本文详细解析了JavaScript中的浅拷贝与深拷贝概念,包括数据类型划分、内存操作原理、常用拷贝方法及其实现。通过实例展示了两者在数组与对象上的应用差异,并指导如何根据场景选择合适的方法以避免数据引用导致的意外修改。
一、核心概念解析
1. ECMAScript 数据类型划分
理解拷贝的前提是区分数据类型:
- 简单类型(基础/原始类型):
Number、String、Boolean、Undefined、Symbol(ES6新增)。
- 引用类型(复杂/复合类型):
Object (包含 Array、Function、Date、RegExp、Map、Set 等)。
2. 程序内存模型:栈与堆
在程序运行时,数据存储在内存的不同区域:
- 栈内存:由系统自动分配释放,用于存储函数的参数值、局部变量等。访问速度快,直接存储变量的值。
- 堆内存:一般由开发者(或垃圾回收机制)管理,用于存储引用类型的数据。访问时需通过栈中存储的地址(引用)来寻址。
下图清晰地展示了变量在内存中的存储方式:
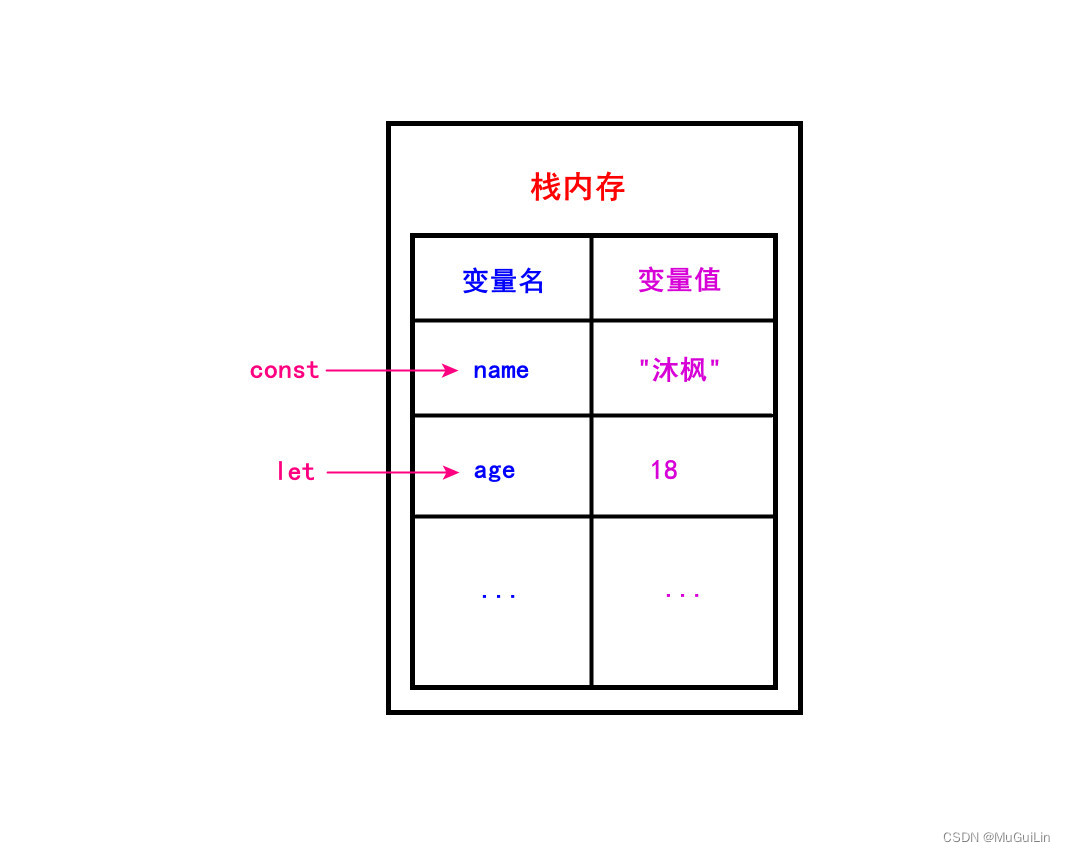
- 简单类型:值直接存储在栈内存中。
- 引用类型:真实数据存储在堆内存中,而栈内存中存储的是指向该堆内存地址的引用(指针)。
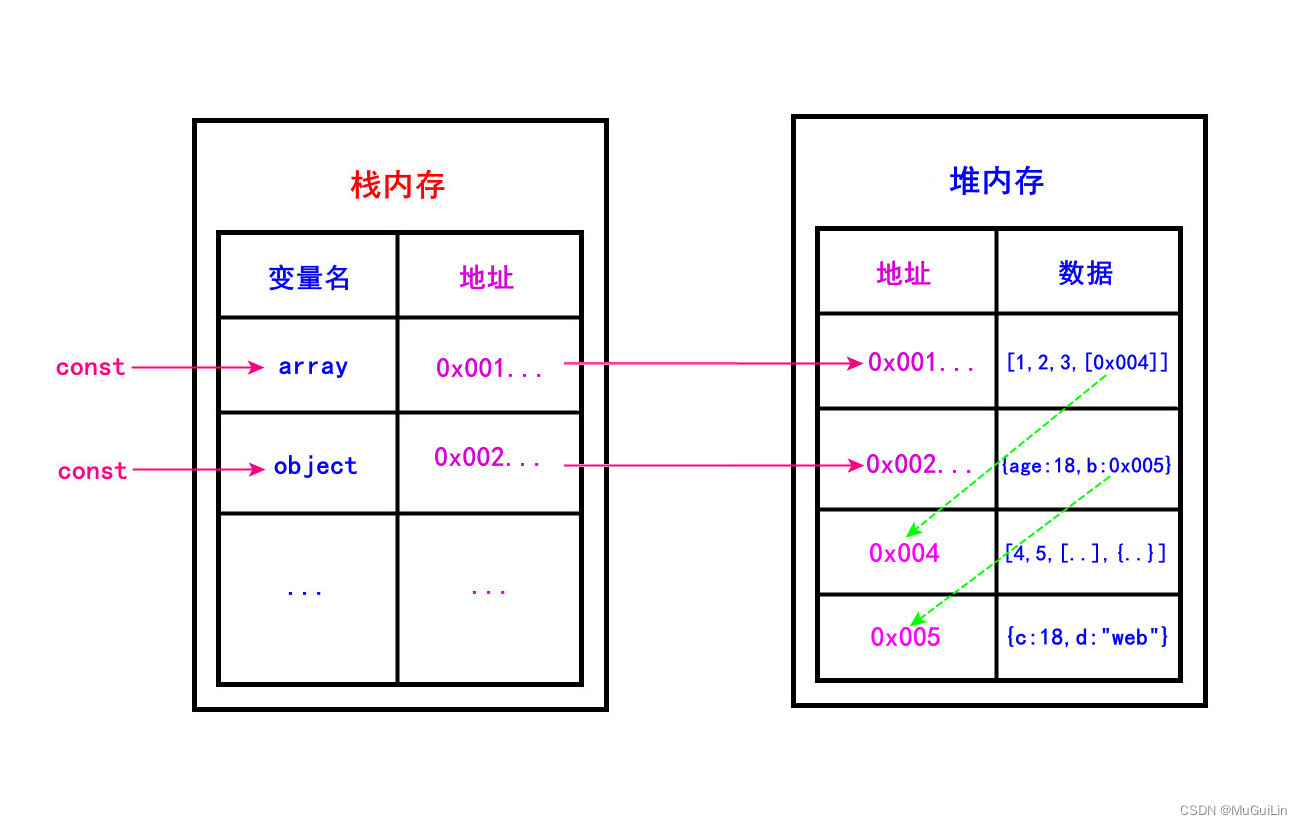
正是这种存储机制的差异,导致了“传值”与“传址”的区别,这也是理解深浅拷贝的关键。若想更深入理解数据结构中堆与栈的概念,可以延伸阅读相关资料。
3. 传值与传址
-
传值:传递的是变量所赋值的副本。修改新变量不会影响原变量。
let a = 666;
let b = a; // 传值,b获得a值的一个副本
a = 888; // 修改a
console.log(a); // 888
console.log(b); // 666 (b未受影响)
在JavaScript中,Number、String、Boolean等简单类型赋值时采用传值。
-
传址:传递的是变量在堆内存中的地址(引用)。新旧变量指向同一块内存空间,因此修改其中一个会影响另一个。
// 数组示例
let a = [1, 2, 3];
let b = a; // 传址,b和a指向同一个数组
a[0] = 100;
console.log(a); // [100, 2, 3]
console.log(b); // [100, 2, 3] (b随之改变)
// 对象示例
let objA = { name: '小明', age: 18 };
let objB = objA; // 传址
objB.name = '小强';
console.log(objA.name); // '小强' (objA随之改变)
对于 Array、Object 等引用类型,直接的赋值操作就是传址。

二、浅拷贝与深拷贝实战
拷贝操作的本质是为引用类型数据创建“副本”,根据副本的独立程度分为浅拷贝和深拷贝。
1. 浅拷贝
浅拷贝只复制对象或数组的第一层属性。如果属性值是引用类型,则拷贝的是其地址,而非实际数据,因此深层次的引用数据仍然是共享的。
实现方式一:扩展运算符 ...
// 数组浅拷贝
let arr = [1, 2, [3, 4]];
let shallowCopyArr = [...arr];
arr[0] = 100; // 修改第一层,不影响副本
arr[2][0] = 300; // 修改第二层(引用类型),副本也会被修改
console.log(shallowCopyArr); // [1, 2, [300, 4]]
// 对象浅拷贝
let obj = { name: 'Tom', info: { age: 20 } };
let shallowCopyObj = { ...obj };
obj.name = 'Jerry'; // 不影响副本
obj.info.age = 25; // 会影响副本
console.log(shallowCopyObj.info.age); // 25
实现方式二:Object.assign()
// 数组
let arr = [1, 2, [3, 4]];
let copyArr = Object.assign([], arr);
arr[2][1] = 400;
console.log(copyArr); // [1, 2, [3, 400]]
// 对象
let obj = { a: 1, b: { c: 2 } };
let copyObj = Object.assign({}, obj);
obj.b.c = 20;
console.log(copyObj.b.c); // 20
一些数组方法如 concat()、slice()、map() 等返回的新数组,也属于浅拷贝。
2. 深拷贝
深拷贝会递归复制对象的所有层级,创建一个完全独立的新对象,新旧对象之间不存在任何引用关联。
实现方式一:JSON.parse(JSON.stringify())
利用JSON的序列化和反序列化实现。
let obj = {
name: 'Alice',
hobby: ['reading', 'music'],
date: new Date(),
fn: function() {}, // 函数
sym: Symbol('foo'), // Symbol
undef: undefined // undefined
};
let deepCopy = JSON.parse(JSON.stringify(obj));
console.log(deepCopy);
// 输出:{ name: 'Alice', hobby: ['reading', 'music'], date: '2023-10-01T12:00:00.000Z' }
// 注意:函数、Symbol、undefined 丢失;Date对象变成了字符串
缺点:无法处理函数、Symbol、undefined;会丢失RegExp、Map、Set等特殊对象;不能处理循环引用(会报错)。
实现方式二:structuredClone() (现代浏览器原生API)
浏览器环境提供的全局方法,支持更多数据类型和循环引用。
let obj = {
name: 'Bob',
info: { age: 30 },
arr: [1, 2],
date: new Date(),
reg: /abc/g,
// self: obj // 支持循环引用
};
// obj.self = obj; // 解除注释测试循环引用
let cloned = structuredClone(obj);
obj.info.age = 40;
obj.arr.push(3);
console.log(cloned.info.age); // 30 (未受影响)
console.log(cloned.arr); // [1, 2] (未受影响)
console.log(cloned.date instanceof Date); // true
console.log(cloned.reg instanceof RegExp); // true
缺点:无法克隆函数、Symbol;在非常旧的浏览器中不支持。它是处理后端API返回的复杂JSON数据时的优秀选择。
实现方式三:自定义递归深拷贝函数
最灵活、最通用的方法,可以处理各种边界情况(循环引用、特殊对象等)。
function deepClone(target, hash = new WeakMap()) {
// 处理基本类型和函数
if (target === null || typeof target !== 'object') return target;
// 处理日期和正则
if (target instanceof Date) return new Date(target);
if (target instanceof RegExp) return new RegExp(target);
// 处理循环引用
if (hash.has(target)) return hash.get(target);
// 创建克隆对象或数组
const cloneObj = Array.isArray(target) ? [] : {};
hash.set(target, cloneObj); // 存储引用关系
// 递归拷贝所有属性
for (let key in target) {
if (target.hasOwnProperty(key)) {
cloneObj[key] = deepClone(target[key], hash);
}
}
return cloneObj;
}
// 测试用例
let complexObj = {
num: 1,
arr: [1, 2, { nested: 'value' }],
obj: { key: 'val' },
date: new Date(),
reg: /test/gi,
func: function() { console.log('hello'); },
// 循环引用
};
complexObj.self = complexObj;
let clonedComplexObj = deepClone(complexObj);
clonedComplexObj.arr[2].nested = 'changed';
console.log(complexObj.arr[2].nested); // 'value' (原对象未受影响)
3. 如何选择拷贝方式?
- 简单需求:如果数据是简单的JSON对象(无函数、
Symbol、循环引用),JSON.parse(JSON.stringify()) 或 structuredClone() 简单高效。
- 现代浏览器环境:优先考虑
structuredClone(),它支持更多类型且是原生API。
- 复杂场景:当需要拷贝函数、特殊对象或处理不确定的数据结构时,使用可靠的自定义递归函数或成熟的第三方库(如 Lodash 的
_.cloneDeep)。
- 性能考量:对于非常大的对象,需要考虑递归的性能和栈溢出风险,此时可能需要迭代算法或特殊优化。
三、使用场景与总结
深浅拷贝主要应用于需要操作引用类型数据副本,同时又希望保护原始数据的场景。
典型使用场景
- 状态管理:在前端框架(如Vue、React)中,直接修改状态对象是禁忌。通常需要先创建状态的深拷贝,修改副本后再替换原状态,以确保可预测的状态更新和触发响应式。
- 数据加工:从后端接收到一份原始数据,前端需要对其进行格式化、过滤或计算,同时保留原始数据用于其他用途。
- 函数参数:向函数传递一个对象参数,函数内部可能修改该对象。如果不希望影响外部对象,应先深拷贝再传入。
扩展与工具
- 第三方库:
- Lodash:提供了非常健壮的
_.clone(浅拷贝)和 _.cloneDeep(深拷贝)方法。
clone-deep 等NPM包。
- 开发实践:理解深浅拷贝是JavaScript开发者的基本功,它有助于编写出更安全、更少副作用的代码,尤其是在处理复杂数据结构与算法时尤为重要。
 发表于 2025-12-23 22:00:09
|
查看: 288|
回复: 0
发表于 2025-12-23 22:00:09
|
查看: 288|
回复: 0
