在基于STM32G070微控制器开发多串口通信应用时,偶尔会遇到某个串口通信异常挂起的问题:无法再进入接收中断服务函数,但能进入接收回调函数,而其他串口通信正常,系统其他功能也未受影响。
问题分析与定位
起初的怀疑方向是多串口中断可能导致的资源抢占与冲突。为此,尝试在接收回调函数中使用 if-else if 条件判断来确保同一时刻只有一个串口的接收中断能进入处理流程,但问题依旧偶发。
进一步排查时,注意到某些资料提到早期HAL库的接收中断内部存在加锁/解锁机制,在高数据量下可能导致串口锁死。但在项目使用的STM32Cube_FW_G0_V1.6.0版本中并未发现此设计。
最终,通过查询“overrun”(过载溢出)相关资料找到了线索。仿真调试发现,当串口通信挂掉时,状态寄存器(ISR)中的ORE(Overrun Error)标志位确实被置位,从而定位到根本原因。
问题解决:清除ORE标志
ORE标志位位于USART中断和状态寄存器(ISR)的第3位,如下图所示:

提示:部分型号可通过配置寄存器中的OVRDIS位来关闭ORE错误检测(不推荐,有丢数风险),配置位置如下:

以下是三种可行的解决方案,其中第三种最为推荐。
方案一:在串口错误回调函数中处理
在 HAL_UART_ErrorCallback 函数中检测并清除ORE标志,然后重新启动接收中断。示例代码逻辑如下:
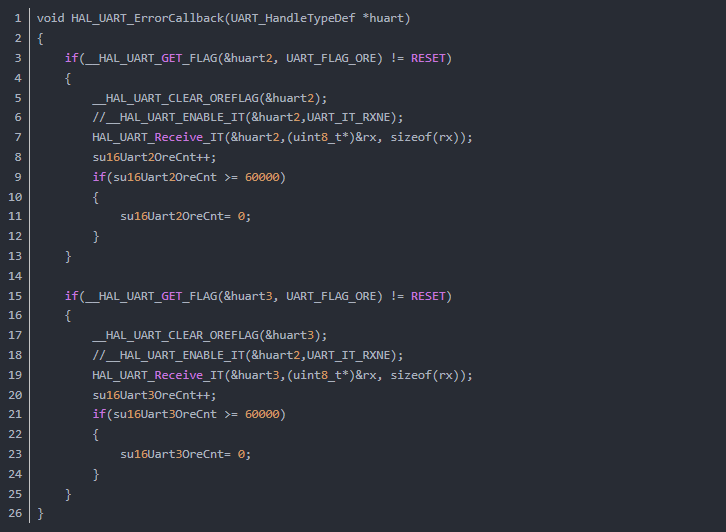
潜在问题:实际测试中发现,该方法在成功清除几次后,错误回调函数可能不再被触发,原因不明,可靠性一般。
方案二:关闭ORE检测功能(不推荐)
在STM32CubeMX的串口配置中,默认使能了Overrun Detection。可以关闭此功能,但这样做的风险是当发生溢出时,新数据会直接覆盖旧数据而不会产生错误标志,导致数据静默丢失,不利于系统健壮性。
方案三:定时巡检清除ORE(推荐)
建立一个周期性的定时任务(例如每500ms),主动检查所有串口的ORE标志。若发现置位,则清除该标志并重新启动该串口的接收中断。这种方法不依赖于是否能进入错误回调,最为稳定可靠。
// 定时检测并清除ORE标志
void PS_Modules_Uart_Clear_ORE(void){
static uint16_t su16OreCnt = 0;
su16OreCnt++;
if(su16OreCnt > 500) // 假设定时器中断为1ms一次,此处实现500ms巡检
{
su16OreCnt = 0;
if(__HAL_UART_GET_FLAG(&huart1, UART_FLAG_ORE) != RESET){
__HAL_UART_CLEAR_OREFLAG(&huart1);
HAL_UART_Receive_IT(&huart1, (uint8_t*)&rx1_buf, sizeof(rx1_buf));
}
if(__HAL_UART_GET_FLAG(&huart2, UART_FLAG_ORE) != RESET){
__HAL_UART_CLEAR_OREFLAG(&huart2);
HAL_UART_Receive_IT(&huart2, (uint8_t*)&rx2_buf, sizeof(rx2_buf));
}
// ... 检查huart3, huart4
}
}
在实际压力测试中(两个串口持续通信2小时),采用此方案后通信始终保持正常。通过日志发现,期间串口2和串口3分别触发了4次和3次ORE清除操作,证明了该机制的有效性。这种方法的核心是建立一个可靠的“看门狗”机制,通过定时器中断来保障外设的状态健康。
ORE过载溢出产生原因
从根本上理解ORE置位的时机至关重要。参考手册说明如下:

当接收数据寄存器(RDR)已满(RXNE=1),且移位寄存器中正在接收的新数据已准备好转移到RDR时,硬件会自动设置RXNE标志。但是,如果RDR中的数据还未被读取(RXNE仍为1),移位寄存器中又有一个新数据接收完成并准备转移,此时就会发生过载(Overrun),ORE位被置为1。
STM32F1系列手册中的描述更为直白:

它指出,ORE标志可以通过软件序列(先读状态寄存器SR,再读数据寄存器DR)来清除。
对于STM32G070,除了上述方法,也可以通过直接读取中断标志清除寄存器(ICR) 中的ORECF位来清零ORE标志,如下图所示:

 发表于 2025-12-19 19:08:06
|
查看: 209|
回复: 0
发表于 2025-12-19 19:08:06
|
查看: 209|
回复: 0
