面试官追问“数据到底经过了几次拷贝?”,本质是考察对RocketMQ高性能核心机制的理解深度。这并非简单的数字记忆,而是需要穿透“零拷贝”在不同场景下的具体实现、设计取舍与底层原理。
面试意图拆解与高分回答策略
此类问题旨在通过一个具体的技术细节,进行分层验证,核心考察点有三:
- 是否理解“零拷贝”的本质:零拷贝并非“无拷贝”,而是最大限度地减少或消除CPU参与的数据拷贝及JVM堆内存的介入,核心目标是降低CPU开销与GC压力。
- 是否具备场景化思维:能否区分消息写入(Producer -> Broker)与消息读取(Broker -> Consumer)两个场景下,技术选型与数据路径的根本差异。
- 对底层技术的落地认知:能否讲清DMA与CPU拷贝的区别、内核态与用户态的边界,以及
mmap和sendfile等技术在RocketMQ中的具体应用逻辑。
高分回答应遵循以下结构:
破题定调:首先明确,RocketMQ的零拷贝是针对“收消息”和“发消息”两个场景,分别采用mmap和sendfile技术,以最大化减少CPU拷贝和JVM堆内存参与。
分场景拆解:这是核心得分点,需绑定技术选型与场景约束,讲清数据路径、拷贝次数及设计原因。
对比升华:点明两个场景的核心区别,体现架构设计的取舍逻辑。
延伸补充:可提及主从复制场景的零拷贝应用,展现对技术复用的全局理解。
分场景深度解析:数据拷贝路径与次数
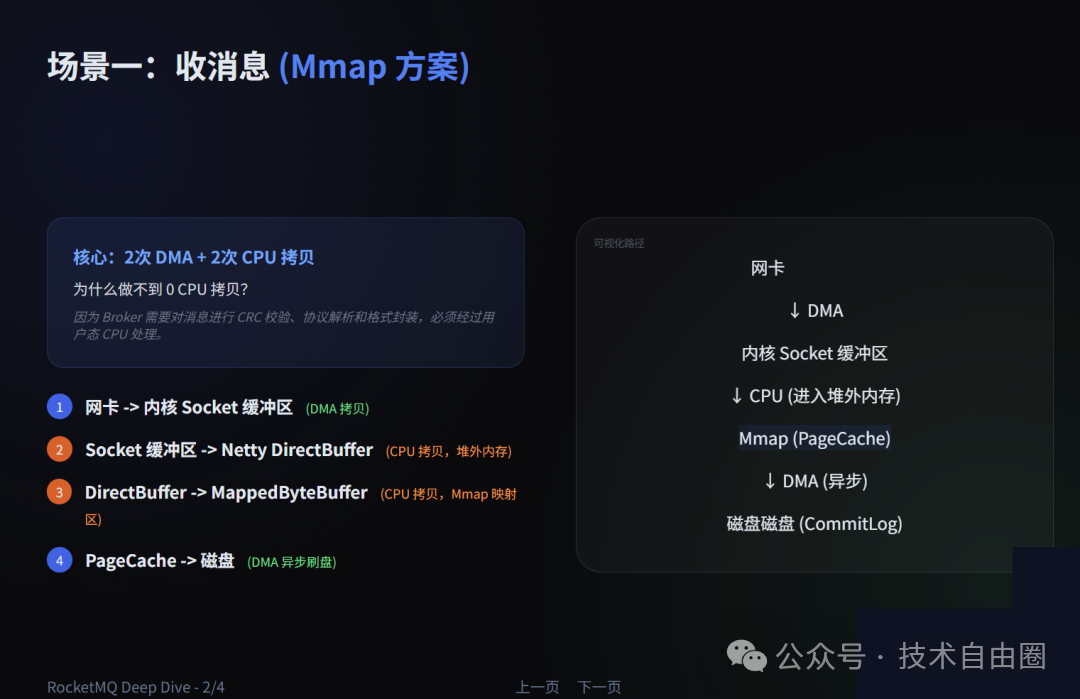
场景一:收消息(Producer -> Broker,网络到磁盘)
技术方案:Mmap + Netty DirectByteBuffer(堆外内存)
场景约束:Broker必须对消息进行CRC校验、协议解析等业务处理,无法跳过用户态。
拷贝次数:2次DMA拷贝 + 2次CPU拷贝(全程避开JVM堆)
具体数据路径:
- 网卡 → 内核Socket缓冲区(DMA拷贝,无CPU参与)。
- 内核Socket缓冲区 → Netty
DirectByteBuffer(CPU拷贝,数据进入堆外直接内存,避开JVM堆)。
- Netty
DirectByteBuffer → MappedByteBuffer(CPU拷贝,数据仍在堆外。MappedByteBuffer通过mmap直接映射到内核的PageCache)。
- PageCache → 磁盘(DMA异步刷盘,无CPU参与)。
核心优化:虽然存在2次CPU拷贝,但通过使用堆外内存(Direct Memory)和内存映射文件(Memory Mapped File),全程避开了JVM堆,彻底消除了因消息数据进入堆内而引发的频繁GC问题,这是支撑高并发写入的关键。
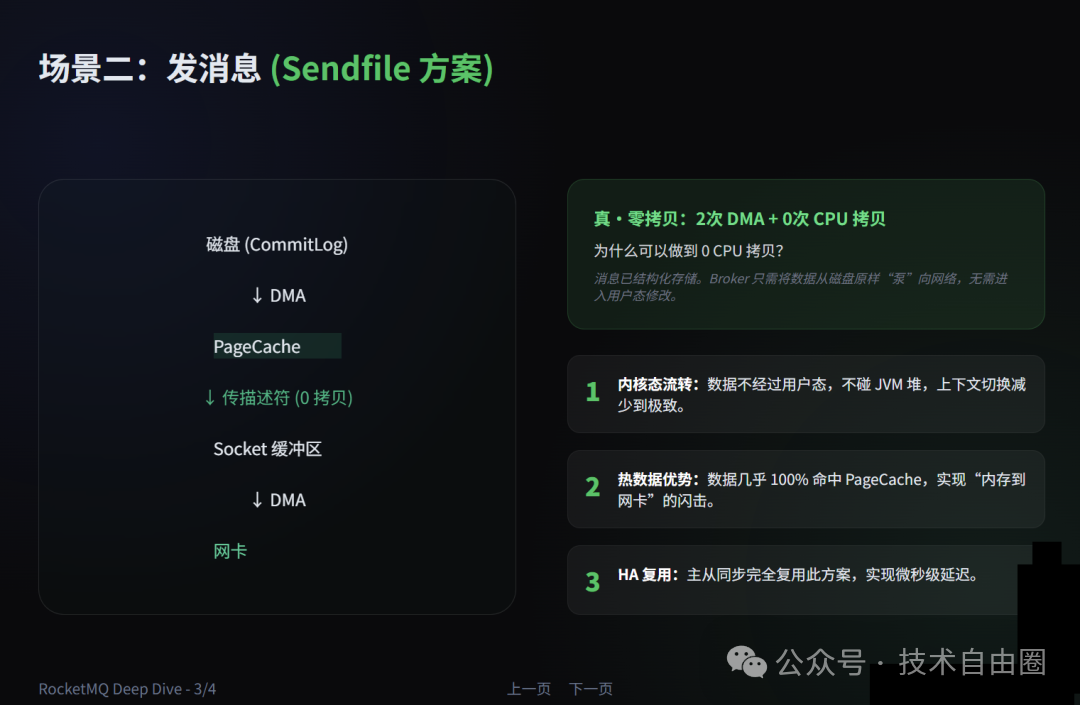
场景二:发消息(Broker -> Consumer,磁盘到网络)
技术方案:sendfile(通过Java NIO FileChannel.transferTo()调用)+ Netty FileRegion
场景约束:消息已结构化存储在CommitLog中,Broker仅需原样转发,无需修改数据。
拷贝次数:2次DMA拷贝 + 0次CPU拷贝(真正的“零CPU拷贝”)
具体数据路径:
- 磁盘 → 内核PageCache(DMA拷贝。得益于
mmap预热,消息数据极大概率已存在于PageCache中)。
- 内核通过
sendfile系统调用,将PageCache中的数据描述符(文件偏移量、长度)直接传递给Socket缓冲区(仅传递元信息,无实际数据拷贝)。
- Socket缓冲区 → 网卡(DMA拷贝,无CPU参与)。
核心优化:数据全程在内核态流转,不经过用户态,不触碰JVM堆,仅需1次系统调用,上下文切换极少,这是支撑百万级消息拉取吞吐量的基石。
核心对比与总结
| 场景 |
零拷贝技术 |
核心优化点 |
拷贝次数 (DMA/CPU) |
上下文切换 |
| Broker 收消息 |
mmap (内存映射) |
全程使用堆外内存,消除GC瓶颈 |
2次DMA + 2次CPU |
较多 |
| Broker 发消息 |
sendfile (传输) |
数据不进入用户态,零CPU拷贝 |
2次DMA + 0次CPU |
极少 |
结论:RocketMQ的高吞吐源于其场景化定制的零拷贝策略。收消息因需业务处理,无法避免CPU拷贝,但通过“避堆”设计解决了GC瓶颈;发消息因无需修改数据,利用sendfile实现了纯内核态传输,做到了真正的零CPU拷贝。两者协同,构成了端到端的高性能数据通路。
延伸:主从复制场景的零拷贝
在主从复制(HA同步)场景中,RocketMQ同样使用了FileChannel.transferTo()(底层sendfile)来实现零拷贝传输,其底层原理与给消费者发消息完全一致。
细微差异在于场景逻辑:
- 发消息给消费者:是“点对多”的随机拉取,可能涉及冷数据,性能受PageCache命中率影响。
- 主从同步:是“点对点”的持续顺序同步,数据几乎100%为刚写入PageCache的极热数据,因此效率通常更高,能实现极低的同步延迟。
这体现了RocketMQ “一套高性能引擎,多场景复用” 的架构设计思想。
从传统I/O到零拷贝的演进
理解零拷贝的优化价值,需要对比传统I/O的冗余操作。在经典的Java NIO文件网络发送流程中,需要经历:
- 磁盘 -> PageCache (DMA拷贝)
- PageCache -> 用户缓冲区(JVM堆) (CPU拷贝)
- 用户缓冲区 -> Socket缓冲区 (CPU拷贝)
- Socket缓冲区 -> 网卡 (DMA拷贝)
此过程包含4次数据拷贝(2次CPU参与)和4次上下文切换,CPU浪费严重。RocketMQ通过上述mmap和sendfile的组合,分别在收、发场景大幅减少了不必要的CPU数据搬运和上下文切换,这是其性能卓越的根本原因之一。
对于希望在分布式系统和高性能网络编程领域深入发展的开发者而言,透彻理解此类底层I/O优化机制至关重要。 |  发表于 2025-12-23 18:30:46
|
查看: 246|
回复: 0
发表于 2025-12-23 18:30:46
|
查看: 246|
回复: 0
