Transformer解码器在各种任务中表现出色,但在处理长序列时,巨大的KV缓存带来的内存开销成为一个主要瓶颈。尽管已有的跨层KV缓存共享技术(如YOCO、CLA)为缓解此问题提供了思路,但其性能通常不如层内优化方法(如GQA)。因此,业界迫切需要一种更高效的跨层共享策略。
阿里巴巴淘天集团与中国人民大学的研究团队发现了一个关键洞察:在缓存重建过程中,键(Key)和值(Value)表现出明显的不对称特性。基于这一发现,他们提出了内存高效的FusedKV架构及其轻量级变体FusedKV-Lite。大量实验表明,该方法能将KV缓存的内存占用降低50%,同时获得比标准Transformer解码器更低的困惑度。

方法原理
在实际的大语言模型推理部署中,低延迟和高吞吐是核心要求。随着上下文长度不断增加,自回归生成过程中的键值(KV)缓存所带来的线性内存增长使得这一需求更具挑战性。
为应对此问题,研究者们提出了多种减少KV缓存的方法:
- 层内方法:如GQA和MQA,通过在多个查询头之间共享同一个键值头来减少冗余;MLA则采用低秩联合压缩技术对KV缓存进行压缩。
- 跨层方法:如CLA在相邻层间共享KV缓存,YOCO将中间层的缓存复用于上半部分层。
然而,跨层共享方法的性能往往落后于层内方法。为了突破这一局限,研究团队探索了更高效的策略。
他们将解码器的L层集合 L={1,…,L} 划分为两个子集:
- 存储层(LS):在生成过程中,其KV缓存会显式存储在内存中。
- 重建层(LR):其KV缓存不会被存储,而是通过一个重建函数
F,利用存储层的缓存按需重新计算。
对于任意重建层 i∈LR,其键K_i和值V_i由重建函数F_i生成。研究团队重点探讨了两类重建函数:
- 直接缓存复用:最简单的重建方式,直接复用源层的KV缓存,不做任何变换。
- 缓存的加权融合:将重建的KV缓存计算为多个源层缓存的加权线性组合,通过特征层面的门控机制进行有选择的重建,以增强表征能力。
核心发现:键与值的不对称性
研究团队在一个16层的1B参数模型上进行密集融合实验时,发现了一个重要现象:键缓存和值缓存的重建依赖模式存在显著差异。高层值缓存的重建严重依赖最底层的缓存(如第0-1层),而键缓存的权重则更分散,但集中在中层(如第6-7层)。这表明,底层和中间层对于重建高层缓存具有更高的信息价值。这一发现为设计更高效的共享策略提供了关键依据。想要了解更多前沿的人工智能优化技术,可以参考相关领域的进展。
FusedKV架构
基于上述发现,研究团队提出了FusedKV架构。其核心思想是:通过对最底层(第1层)与一个中间源层(第n层)的缓存进行可学习的加权融合,来重建目标层的缓存。这种方法使每个重建层能够融合底层的通用特征与中间层的抽象上下文表征,在表征能力和内存访问开销之间取得了良好平衡。加权融合操作可直接应用于经RoPE(旋转位置编码)变换后的键,避免了重新计算RoPE的额外开销。
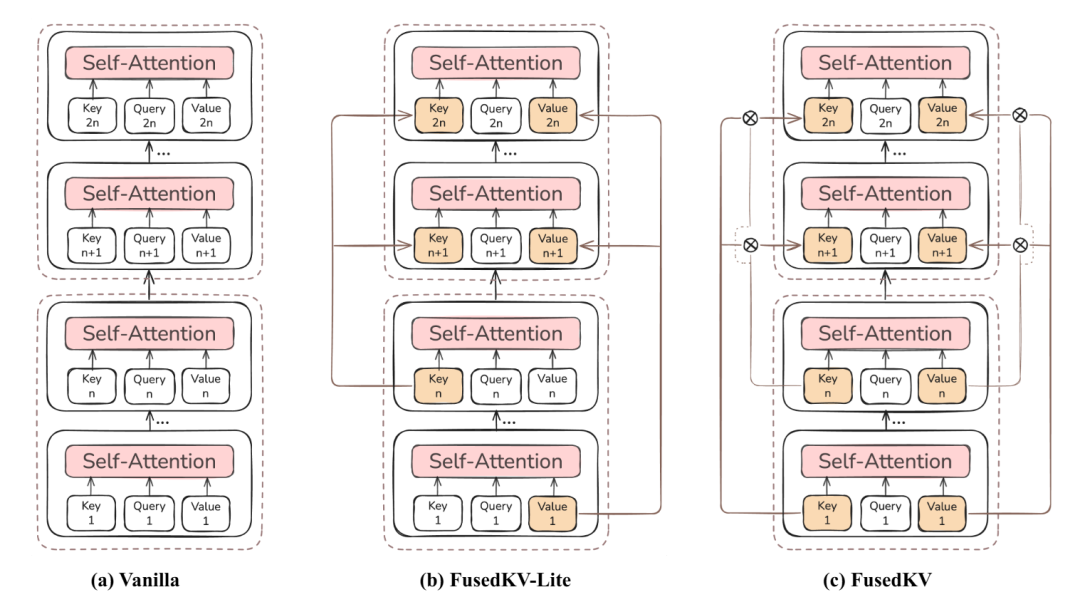
图:不同KV缓存策略示意图。(a)标准方法;(b)FusedKV-Lite;(c)FusedKV。
FusedKV-Lite:极致轻量版
为了追求极致的推理效率,研究团队进一步提出了FusedKV-Lite。它采取了更直接的策略:直接复用最后一个源层(第n层)的缓存作为键缓存,同时复用最底层(第1层)的缓存作为值缓存。这种方法完全避免了融合操作带来的额外I/O开销,使得其推理效率与标准模型相当,特别适合I/O受限的网络/系统推理场景。
性能评估
研究团队从多个维度对FusedKV和FusedKV-Lite进行了全面评估。
复杂度分析
与标准模型相比,FusedKV-Lite和FusedKV都能显著降低预填充阶段的计算量(FLOPs)和KV缓存的内存占用。FusedKV因融合计算会略微增加缓存I/O量,而FusedKV-Lite的I/O量与标准模型几乎相同。
注意力吞吐量与端到端性能
- 注意力吞吐量:FusedKV-Lite保持了与标准多头注意力(MHA)相当的吞吐量,而FusedKV由于额外的缓存I/O,吞吐量略低。
- 端到端预填充性能(TTFT):在输入序列长度达到8K及以上时,FusedKV和FusedKV-Lite能将TTFT(首Token延迟)相比标准模型降低约50%。
- 端到端解码性能(TPOT):在内存受限场景下,FusedKV的TPOT(每输出Token耗时)因I/O开销而增加;在计算受限场景下,其TPOT与基线相当。FusedKV-Lite在两种场景下的TPOT均与基线相近。
下游任务准确率
在332M、650M和1.5B参数的模型上进行测试,FusedKV与FusedKV-Lite在语言建模困惑度和下游任务(如ARC-E, MMLU, HellaSwag)的平均准确率上,均展现出优于或媲美标准基线及其他KV缓存压缩方法(如GQA, YOCO)的性能。特别是在1.5B模型上,FusedKV取得了最低的验证损失和最高的平均准确率。
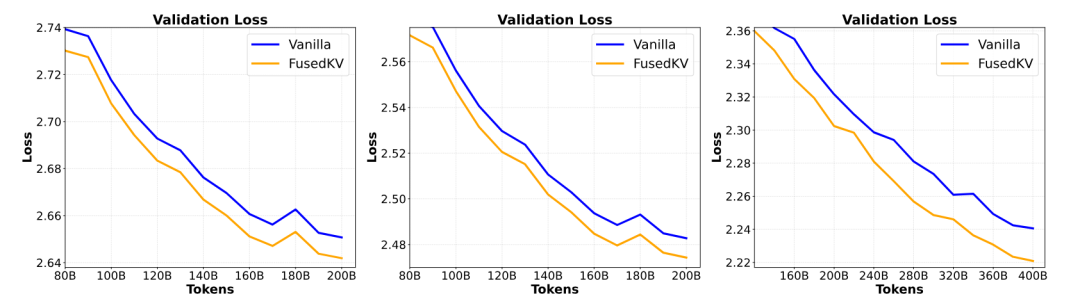
图:不同规模模型的验证损失曲线,FusedKV始终取得更低损失。
总结
FusedKV系列方法通过巧妙地利用KV缓存重建过程中的不对称性,实现了高效的跨层缓存共享。FusedKV在性能和内存节省之间取得了优异平衡,而FusedKV-Lite则为追求极致推理效率的场景提供了近乎无损的解决方案。这两种架构为大语言模型的长上下文推理部署提供了新的、有效的优化路径。
 发表于 2025-12-24 08:41:53
|
查看: 304|
回复: 0
发表于 2025-12-24 08:41:53
|
查看: 304|
回复: 0
