在并发编程的世界里,我们通常依赖锁(如互斥锁、自旋锁)来实现线程间的同步与互斥。但锁机制往往伴随着性能开销与复杂的死锁问题。你是否想过,是否存在一种更优雅、无需锁的同步方式?实际上,业界早已存在像Dekker算法这样的经典无锁同步算法,它仅通过共享内存的读写操作,就能巧妙地解决并发访问的互斥难题。
Dekker算法是并发编程中一个里程碑式的设计,它仅依靠共享内存通信来实现两个进程或线程间的互斥访问。其精妙之处在于,它能够同时保证互斥(Mutual Exclusion)、避免死锁(Deadlock)并防止饿死(Starvation)。理解它,是深入计算机基础中并发控制理论的重要一步。
算法核心思想:“孔融让梨”
如何用一句话概括Dekker算法的精髓?一个非常贴切的中文成语就是——孔融让梨。
这是什么意思呢?想象两个进程(或线程)都试图进入临界区(Critical Section)。每个进程在尝试进入时,都会先“礼让”一下,看看对方是否也想进入。如果对方想进,并且轮到自己“让梨”,那就主动让出机会;如果对方不想进,或者轮到自己“吃梨”,那自己再进入执行。
这种“先人后己”的思想,完美地模拟了孔融让梨的场景:拿到梨(资源)后,不是立即吃掉(使用),而是先谦让给兄长(另一个进程)。
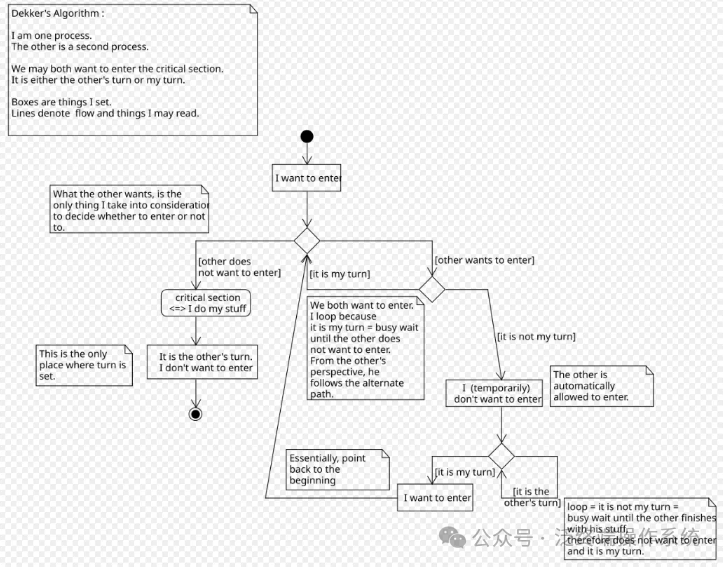
Dekker算法工作流程详解
下面这张流程图清晰地描绘了Dekker算法在两个进程间协同工作的完整逻辑:
代码实现:简洁而强大
实现Dekker算法的原型非常直观。我们需要为每个线程设置一个标志(flag0, flag1),表示自己是否想进入临界区;同时,设置一个全局的“礼让”标志 turn,来决定当前该谁“让梨”。
以下是核心的C/C++代码示例:
static void dekker0(void)
{
flag0 = 1;
turn = 1;
while ((flag1 == 1) && (turn == 1));
counter++;
flag0 = 0;
}
static void dekker1(void)
{
flag1 = 1;
turn = 0;
while ((flag0 == 1) && (turn == 0));
counter++;
flag1 = 0;
}
代码分析:
dekker0开始运行时,先举起自己的“需求旗”(flag0 = 1),然后主动将“梨”让给对方(turn = 1)。- 紧接着,它进入一个等待循环:只有当对方也想进入(
flag1 == 1)且确实轮到对方“吃梨”(turn == 1)时,自己才等待。否则,它就进入临界区执行counter++。
- 执行完毕后,放下自己的需求旗(
flag0 = 0)。
dekker1的逻辑完全对称,只是将turn设置为0,表示让给dekker0。
三大特性剖析:为何它能成功?
这种看似简单的设计,为何能保证并发编程中的三大核心要求?我们来逐一拆解。
1. 如何保证互斥?
互斥要求同一时刻只有一个线程能在临界区内。在Dekker算法中,两个线程不可能同时通过它们各自的 while 循环。因为turn这个全局变量只有一个值(0或1)。在任何时刻,turn的值只会让其中一个线程的循环条件不成立(从而进入临界区),而让另一个线程的循环条件成立(从而持续等待)。这就天然地避免了互斥访问。
2. 如何避免死锁?
死锁通常发生在多个线程互相等待对方持有的锁。Dekker算法中根本没有锁!线程的等待是基于对方的需求(flag)和全局顺序(turn)。即使turn值出现混乱,任何一个线程在下次执行时,都会主动设置turn以“让梨”给对方,从而打破任何可能的循环等待局面。这种设计哲学在构建高可靠后端 & 架构时值得借鉴。
3. 如何防止饿死?
假设 dekker0 不幸地一直卡在 while ((flag1 == 1) && (turn == 1)); 这个循环里。这意味着flag1 == 1(dekker1想进入)且turn == 1(轮到他让梨)。一旦 dekker1 获得CPU时间并进入其函数,它会在执行完临界区后,将flag1设置为0。此时,dekker0的循环条件 flag1 == 1 就不再成立,它便可以跳出循环、进入临界区。因此,任何一个线程都不会被无限期地阻塞。
运行测试
在实际的Linux环境下,我们可以创建两个POSIX线程来测试这个算法:
(void) pthread_create(&thread1, NULL, task0, NULL);
(void) pthread_create(&thread2, NULL, task1, NULL);
总结与思考
Dekker算法堪称计算机科学中“礼让”哲学的典范。它是一种wait-free设计思想的早期展现。其最大优势在于,它不依赖于任何特殊的硬件原子指令(如CAS, Compare-And-Swap),仅通过普通的内存读写就实现了安全的互斥,因此在特定的硬件或理论模型下非常高效。
你可能会觉得,每次进入前都要“让一下”的做法(特别是那个忙等待循环while)会导致性能损失。但请注意,它的全局高效性体现在避免了锁机制的开销和复杂性。当然,在现代处理器普遍支持原子指令(如CAS)的今天,高性能并发程序通常采用更高级的无锁数据结构(Lock-Free Data Structures)。然而,理解Dekker算法这样的基石,对于我们洞悉并发问题的本质、优化系统性能至关重要。
参考资料
https://en.wikipedia.org/wiki/Dekker%27s_algorithm
 发表于 2026-2-1 19:57:55
|
查看: 209|
回复: 0
发表于 2026-2-1 19:57:55
|
查看: 209|
回复: 0
