注册缓冲区(Registered Buffers)和固定文件(Fixed Files)等机制,内核在进行 I/O 操作时直接使用用户空间预注册的缓冲区,避免了数据拷贝。
- 提供强大的异步处理能力:应用程序在发起 I/O 请求后无需等待操作完成,可以继续执行其他任务,内核在操作完成后通过完成队列异步通知。
- 统一 I/O 接口:试图统一网络和磁盘 I/O 接口,为开发者提供一个通用的异步 I/O 框架。
2.3 io_uring 设计思路
(1) 解决“系统调用开销大”的问题?
考虑将多次系统调用中的逻辑合并到有限次数中,将消耗降为常数时间复杂度。
(2) 解决“拷贝开销大”的问题?
最佳方式是让应用与内核共享一段内存。因此,需要一对共享的 ring buffer 用于通信:
- 提交队列 SQ 中,应用是 IO 提交的生产者,内核是消费者。
- 完成队列 CQ 中,内核是 IO 完成的生产者,应用是消费者。
- 内核控制 SQ ring 的 head 和 CQ ring 的 tail,应用程序控制 SQ ring 的 tail 和 CQ ring 的 head。
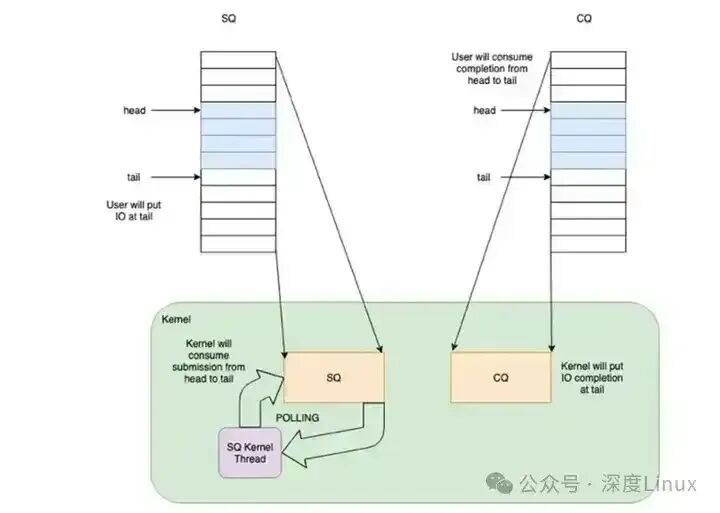
(3) 解决“API不友好”的问题?
考虑把多个系统调用合而为一,或者将复杂的函数分解为更简单的部分来进行重构。
三、io_uring 核心特性
io_uring 之所以能够在高性能计算中展现出卓越的性能,关键在于其一系列独特的核心特性。
3.1 共享环形队列
io_uring 通过共享内存构建了提交队列(SQ)和完成队列(CQ),这是其实现高效 I/O 的基础。当应用程序需要进行 I/O 操作时,它将 I/O 请求封装成 SQE 写入 SQ。内核直接从 SQ 中读取请求,无需进行数据拷贝。完成后,内核将结果封装成 CQE 写入 CQ,应用程序直接从 CQ 中读取。
以一个简单的文件读取操作为例:
#include <liburing.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 4096
int main(){
struct io_uring ring;
char buffer[BUFFER_SIZE];
struct io_uring_sqe *sqe;
struct io_uring_cqe *cqe;
int fd, ret;
// 初始化io_uring
ret = io_uring_queue_init(8, &ring, 0);
if (ret < 0) {
perror("io_uring_queue_init");
return 1;
}
// 打开文件
fd = open("example.txt", O_RDONLY);
if (fd < 0) {
perror("open");
io_uring_queue_exit(&ring);
return 1;
}
// 获取一个SQE并准备read操作
sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fd, buffer, sizeof(buffer), 0);
// 提交请求
ret = io_uring_submit(&ring);
if (ret < 0) {
perror("io_uring_submit");
close(fd);
io_uring_queue_exit(&ring);
return 1;
}
// 等待完成并获取CQE
ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
perror("io_uring_wait_cqe");
close(fd);
io_uring_queue_exit(&ring);
return 1;
}
// 检查是否成功
if (cqe->res >= 0) {
printf("Read %d bytes: %.*s\n", cqe->res, (int)cqe->res, buffer);
} else {
printf("Read failed, errno = %d\n", -cqe->res);
}
// 标记CQE已处理
io_uring_cqe_seen(&ring, cqe);
// 释放资源
close(fd);
io_uring_queue_exit(&ring);
return 0;
}
这种共享环形队列的设计,使得用户态与内核态之间的通信更加高效,避免了数据的多次拷贝。
3.2 批量处理能力
io_uring 支持单次系统调用提交多个 I/O 请求,并一次性收割多个完成事件,这一特性极大地减少了上下文切换的开销。例如,在一个需要处理大量文件读取请求的场景中,可以这样实现:
#include <liburing.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 4096
#define REQUESTS_NUM 10
int main(){
struct io_uring ring;
char buffers[REQUESTS_NUM][BUFFER_SIZE];
struct io_uring_sqe *sqe;
struct io_uring_cqe *cqe;
int fds[REQUESTS_NUM];
int i, ret;
// 初始化io_uring
ret = io_uring_queue_init(REQUESTS_NUM, &ring, 0);
if (ret < 0) {
perror("io_uring_queue_init");
return 1;
}
// 打开多个文件
for (i = 0; i < REQUESTS_NUM; i++) {
char filename[32];
snprintf(filename, sizeof(filename), "file%d.txt", i);
fds[i] = open(filename, O_RDONLY);
if (fds[i] < 0) {
perror("open");
for (int j = 0; j < i; j++) {
close(fds[j]);
}
io_uring_queue_exit(&ring);
return 1;
}
}
// 提交多个读取请求
for (i = 0; i < REQUESTS_NUM; i++) {
sqe = io_uring_get_sqe(&ring);
io_uring_prep_read(sqe, fds[i], buffers[i], sizeof(buffers[i]), 0);
}
// 提交请求
ret = io_uring_submit(&ring);
if (ret < 0) {
perror("io_uring_submit");
for (i = 0; i < REQUESTS_NUM; i++) {
close(fds[i]);
}
io_uring_queue_exit(&ring);
return 1;
}
// 等待并获取所有完成事件
for (i = 0; i < REQUESTS_NUM; i++) {
ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
perror("io_uring_wait_cqe");
for (int j = 0; j < REQUESTS_NUM; j++) {
close(fds[j]);
}
io_uring_queue_exit(&ring);
return 1;
}
// 检查是否成功
if (cqe->res >= 0) {
printf("Read from file%d.txt: %d bytes\n", i, cqe->res);
} else {
printf("Read from file%d.txt failed, errno = %d\n", i, -cqe->res);
}
// 标记CQE已处理
io_uring_cqe_seen(&ring, cqe);
}
// 释放资源
for (i = 0; i < REQUESTS_NUM; i++) {
close(fds[i]);
}
io_uring_queue_exit(&ring);
return 0;
}
应用程序一次性提交了10个读取请求,内核处理完后,应用程序再一次性获取10个完成事件。这种批量处理的方式,相比传统的逐个处理,大大减少了上下文切换的次数。
3.3 内核轮询机制
io_uring 提供了 SQ Polling 模式,在这种模式下,内核会主动轮询 SQ,无需应用程序显式地调用系统调用通知内核处理 I/O 请求。这一机制进一步消除了系统调用的延迟。
要启用 SQ Polling 模式,需要在初始化时设置 IORING_SETUP_SQPOLL 标志位:
#include <liburing.h>
#include <stdio.h>
int main(){
struct io_uring ring;
int ret = io_uring_queue_init(128, &ring, IORING_SETUP_SQPOLL);
if (ret < 0) {
perror("io_uring_queue_init");
return 1;
}
// 后续操作...
io_uring_queue_exit(&ring);
return 0;
}
在这种模式下,当应用程序将 I/O 请求写入 SQ 后,内核可以第一时间获取并处理,避免了因等待系统调用而产生的延迟,特别适用于对实时性要求较高的高并发场景。
3.4 灵活通知机制
io_uring 支持多种通知模式,包括事件驱动和轮询模式,这使得它能够适应不同应用场景的需求。在事件驱动模式下,io_uring 可以与传统的事件通知机制(如 epoll)相结合,应用程序可以通过 epoll 等待 io_uring 的完成队列(CQ)上的事件。这种模式适用于那些已经基于 epoll 构建的应用程序,可以逐步引入 io_uring 而无需大规模改动架构。
四、io_uring 工作流程
io_uring 的高效运作依赖于一套清晰的异步 I/O 处理流程,整个流程可分为四个关键阶段。
4.1 初始化阶段
在使用 io_uring 进行任何 I/O 操作前,需先完成初始化工作,核心是创建并配置 io_uring 实例,建立用户态与内核态共享的环形队列。
#include <liburing.h>
#include <stdio.h>
int main() {
struct io_uring ring;
struct io_uring_params params;
memset(¶ms, 0, sizeof(params));
// 启用SQ Polling模式,同时设置轮询线程优先级
params.flags |= IORING_SETUP_SQPOLL;
params.sq_thread_priority = 10; // 数值越小优先级越高
// 初始化io_uring,队列深度为128
int ret = io_uring_queue_init_params(128, &ring, ¶ms);
if (ret < 0) {
perror("io_uring_queue_init_params");
return 1;
}
// 业务逻辑处理...
// 资源清理
io_uring_queue_exit(&ring);
return 0;
}
初始化过程中,内核会为 io_uring 分配共享内存区域,用于存储 SQ、CQ 及相关元数据。初始化完成后,应用程序与内核即可通过共享队列实现无拷贝通信。
4.2 请求I/O提交
请求提交是应用程序向内核发起 I/O 操作的核心步骤,需经过“获取 SQE→配置请求参数→提交请求”三步。
- 获取空闲 SQE:应用程序通过
io_uring_get_sqe 函数从 SQ 中获取一个空闲的提交队列条目(SQE)。
- 配置 SQE 参数:根据具体 I/O 操作类型,调用对应的封装函数配置 SQE。例如,文件读取用
io_uring_prep_read。同时,可通过 sqe->user_data 字段设置自定义标识。
- 批量提交请求:配置完成的 SQE 会被写入 SQ,应用程序通过
io_uring_submit 函数将 SQ 中的所有待处理请求批量提交给内核。
批量提交场景下,应用程序可循环获取并配置多个 SQE,再一次性提交,能将系统调用次数从 N 次减少到 1 次。
4.3 内核处理阶段
内核在收到应用程序提交的 I/O 请求后,进入异步处理流程:
- 消费 SQ 请求:内核通过轮询 SQ 的尾指针,感知新提交的请求。内核会按顺序读取 SQ 中的 SQE,解析参数,验证请求合法性。
- 异步执行 I/O 操作:内核根据 SQE 配置的参数,异步执行对应的 I/O 操作。在此过程中,内核会释放当前处理上下文,不阻塞应用程序。
- 生成 CQE 并写入 CQ:I/O 操作完成后,内核会生成一个完成队列条目(CQE),记录操作结果(
res字段),并将 SQE 中的 user_data 复制到 CQE 中。最后,内核更新 CQ 的尾指针。
值得注意的是,请求提交顺序与完成顺序可能不一致,应用程序需通过 user_data 字段匹配请求与结果。
4.4 处理完成事件
应用程序通过从完成队列(CQ)中获取完成队列条目(CQE)来处理 I/O 操作的完成事件:
- 获取 CQE:可以使用
io_uring_wait_cqe 函数阻塞等待完成事件,或使用 io_uring_peek_cqe 非阻塞地检查。
- 处理结果:根据 CQE 中的
res 字段判断 I/O 操作是否成功,并通过 user_data 字段获取提交请求时设置的用户数据。
- 标记 CQE 已消费:调用
io_uring_cqe_seen 函数标记该 CQE 已被消费。
#include <liburing.h>
#include <stdio.h>
#include <string.h>
int main(){
struct io_uring ring;
// 初始化io_uring(省略)
struct io_uring_cqe *cqe;
int ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
perror("io_uring_wait_cqe");
return 1;
}
if (cqe->res >= 0) {
printf("Operation succeeded, transferred %d bytes\n", cqe->res);
} else {
printf("Operation failed, errno = %d\n", -cqe->res);
}
// 标记CQE已处理
io_uring_cqe_seen(&ring, cqe);
return 0;
}
五、io_uring 与 epoll 对比
5.1 系统调用次数差异
在 epoll 模型中,每次 I/O 操作都需要多次系统调用(epoll_wait, accept, read, write等),开销在高并发场景下会累积起来。而 io_uring 通过队列设计,用户态将多个 I/O 请求放入提交队列后,通常只需一次 io_uring_enter 调用通知内核,大大减少了系统调用次数。
5.2 异步处理能力对比
epoll 本质上是基于事件就绪通知,在处理事件过程中仍然可能会出现阻塞。io_uring 则实现了真正的异步 I/O,应用程序提交请求后无需等待,内核在后台处理,完成后通过完成队列通知,使得应用程序可以在此期间继续执行其他任务,提高了系统的并发处理能力。
5.3 操作支持范围
epoll 主要用于监视文件描述符的事件(可读、可写等),对于一些复杂的系统调用,如 open()、fsync() 等,操作较为繁琐。io_uring 则对各种系统调用提供了更全面的异步支持,可以直接将这些操作封装成 SQE 提交,实现真正的异步操作。
六、io_uring 性能优化之道
6.1 合理设置队列深度
队列深度决定了提交队列(SQ)和完成队列(CQ)的大小。设置过小,可能导致队列被快速填满,影响并发能力;设置过大,会占用更多内存,可能增加处理时间。需要根据系统负载、硬件资源及 I/O 请求特点来设置。对于高并发服务器,可设置为 1024 或更高;对于嵌入式或轻量级应用,可设置为 64 或 128。
6.2 巧用 SQPOLL 模式
SQPOLL 模式通过内核线程轮询提交队列,实现了零系统调用开销路径,适用于处理大量 I/O 请求且对响应时间要求高的场景(如高并发数据库)。启用时需设置 IORING_SETUP_SQPOLL 标志,并可配置线程空闲超时和 CPU 绑定以进一步优化。
6.3 缓冲区管理策略
通过缓冲区预注册,可以避免内核重复拷贝数据,提高效率。需要根据实际 I/O 需求合理管理缓冲区的大小和数量,并注意减少内存碎片,可采用内存池等技术。
6.4 多线程与 io_uring 的协同
io_uring 的无锁批量提交机制可以完美适配多线程/协程调度器。多个线程可以同时向 io_uring 提交 I/O 请求而无需担心锁竞争。需要注意不同线程请求间的依赖关系和线程安全问题,并可以通过将不同类型 I/O 请求分配到不同线程来实现分工协作。
七、io_uring 应用案例及实战
7.1 io_uring 应用案例
(1)高性能网络服务
- Nginx:从 1.19.0 版本开始支持 io_uring。在实际测试中,当并发连接数达到 10000 时,使用 io_uring 的 Nginx 吞吐量相比使用
epoll 提升了约 30%,平均响应时间降低了约 20%。
- Kong (API网关):通过集成 io_uring,在高并发情况下能将请求的平均处理时间缩短 15% 以上。
(2)数据库系统
- Limbo 数据库:一个兼容 SQLite 的进程内 OLTP 数据库,使用 C/C++ 和 Rust 编写,通过 io_uring 实现高效异步 I/O。在模拟高并发事务处理场景中,事务处理吞吐量提升了约 40%,平均响应时间降低了约 35%。
(3)大规模文件处理
- wcp:一个实验性的文件复制工具,利用 io_uring 实现异步 I/O,其复制速度可以比标准的
cp 命令快高达 70%。
7.2 io_uring 使用示例(C 语言)
下面是一个完整的 C 语言代码示例,展示如何使用 io_uring 进行文件读取操作:
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <string.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <linux/io_uring.h>
int main(){
struct io_uring ring;
struct io_uring_sqe *sqe;
struct io_uring_cqe *cqe;
int fd, ret;
// 打开文件
fd = open("example.txt", O_RDONLY);
if (fd < 0) {
perror("Failed to open file");
return 1;
}
// 初始化io_uring,参数8表示队列深度,可以根据实际需求调整,0表示使用默认设置
io_uring_queue_init(8, &ring, 0);
// 获取一个提交队列条目
sqe = io_uring_get_sqe(&ring);
if (!sqe) {
fprintf(stderr, "Could not get sqe\n");
return 1;
}
// 准备异步读操作,malloc分配1024字节的缓冲区用于存储读取的数据,偏移量为0表示从文件开头读取
char *buf = malloc(1024);
io_uring_prep_read(sqe, fd, buf, 1024, 0);
// 提交请求
io_uring_submit(&ring);
// 等待完成
ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
perror("io_uring_wait_cqe");
return 1;
}
// 检查结果,cqe->res大于0表示成功读取的字节数,小于0表示错误码
if (cqe->res < 0) {
fprintf(stderr, "Async read failed: %s\n", strerror(-cqe->res));
return 1;
} else {
printf("Read %d bytes: %s\n", cqe->res, buf);
}
// 释放资源,标记完成队列项已处理,避免重复处理,关闭io_uring队列,关闭文件描述符,释放分配的内存
io_uring_cqe_seen(&ring, cqe);
io_uring_queue_exit(&ring);
close(fd);
free(buf);
return 0;
}
7.3 使用 io_uring 的挑战与应对策略
(1)编程复杂度
io_uring 的异步特性和底层接口带来了一定的编程挑战。需要关注任务执行顺序和并发控制。应对策略包括深入学习官方文档,以及使用如 liburing 等开源库提供的高级封装来简化使用。
(2)兼容性问题
io_uring 需要 Linux 内核 5.1 及以上版本。应对策略是确保目标系统内核版本达标,对于旧系统可考虑升级内核。同时需查阅特定 Linux 发行版的文档了解支持情况。
(3)错误处理
在异步操作中,错误可能在请求提交后的任意时刻发生,信息在完成队列(CQ)中返回。应对策略包括:为每个请求设置唯一的 user_data 标识符;从 CQ 获取 CQE 后仔细检查 res 字段;建立完善的错误日志机制。
 发表于 2026-1-26 13:45:36
|
查看: 211|
回复: 0
发表于 2026-1-26 13:45:36
|
查看: 211|
回复: 0
