1 程序结构优化
1.1 程序的书写结构
书写格式本身不会直接影响生成代码质量,但工程实践中应遵循统一的代码风格。结构清晰、层级分明的程序,更利于后期维护与协作。
对于 while / for / do...while / if...else / switch...case 以及它们的嵌套组合,建议统一采用“缩进对齐”的书写方式,避免逻辑层级混乱。
1.2 标识符(命名规范)
用户自定义标识符除了满足命名规则外,不建议使用 a、b、x1、y1 这类“代数式”命名。应尽量选用语义明确的英文单词(或缩写)/拼音,提升可读性,例如:count、number1、red、work 等。
1.3 程序结构(结构化与模块化)
C 语言提供了完善的流程控制结构。用 C 语言开发单片机应用时,应尽量采用结构化的设计方法,让程序结构清晰,便于调试与维护。
对于较大的应用程序,通常按功能拆分为多个模块:
- 不同模块负责不同任务,可分别编写与测试
- 在 C 语言中,一个函数通常就可以视为一个模块
模块化不仅是“拆分”,更重要的是模块之间变量尽量相互独立:
- 尽量少用全局变量,保持模块封装性
- 常用功能模块可进一步封装为库,方便复用
同时要注意:模块拆得过细会增加函数调用开销(入栈/出栈、寄存器保护与恢复等),可能降低执行效率,需要在“可维护性”和“效率”之间平衡。
1.4 定义常数(提升可维护性)
对经常使用的常数,不建议直接“硬编码”到逻辑中。否则一旦数值变化,就需要全局搜索逐个修改,维护成本高且容易漏改。
更推荐用预处理或集中定义的方式管理常量:
1.5 减少判断语句(条件编译优先)
能用条件编译(如 #ifdef)解决的场景,尽量不要用运行期 if。条件编译有助于减少最终生成代码长度。
1.6 表达式(优先级清晰、避免过复杂)
当表达式中的运算优先级容易混淆时,应使用括号明确优先级。表达式也不宜过度复杂,否则时间久了连作者自己也难以读懂,不利于维护。
1.7 函数(声明一致、宏替换时机)
函数使用前应正确声明类型,并确保与定义一致:
- 无返回值使用
void
- 无参数也应明确参数列表(按项目规范处理)
如果需要缩短代码长度,可以把公共逻辑抽为函数复用。
如果更看重执行时间,在程序调试稳定后,可将部分函数替换为宏以减少调用开销。注意:宏展开后很多编译器才报错,会增加定位难度,因此建议在调试结束后再进行宏化。
1.8 少用全局变量,多用局部变量
全局变量通常占用数据存储器空间。全局变量过多可能导致编译器内存分配不足。
局部变量往往更容易被编译器放入寄存器:
- 访问速度更快
- 指令更灵活,生成代码质量更高
- 不同模块中的寄存器/栈空间可复用,提高资源利用率
1.9 设定合适的编译选项(优化等级要谨慎)
多数编译器提供多种优化选项。使用前应理解各选项含义并选择最适配的一档。盲目使用最高级优化可能导致编译器“过度优化”,在某些情况下影响程序正确性,引入运行异常。
建议熟悉所用编译器:
- 哪些参数会受优化影响
- 哪些行为不会改变
- 关键路径建议做针对性验证与回归测试
2 代码的优化
2.1 选择合适的算法和数据结构
应熟悉常见算法与复杂度差异:
- 顺序查找可替换为二分查找或更合适的检索方式
- 冒泡/插入排序可在合适场景替换为快速排序、归并排序等
这些调整往往能显著提升执行效率(可参考 算法与数据结构 相关专题进一步系统梳理)。
数据结构同样关键:在随机数据中若插入/删除操作频繁,结构选择会直接影响性能。数组与指针关系紧密:
- 指针更灵活简洁
- 数组更直观易读
不少编译器下,指针可能生成更短、更高效的代码;但在 Keil 场景中也存在“数组比指针更省代码”的情况,需要结合编译器实际表现评估。
2.2 使用尽量小的数据类型
能用 char 定义的变量,就不要用 int;能用 int 的就尽量不要上升到 long int;非必要尽量避免 float(尤其在无硬件浮点支持的 MCU 上代价更高)。
同时注意:变量赋值不要超出其取值范围。C 编译器通常不会替你报错,但运行结果可能错误且难以排查。
2.3 使用自加/自减与复合赋值
++/-- 以及 a+=1、a-=1 往往能生成更高质量的指令(如 inc/dec)。而 a=a+1、a=a-1 在不少编译器上可能生成更长的指令序列(常见 2~3 字节),影响代码量与速度。
2.4 减少运算强度(用等价低成本表达式替换)
(1) 求余运算
a = a % 8;
可改为:
a = a & 7;
说明:位操作通常只需一个指令周期,而不少 C 编译器的 % 会调用子程序实现,代码更长、速度更慢。只要是对 [2^n] 取模(求余),通常都可以用位运算替代。
(2) 平方/乘方运算
a = pow(a, 2.0);
可改为:
a = a * a;
说明:在带硬件乘法器的 MCU 中(如部分 51 系列),乘法通常比浮点 pow 快得多;pow 往往通过库函数调用实现,开销更大。即便在没有硬件乘法器的场景,乘法子程序通常也比 pow 更短更快。
三次方示例:
a = pow(a, 3.0);
可改为:
a = a * a * a;
一般可获得更明显的效率提升。
(3) 用移位实现乘除法
a = a * 4;
b = b / 4;
可改为:
a = a << 2;
b = b >> 2;
说明:乘/除 [2^n] 通常可用移位代替。在一些编译器(如 ICCAVR)中,乘以 [2^n] 会直接生成移位;而乘以其它整数或除以任意数可能调用乘除法子程序,效率与代码量都不占优。
更一般地,整数乘法也可拆解为移位加法,例如:
a = a * 9;
可改为:
a = (a << 3) + a;
2.5 循环
(1) 把不变的工作移出循环
对不需要循环变量参与运算的任务(表达式计算、函数调用、指针运算、数组访问等),尽量放到循环外,在 init 或初始化阶段统一完成,减少重复开销。
(2) 延时函数(自减循环通常更省)

两个函数的延时效果相近,但多数 C 编译器对“自减到 0”的写法生成的代码往往更短(常见少 1~3 字节)。原因是很多 MCU 有“为 0 转移”的指令支持;while 循环同理,用自减控制循环通常也更省代码。
注意:若循环变量 i 参与数组索引,使用预减循环可能引发数组越界,需要格外谨慎。
(3) while 与 do...while

在这两种循环中,do...while 往往比 while 编译后生成的代码更短。
2.6 查表(用空间换时间)
在 MCU 程序里尽量避免复杂运算(如浮点乘除、开方、复杂模型插补等)。这类运算既耗时又耗资源,更推荐用查表法,并将数据表放在程序存储区。
如果直接生成表较困难,也可在启动阶段计算一次,将表生成到数据存储器中;运行期直接查表,减少重复计算。
2.7 其它技巧
例如:使用在线汇编、把字符串与常量尽量放在程序存储器等,通常也有助于压缩代码量与提升效率。
3 乘除法优化(小资源 8 位 MCU 场景)
在小资源 8 位 MCU(程序存储空间 1K/2K 等)中,常见情况是缺少硬件乘法/除法指令。若完全依赖编译器调用内部函数库实现乘除法,容易出现:
本文以晟矽微电子 MC30、MC32 系列(RISC 架构)指令集为例,结合汇编与 C 编译平台,给出一种更省时、更省资源的乘除法思路,便于移植与理解。
3.1 乘法篇(移位 + 累加)
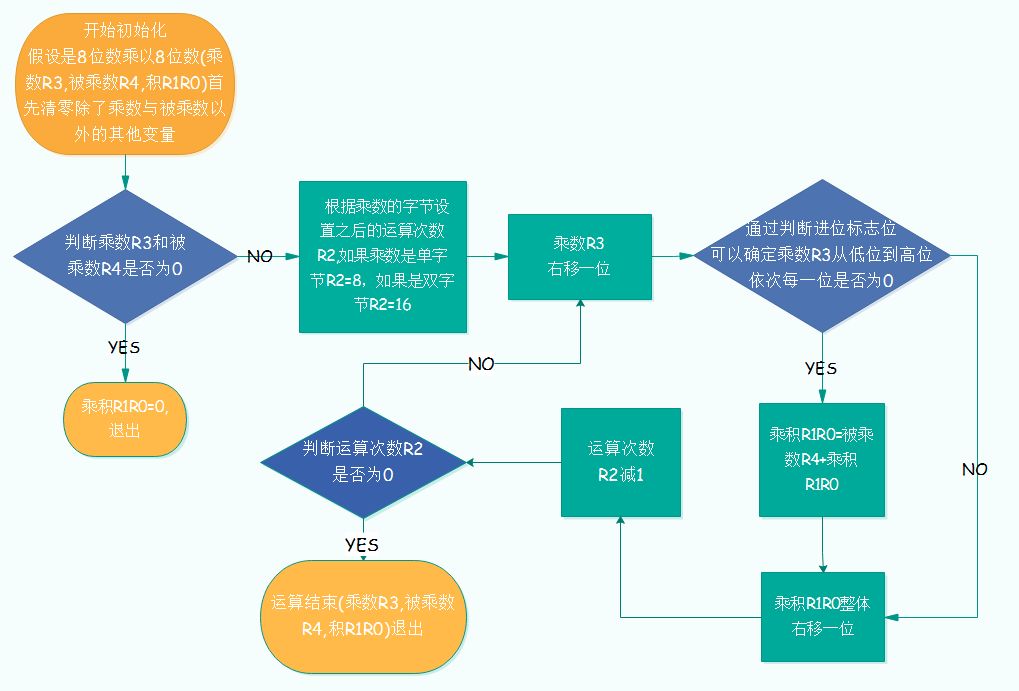
单片机乘法本质是二进制乘法:对乘数每一位进行判断,若该位为 1,则把被乘数左移对应位数后累加到乘积。
示例:乘数 R3=01101101,被乘数 R4=11000101,乘积 R1R0。步骤概览:
1)清空乘积 R1R0
2)乘数第 0 位为 1:把 R4<<0 加到 R1R0
3)乘数第 1 位为 0:忽略
4)乘数第 2 位为 1:把 R4<<2 加到 R1R0
5)乘数第 3 位为 1:把 R4<<3 加到 R1R0
6)乘数第 4 位为 0:忽略
7)乘数第 5 位为 1:把 R4<<5 加到 R1R0
8)乘数第 6 位为 1:把 R4<<6 加到 R1R0
9)乘数第 7 位为 0:忽略
10)累加完成后,R1R0 即最终乘积
结果表达式:
R1R0 = R3 * R4
= (R4<<6) + (R4<<5) + (R4<<3) + (R4<<2) + R4
= 101001111100001
流程图:
运行效率对比(汇编 vs C)
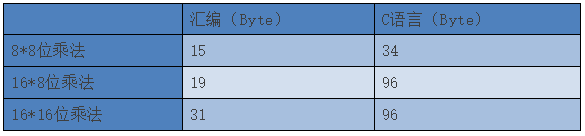
下表为运行效率对比(数据可能有小偏差),整体可见汇编实现耗时更低:

代码量对比(汇编 vs C)
下表为代码量对比(数据可能有小偏差),汇编实现占用空间更小:
综合来看,当原方案遇到“程序空间不够”或“运行时间过长”等瓶颈时,可以按上述思路对关键乘法路径进行替换与优化。
汇编语言更贴近机器执行:能直接操作寄存器并调整指令顺序。但不同平台的指令集与指令周期差异较大,移植与维护成本更高。因此这里以精简指令集为例给出乘法例程,便于迁移与理解。




3.2 除法篇(按位试商,本质可视作减法)
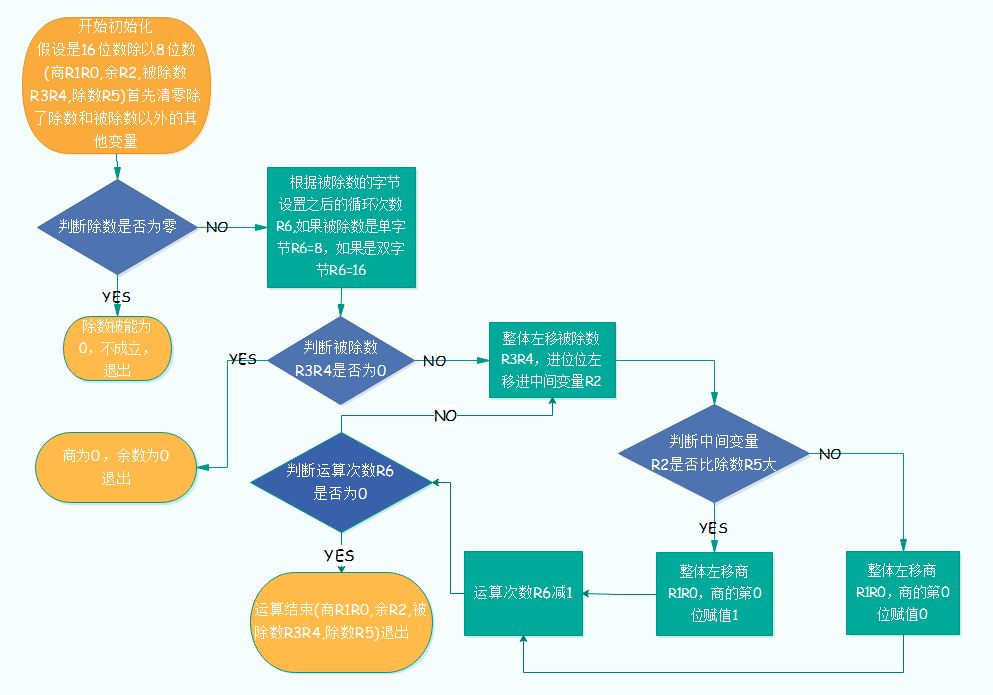
单片机除法同样是二进制除法:从被除数高位开始,逐位“放开”并与除数比较,得到商位与余数;余数再与下一位拼接继续迭代。由于每一步商最大只有 1,实际实现时可把每一步近似看成“比较 + 减法/不减法”。
示例:被除数 R3R4=1100110001101101,除数 R5=11000101,商 R1R0,余数 R2。步骤概览:
1)清空商 R1R0 与余数 R2
2)放开第 15 位:为 1,小于除数,商位为 0,余数为 1
3)并入第 14 位:得 11,仍小于除数,商位为 0,余数为 11
4)…直到放开第 8 位:得 11001100,大于除数,商位为 1,余数为 111
5)并入第 7 位:得 1110,小于除数,商位为 0,余数为 1110
6)并入第 6 位:得 11101,小于除数,商位为 0,余数为 11101
7)…直到放开第 3 位:得 11101101,大于除数,商位为 1,余数为 101000
8)并入第 2 位:得 1010001,小于除数,商位为 0,余数为 1010001
9)并入第 1 位:得 10100010,小于除数,商位为 0,余数为 10100010
10)并入第 0 位:得 101000101,大于除数,商位为 1,余数为 10000000
11)将商位从左到右排列得到商:100001001,余数为 10000000
运算结果:
R1R0 = R3R4 / R5 = 100001001
R2 = R3R4 % R5 = 10000000
流程图:
效率与代码量对比(数据可能有小偏差):

对于除法路径,本文给出的方式同样具备较好的综合表现。
以下为针对精简指令集的 16/8 位除法例程示意,便于移植与理解:


 发表于 2025-12-22 02:05:23
|
查看: 2457|
回复: 0
发表于 2025-12-22 02:05:23
|
查看: 2457|
回复: 0
