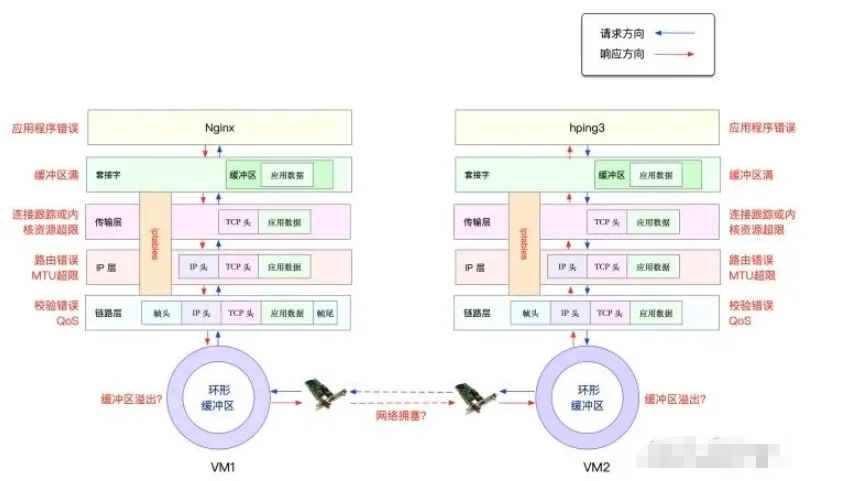
从图中可以看出,网络数据包从发送到接收的整个路径上,每一个环节都可能发生丢包。
- 在两台VM连接之间,可能因网络拥塞、线路错误等原因导致传输失败。
- 网卡收包后,环形缓冲区可能因溢出而丢包。
- 链路层可能因帧校验失败、QoS策略等而丢包。
- IP层可能因路由失败、数据包大小超过MTU等而丢包。
- 传输层可能因端口未监听、资源占用超过内核限制等而丢包,涉及复杂的TCP/IP协议交互。
- 套接字层可能因缓冲区溢出而丢包。
- 应用层可能因应用程序自身异常而丢包。
- 此外,配置了iptables规则后,数据包也可能因过滤规则被丢弃。
链路层排查
当链路层因缓冲区溢出等问题导致网卡丢包时,Linux会在网卡统计信息中记录错误。可通过ethtool或netstat -i命令查看。
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 31 0 0 0 8 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0
输出中,RX-OK、RX-ERR、RX-DRP、RX-OVR分别表示接收的总包数、总错误数、因内存不足等原因的丢包数以及环形缓冲区溢出丢包数。TX-开头的字段含义类似,对应发送方向。
本例中未发现错误,说明虚拟网卡自身无丢包。但需注意,若使用tc工具配置了QoS,其导致的丢包不会计入网卡统计。因此需检查eth0是否配置了tc规则,使用-s选项查看统计信息:
tc -s qdisc show dev eth0
qdisc netem 800d: root refcnt 2 limit 1000 loss 30%
Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
可见eth0上配置了一个网络模拟(netem)队列规则,丢包率设为30%。统计信息显示发送了8个包,丢弃了4个。这很可能是导致响应包丢失的原因。
删除此netem规则:
tc qdisc del dev eth0 root netem loss 30%
删除后重新测试,但问题依旧,丢包率仍为50%。这表明问题不在链路层,需继续向上排查网络层和传输层。
网络层与传输层排查
这两个层面引发丢包的因素众多。Linux提供了各协议的汇总统计,使用netstat -s命令查看:
netstat -s
# 输出摘要
Ip:
Forwarding: 1 // 开启转发
31 total packets received // 总收包数
0 forwarded // 转发包数
0 incoming packets discarded // 接收丢包数
25 incoming packets delivered // 接收的数据包数
15 requests sent out // 发出的数据包数
...
Tcp:
0 active connection openings // 主动连接数
0 passive connection openings // 被动连接数
11 failed connection attempts // 失败连接尝试数
0 connection resets received // 接收的连接重置数
0 connections established // 建立连接数
25 segments received // 已接收报文数
21 segments sent out // 已发送报文数
4 segments retransmitted // 重传报文数
0 bad segments received // 错误报文数
0 resets sent // 发出的连接重置数
...
TcpExt:
11 resets received for embryonic SYN_RECV sockets // 半连接重置数
0 packet headers predicted
TCPTimeouts: 7 // 超时数
TCPSynRetrans: 4 // SYN重传数
...
输出显示,TCP协议存在明显的异常:
- 11次连接失败尝试
- 4次报文重传
- 11次半连接重置(SYN_RECV状态)
- 4次SYN重传
- 7次超时
这些统计表明TCP握手阶段存在大量失败,但根本原因仍不明确,需结合其他工具进一步分析。
iptables规则排查
iptables作为Linux上强大的防火墙工具,其过滤或连接跟踪机制也可能导致丢包,是排查网络问题的关键一环,尤其需要注意其网络安全过滤规则。
首先检查连接跟踪是否已达上限:
# 查询最大连接跟踪数与当前数量
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 262144
$ sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 182
当前连接数远低于上限,可排除连接跟踪表满的原因。
接着重点检查filter表中会导致丢弃数据包的规则(如DROP、REJECT),并查看其匹配计数:
iptables -t filter -nvL
#输出
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0
输出显示,INPUT和OUTPUT链中各有一条DROP规则,且匹配包数不为零。这两条规则使用了statistic模块,对所有源IP和目的IP的数据包进行随机30%的丢包。这很可能是导致问题的另一个原因。
删除这两条规则:
root@nginx:/# iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP
root@nginx:/# iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
删除后测试,TCP握手成功,但应用层HTTP请求依然超时,问题仍未彻底解决。
深入抓包分析与MTU问题
使用tcpdump抓取80端口的数据包进行深入分析:
tcpdump -i eth0 -nn port 80
同时在另一终端发起HTTP请求。对比抓包结果发现,客户端发送的SYN包能收到SYN+ACK回复,但其后携带HTTP GET请求数据的TCP包却没有收到ACK确认,触发了重传。
此时,重新检查网卡统计信息:
netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 100 157 0 344 0 94 0 0 0 BMRU
lo 65536 0 0 0 0 0 0 0 0
发现接收丢包数(RX-DRP)高达344。对比之前测试:hping3只发送SYN包能成功,而curl发送SYN包后还会发送携带HTTP数据的TCP包。差异点在于数据包大小。
观察输出中第二列MTU值,eth0的MTU仅为100,远小于标准以太网MTU 1500。这导致稍大的数据包在接收时被丢弃。修改MTU为正确值:
ifconfig eth0 mtu 1500
修改后,再次测试HTTP请求,成功接收到Nginx的响应页面,丢包问题得到彻底解决。这提醒我们在运维/DevOps工作中,基础的网络参数配置检查至关重要。
 发表于 2025-12-24 00:08:24
|
查看: 254|
回复: 0
发表于 2025-12-24 00:08:24
|
查看: 254|
回复: 0
