就在今天凌晨,AI领域的两大巨头几乎同时发布了重要的模型更新。Anthropic率先推出了Claude Opus 4.6,仅仅20分钟后,OpenAI紧接着发布了GPT-5.3-Codex。
对于许多开发者,尤其是一线的前端工程师而言,看到这类消息,一个经典的话题又浮上心头。

事实上,这次发布并非毫无预兆。最近几天,不少开发者在交流中都反馈,感觉手头的模型似乎“变笨了”,输出质量有所下降。

也有观点认为,这可能是厂商在为新模型的上线做铺垫,通过临时调整旧模型的性能来凸显新版本的提升。

那么,这次深夜对飙发布的两个新模型,究竟带来了哪些实质性的升级?它们各自在哪些场景下更具优势?我们又该如何看待人工智能浪潮下开发者的角色演变?本文将进行详细拆解。
Claude Opus 4.6:长上下文与多智能体协作
Anthropic此次发布的Opus 4.6,主要聚焦于三个方向的突破。
首次支持1M Token上下文
这是Opus系列模型首次将上下文窗口扩展至100万Token。同时,其单次输出上限也从64K Token提升到了128K Token。这意味着开发者现在可以一次性提交整个代码库或长篇技术文档,让模型进行全局分析、生成完整模块或执行大规模重构,以往需要多次交互拆解的任务,现在有望一轮对话搞定。
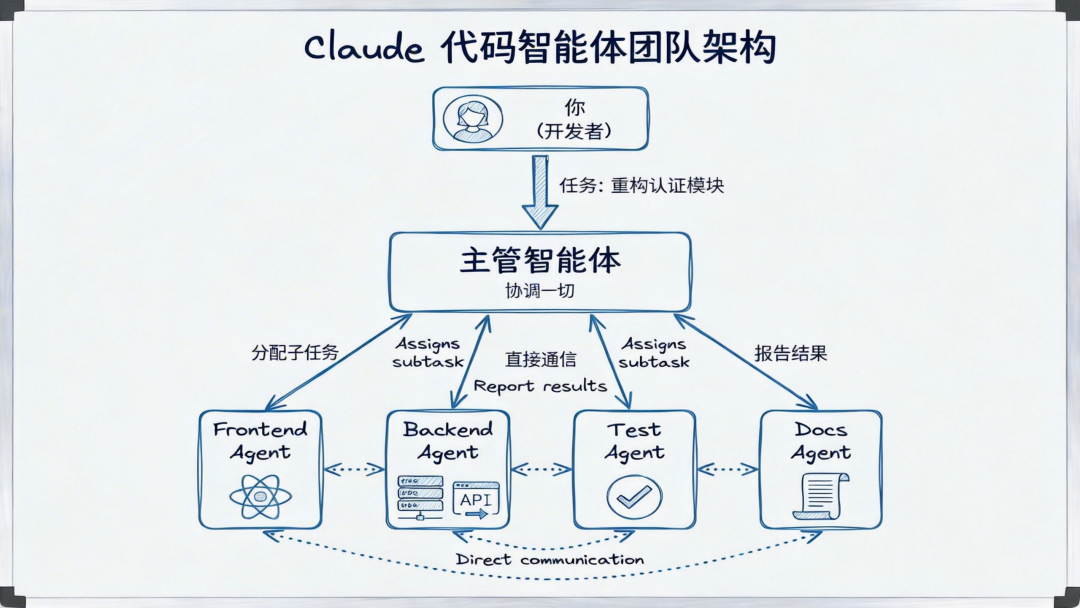
Agent Teams:多智能体并行工作
Claude Code现在支持多个智能体(Agent)并行协作。例如,在处理一个全栈重构任务时,可以同时启动前端Agent、后端Agent和测试Agent,它们各司其职,最后将结果汇总。
这与传统的子代理(Sub-agents)模式不同。在Agent Teams架构中,团队成员之间可以直接沟通,相互质疑和验证对方的方案,更贴近真实的人类团队协作模式。这种方式特别适合可以拆分为多个独立子任务的复杂场景,比如大型项目的代码审查、多模块系统重构等。
自适应思考与上下文压缩
Opus 4.6引入了“自适应思考”(Adaptive Thinking)机制,模型可以自动判断当前任务需要深度推理还是快速响应。开发者也可以手动设置思考强度档位(low, medium, high, max),根据任务复杂度灵活调配计算资源。
另一个关键功能是“上下文压缩”(Context Compaction)。当对话历史接近上下文长度上限时,Claude会自动将较早的、不那么重要的对话内容压缩成精炼的摘要,从而为新对话腾出空间。这有效解决了长对话中的“上下文溢出”问题,使得Claude能够执行更长时间的连续任务而不中断。
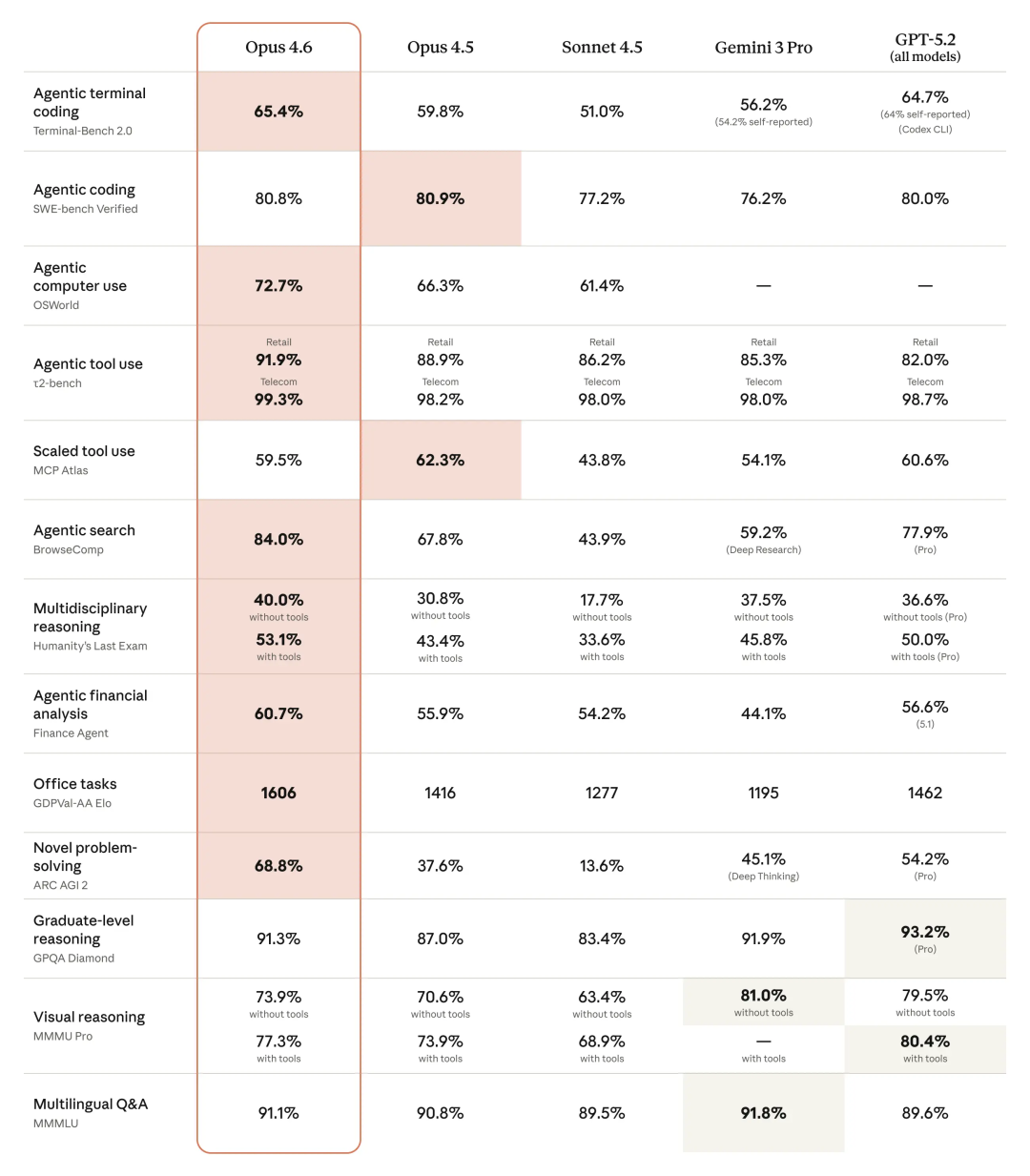
基准测试表现
根据官方数据,Opus 4.6在多个关键基准测试中取得了领先成绩:
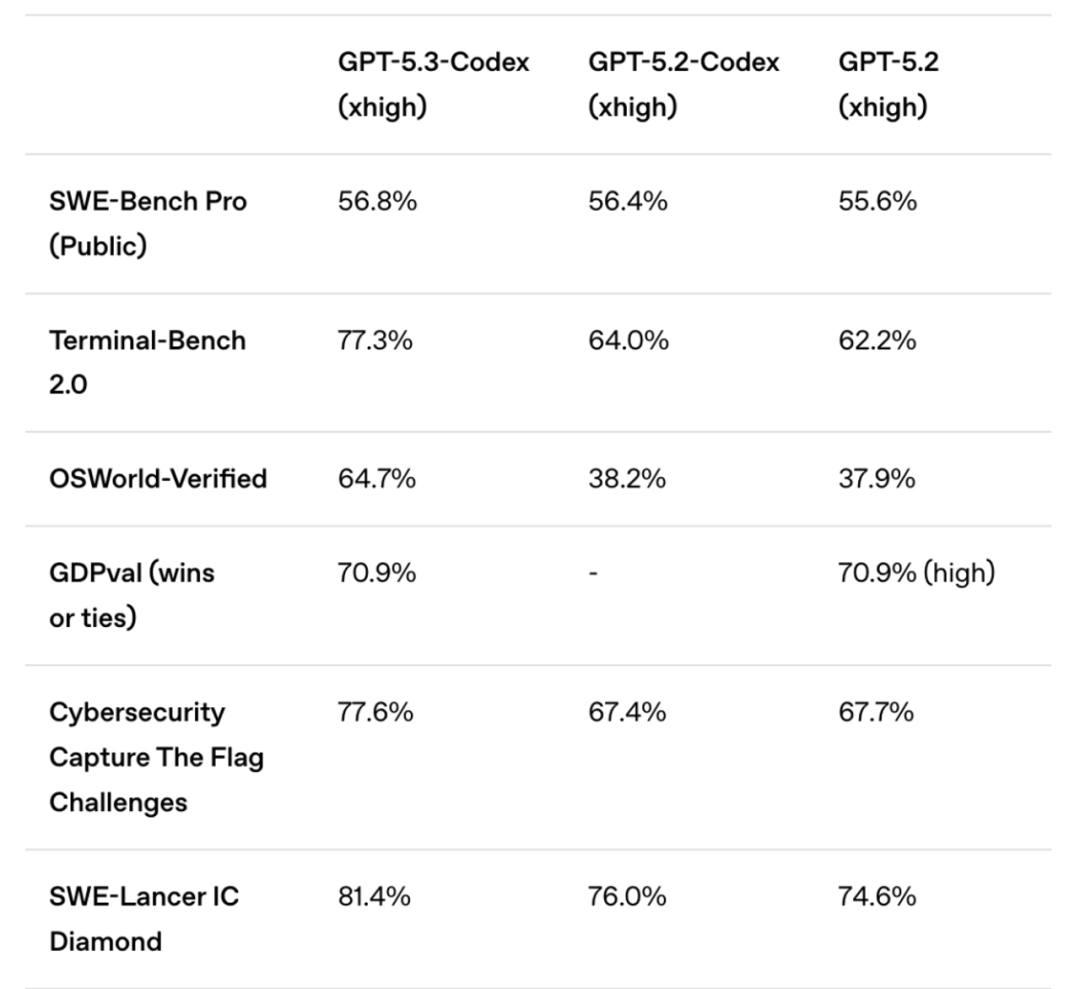
- Terminal-Bench 2.0(衡量AI在终端环境中编程、调试、部署的能力):65.4%
- GDPval-AA(模拟知识工作任务的基准):比GPT-5.2高出144个Elo等级,相当于10局对战能赢7局。
- BrowseComp(网络搜索与信息整合能力):84.0%
- ARC AGI 2(测试流体智力和新颖问题解决能力):68.8%
GPT-5.3-Codex:效率飞跃与“AI造AI”
OpenAI推出的GPT-5.3-Codex,则主要将升级重点放在了效率和自主性上。
首个参与自身开发的AI模型
OpenAI宣称,GPT-5.3-Codex是其首个在自身创造过程中发挥关键作用的模型。Codex的开发团队利用早期版本的5.3-Codex来调试训练过程、管理部署基础设施、诊断测试结果和分析性能评估。这种“AI辅助开发AI”的模式,可能开启一种递归式的加速循环:AI能力越强,它辅助开发出的下一代AI就越好用。
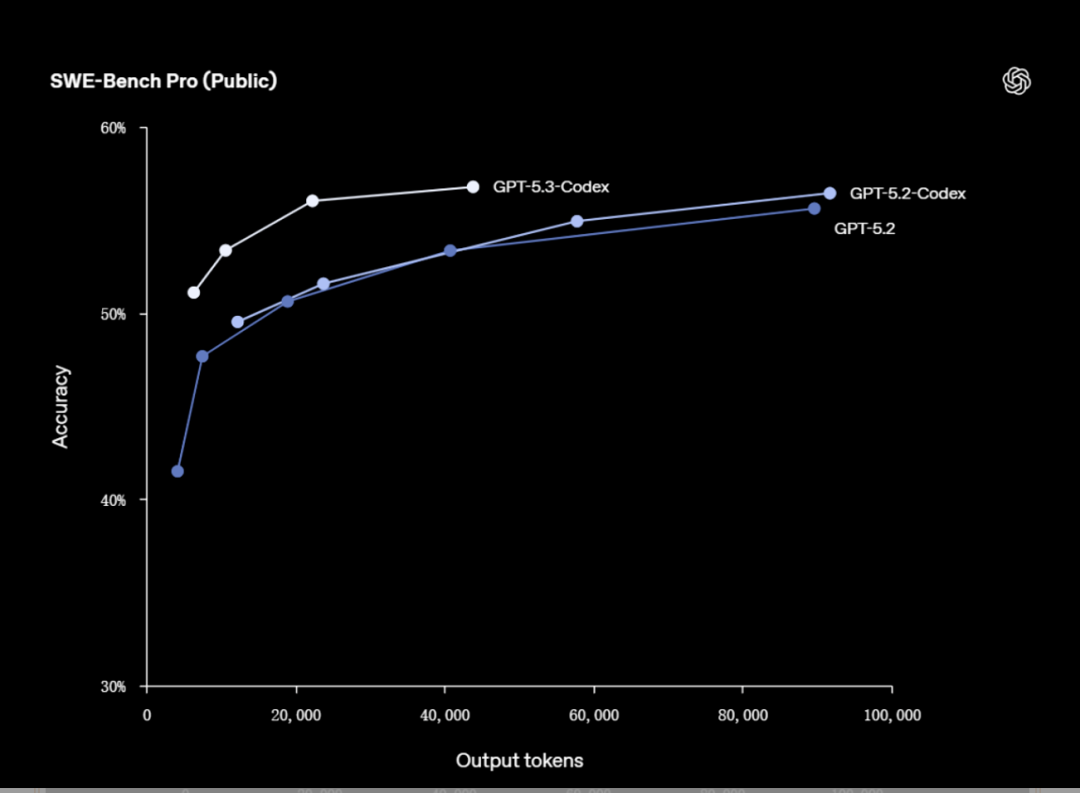
效率的大幅提升
GPT-5.3-Codex在完成相同复杂度的任务时,所消耗的Token数量不到上一代(GPT-5.2-Codex)的一半,同时单Token的处理速度提升了约25%。对于需要长时间运行或频繁迭代的编码任务来说,这意味着更低的成本和更快的开发周期。
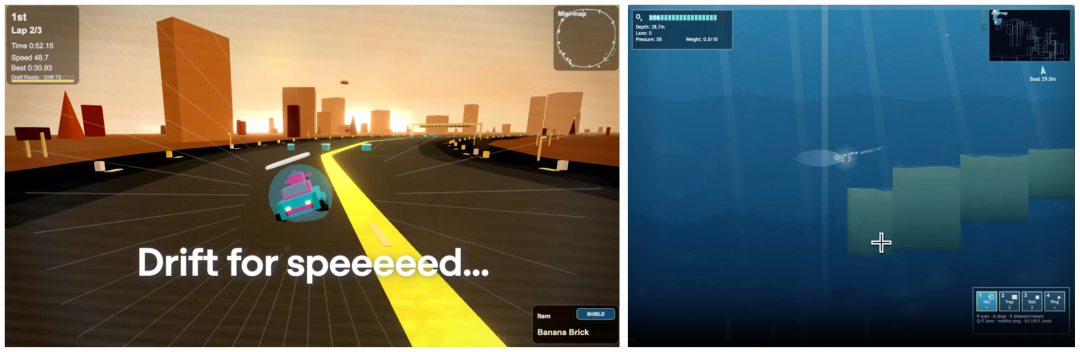
该模型支持超过24小时的连续任务执行。在OpenAI的内部测试中,Codex曾连续工作数天,自主开发了两个功能完整的网页游戏:一个包含多地图、车手和道具系统的赛车游戏,以及一个包含珊瑚礁探索、氧气和压力管理机制的潜水游戏。这充分展示了其在大规模上下文(数百万Token)中持续进行迭代和开发的能力。
支持实时交互与调整
过去使用Codex执行长任务时,如果中途想要改变方向会比较麻烦,往往需要重头开始。新版本支持开发者在任务执行过程中实时介入,提出新的要求或调整方向,模型不会丢失之前的上下文。它会主动汇报当前进展和关键决策点,允许开发者随时提问、讨论方案并进行引导。
基准测试表现
GPT-5.3-Codex在多项编程与操作基准上表现突出:
- Terminal-Bench 2.0:77.3%(相比5.2-Codex的64.0%提升了13.3个百分点)
- OSWorld-Verified(视觉化的桌面操作任务):64.7%,已接近人类基准水平的72%。
- SWE-Bench Pro(多语言软件工程问题解决):56.8%
- 网络安全CTF挑战赛:77.6%
正面交锋:谁在编码能力上更胜一筹?
两家公司都发布了一系列亮眼的基准测试成绩,但由于测试集和评估方法不同,大多数数据无法直接横向比较。目前唯一一个双方都采用、且测试条件相对可比的基准是 Terminal-Bench 2.0。这项测试专门衡量AI在终端环境中像真正工程师一样写代码、调试和部署的综合能力。
直接对比结果如下:
GPT-5.3-Codex:77.3% vs Claude Opus 4.6:65.4%
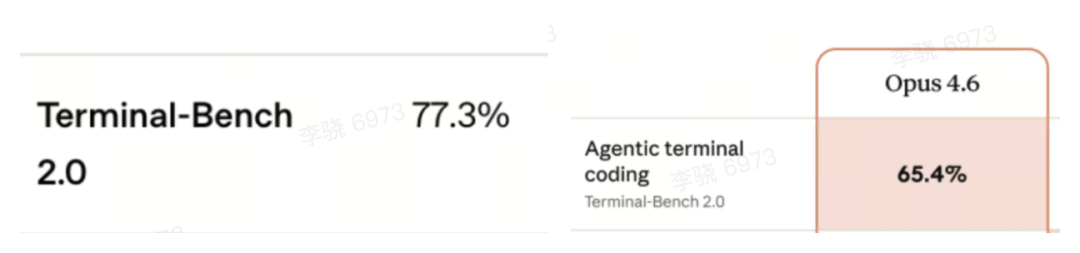
在这一衡量核心编程Agent能力的战场上,OpenAI暂时守住了其领先优势。
其他指标为何不能直接对比?以SWE-Bench为例,Claude使用的是“Verified”版本(约500道题,主要为Python),而GPT使用的是“Pro”版本(731道题,涵盖多语言,且经过了抗数据污染处理)。OSWorld测试也存在类似情况,Claude基于原版,GPT则使用了修复了300多个数据问题的“Verified”版。
因此,我们可以得出的结论是:两大模型各有侧重,优势场景不同。 GPT-5.3-Codex在编程效率、执行速度和终端操作上表现更强;而Claude Opus 4.6在超长上下文理解、复杂任务的多智能体协作方面更具优势。但它们的演进方向是一致的:追求更高的自主性、能够执行更长时间的任务、减少对人类干预的依赖。
开发者该如何选择与定位?
面对这些日益强大的AI编码助手,开发者该如何利用它们,又该如何规划自身的职业路径呢?
从工具选型角度看,可以根据任务特性进行选择:
- GPT-5.3-Codex:目前依然是最适合进行严肃、严谨工程编码的模型。其输出质量高,代码结构规范,但思维模式偏重逻辑,在需要“说人话”的沟通场景或创意发散上相对较弱。
- Claude Opus 4.6:思维更加活跃和发散,这既是优点也是缺点。优点在于适合进行头脑风暴、需求沟通、撰写文章等需要创造力的工作;缺点则是在严谨编码时,可能因思维过于跳跃而导致输出结果不可控。
- Gemini:在审美和设计感上普遍评价较高,适合进行UI设计、图标生成等与视觉艺术相关的任务。

玩笑归玩笑,AI能力的极速进化确实需要我们认真思考开发者的未来。一个核心趋势是:单纯的技术实现壁垒正在快速降低。当编写标准业务代码变得越来越容易时,技术本身带来的“技能溢价”必然会减少。
那么,什么能力在AI时代会变得更加珍贵?创造力、业务洞察力、系统设计能力、批判性思维、沟通协作以及快速学习新技术本质的能力,这些或许将成为开发者新的核心竞争力。我们应该将更多精力投入到这些“软技能”和“元能力”的培养上,利用AI作为杠杆,完成价值的转移与升维,而不是与它在重复劳动上竞争。

技术的发展浪潮不会停歇,与其焦虑是否被取代,不如主动拥抱变化,探索如何让AI成为自己强大的助手和放大器。无论是深入研究前端框架与AI的结合,还是参与开源实战项目来积累可迁移的经验,持续学习和实践才是应对变化的根本之道。在技术社区如云栈社区与同行交流碰撞,也能帮助我们更好地把握方向。
 发表于 2026-2-7 07:13:53
|
查看: 242|
回复: 0
发表于 2026-2-7 07:13:53
|
查看: 242|
回复: 0
