很多运维工程师都曾深受Prometheus存储问题的困扰:当监控数据量增长到一定规模后,内存溢出(OOM)成为常态,扩展存储往往意味着服务中断,查询半年以前的历史指标时浏览器都可能陷入卡顿。
最近,我将生产环境的监控系统全量迁移至VictoriaMetrics(简称VM)集群版。本文将分享这套具备“高可用、读写分离、无限水平扩容”特性的完整部署方案,内容聚焦于实战操作。
为什么需要集群版?
Prometheus功能强大,但其架构属于“单体”设计,数据写入、存储和查询功能全部耦合在同一个进程中。VictoriaMetrics集群版的精妙之处在于,它将整个监控流水线拆分为四个独立的角色,实现了职责分离。
-
采集端:vmagent(轻量强悍)
- 资源消耗低:其内存占用通常仅为Prometheus的1/5左右。
- 本地缓存:通过
-remoteWrite.tmpDataPath参数,可在后端存储故障时,在本地磁盘暂存数GB的监控数据,避免数据丢失。
-
写入端:vminsert(流量调度器)
vminsert组件是无状态的。它接收来自vmagent的数据流,通过一致性哈希算法进行计算,确定每条数据应该被路由到哪一个vmstorage节点进行存储。
- 多租户支持:URL路径中的
accountID(例如/insert/0/)在此处被解析和处理,实现了逻辑层面的数据隔离。
-
存储端:vmstorage(数据仓库)
这是整个集群中唯一的有状态组件,建议以StatefulSet形式部署。
- 数据分片:每个
vmstorage节点不感知其他节点的存在,仅负责存储通过哈希算法分配给自己那份数据分片。
- 高效压缩:VM采用了自研的存储引擎,其磁盘空间占用通常只有Prometheus原始数据的1/7,极大降低了云原生环境下的存储成本。
-
查询端:vmselect(聚合计算器)
它是查询请求的入口。当Grafana发起查询时,vmselect会并行地向所有vmstorage节点广播请求,获取相关数据分片,然后在内存中完成聚合计算,最终将结果返回给客户端。
部署实战:采用Operator模式
在Kubernetes环境中,强烈推荐直接使用VictoriaMetrics Operator进行部署,避免手动编写和维护复杂的Deployment配置清单。
1. 关键配置 values.yaml
安装官方Helm Chart时有一个常见陷阱:必须显式禁用默认的单机模式(vmsingle),否则Operator会因配置冲突导致Pod持续启动失败。
# 核心 values.yaml 配置
vmsingle:
enabled: false # 关键点:必须关闭,才能启用集群模式
vmcluster:
enabled: true
spec:
retentionPeriod: "30d" # 数据保留时间
replicationFactor: 2 # 生产环境建议至少2副本,保证数据可靠性
vmstorage:
replicaCount: 2
storage:
volumeClaimTemplates:
spec:
storageClassName: "ssd-storage" # 重要:务必使用SSD,机械硬盘IO无法满足高并发查询
resources:
requests:
storage: 100Gi
vminsert:
replicaCount: 2 # 写入入口,可水平扩展
vmselect:
replicaCount: 2 # 查询入口,可水平扩展
2. 执行安装命令
helm repo add vm https://victoriametrics.github.io/helm-charts/
helm repo update
helm install vms vm/victoria-metrics-k8s-stack -f values.yaml -n monitoring --create-namespace
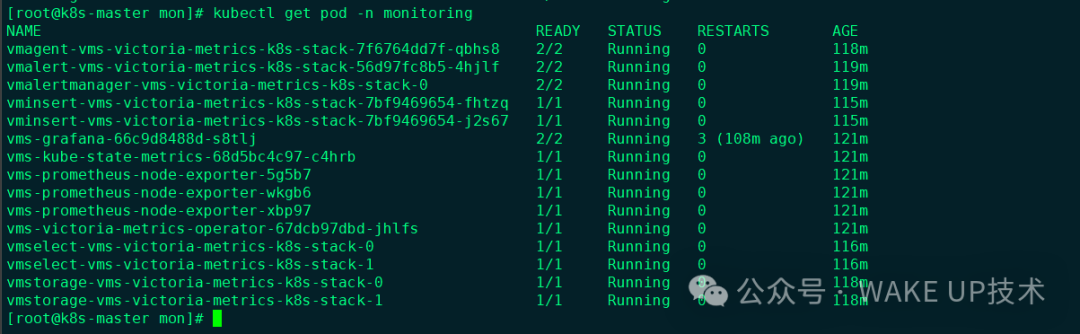
进阶配置:如何访问内部服务的管理界面?
默认安装完成后,vmagent和vmselect的Web UI无法从集群外部直接访问,因为其Service类型为ClusterIP。不建议直接修改Operator创建的原始Service,它们可能被自动重置。最稳妥的方式是额外创建两个NodePort类型的Service。
查看采集目标状态(vmagent UI)
需要检查哪些监控目标(Target)失联?可以通过http://<节点IP>:30429/targets访问。
apiVersion: v1
kind: Service
metadata:
name: vmagent-nodeport
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 8429
nodePort: 30429
selector:
app.kubernetes.io/name: vmagent
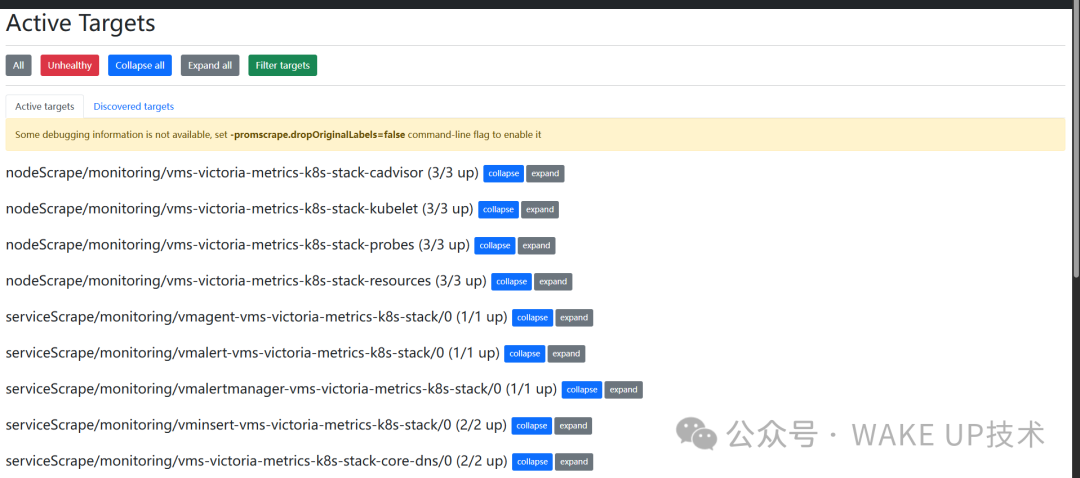
查询原始数据与调试(vmselect UI)
想直接执行PromQL查询原始数据?访问http://<节点IP>:30481/select/0/vmui/。内置的VMUI界面提供了强大的查询分析器,特别适合处理大批量指标的检索与调试。
apiVersion: v1
kind: Service
metadata:
name: vmselect-nodeport
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 8481
nodePort: 30481
selector:
app.kubernetes.io/name: vmselect
架构解析:如何实现存储的无感水平扩容?
有些开发者会疑惑:数据被分散存储在不同的Pod中,容量该如何扩展?
这正是VictoriaMetrics集群版设计的核心优势。vminsert会根据时间序列的标签集计算哈希值来决定其归属。假设初始集群有2个vmstorage节点(仓库A和B)。当存储空间即将耗尽时,你只需要将vmstorage的replicaCount从2改为4。
新的存储节点C和D会立即启动并加入集群。此后新写入的监控数据,会通过哈希算法被重新分配,部分数据自然会流入新的节点C和D。在进行查询时,vmselect组件会作为协调者,向A、B、C、D所有节点并行发起查询,并将各节点返回的部分结果在内存中拼接成完整的曲线返回。对于用户和上游系统(如Grafana)而言,存储容量扩大了,但查询体验没有丝毫影响,这就是真正的水平扩容能力。
生产环境最佳实践建议
- Grafana数据源配置:在Grafana中添加数据源时,类型选择“Prometheus”,URL填写集群内部Service地址:
http://vmselect-vms-victoria-metrics-k8s-stack:8481/select/0/prometheus/。注意路径中的/0/是默认租户ID,不可遗漏。
- 多租户数据隔离:如果公司内部存在多条业务线,可以为不同的
vmagent配置不同的租户ID(例如将写入路径改为/insert/1/)。数据在底层存储中是逻辑隔离的,互不干扰,这为运维/DevOps团队管理多业务监控提供了便利。
- 关注指标基数:VictoriaMetrics的压缩效率极高,单个指标数据点平均占用的磁盘空间通常不到1字节。如果发现磁盘容量增长异常,应检查是否有指标的标签(Label)组合过多(即“基数爆炸”问题),务必利用Relabeling机制提前进行过滤和裁剪。
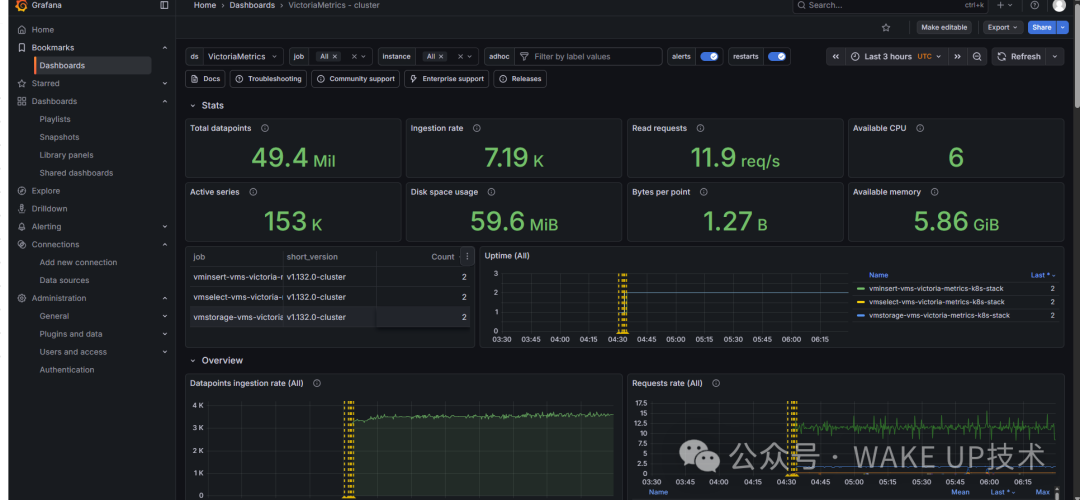
对于正在构建或改造大规模运维/DevOps监控体系的团队,VictoriaMetrics集群版提供的这套高可用、易扩展的解决方案,具有很强的参考和实用价值。
 发表于 2025-12-21 22:00:01
|
查看: 311|
回复: 0
发表于 2025-12-21 22:00:01
|
查看: 311|
回复: 0
