本文档将详细介绍在 Windows 10 操作系统下,为 NVIDIA GeForce RTX 2080 Ti GPU 配置 PyTorch 深度学习环境的完整流程。内容涵盖通过 Pip 安装 PyTorch、CUDA Toolkit 及 cuDNN 的步骤,并提供了安装后基础使用与故障排查方法。
PyTorch安装
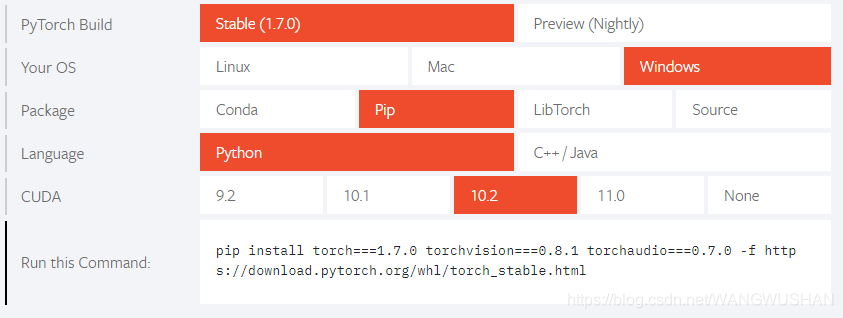
访问 PyTorch 官网,在首页根据您的系统环境选择对应的安装命令。对于 CUDA 10.1 环境,典型的安装命令如下:
pip install torch==1.7.0+cu101 torchvision==0.8.1+cu101 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
如果直接安装高版本(如 torch==2.x.0+cu118)时出现语法错误,可以尝试通过指定官方索引链接的方式安装:
pip install torch==2.4.1+cu118 --index-url https://download.pytorch.org/whl/cu118
这种方式会自动解析并安装兼容的 torchvision 等依赖。建议在 Conda 等虚拟环境中操作,新的 CUDA 环境将仅在该虚拟环境中生效,避免影响系统全局配置。熟练使用 Python 环境管理工具是高效开发的基础。
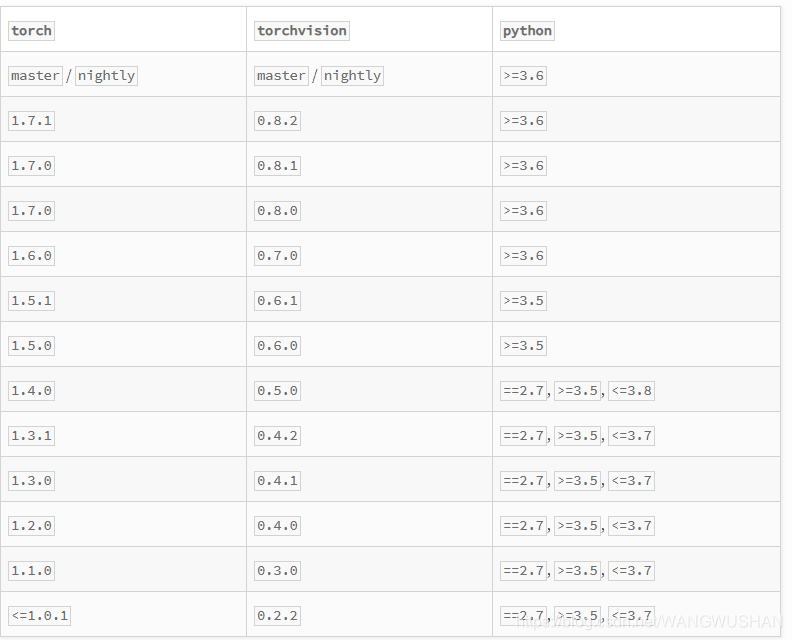
torchvision与PyTorch版本对应关系
torch 和 torchvision 版本需要严格匹配,具体对应关系可查阅 PyPI 上的 torchvision 页面。
下载对应版本的Wheel文件安装
您也可以直接从 PyTorch Wheel 文件存档 下载对应版本的 .whl 文件,然后通过 cd 命令进入下载目录进行本地安装。
CUDA安装
此处的 CUDA 安装指的是 CUDA Toolkit(运行时版本)的安装。您需要根据显卡驱动版本选择兼容的 CUDA 版本。
- 确定版本:可先通过
nvidia-smi 命令查看驱动版本,再到 NVIDIA 官网查询对应的 CUDA Toolkit 支持版本。
- 下载安装:前往 NVIDIA CUDA Toolkit Archive 下载对应版本的安装程序(例如 CUDA 10.1)。
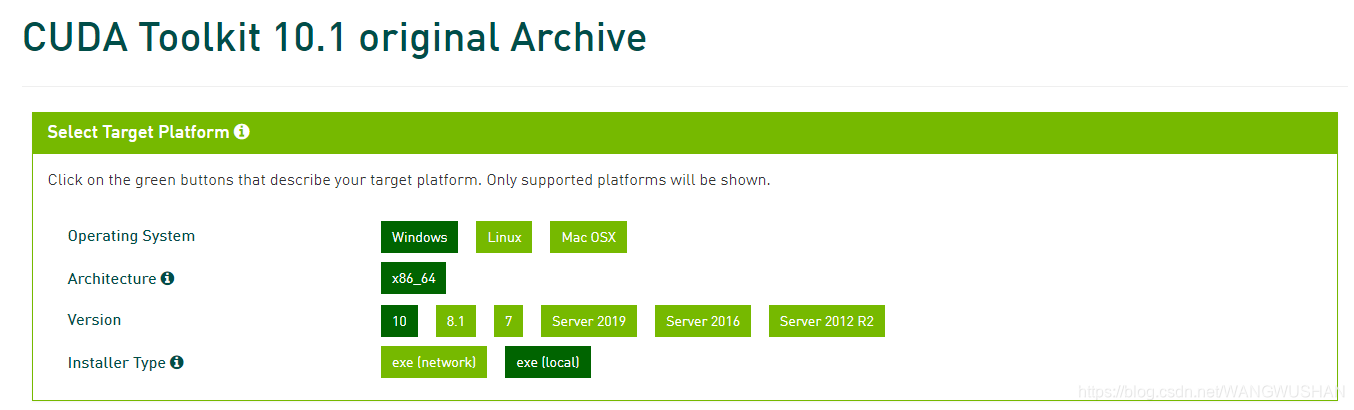
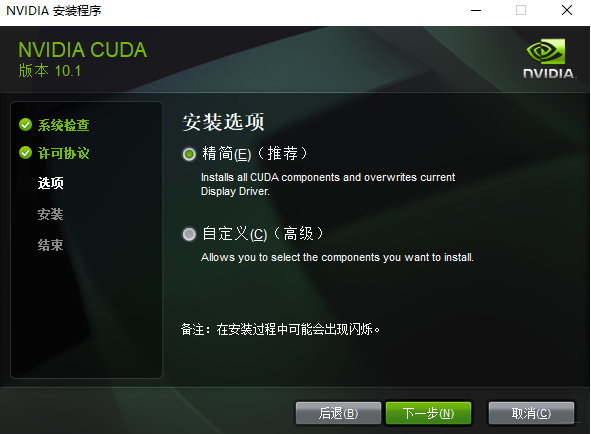
- 执行安装:运行下载的安装程序,选择“精简”安装模式即可。
重要概念区分:
- CUDA Driver 版本:由显卡驱动提供,通过
nvidia-smi 命令查看。
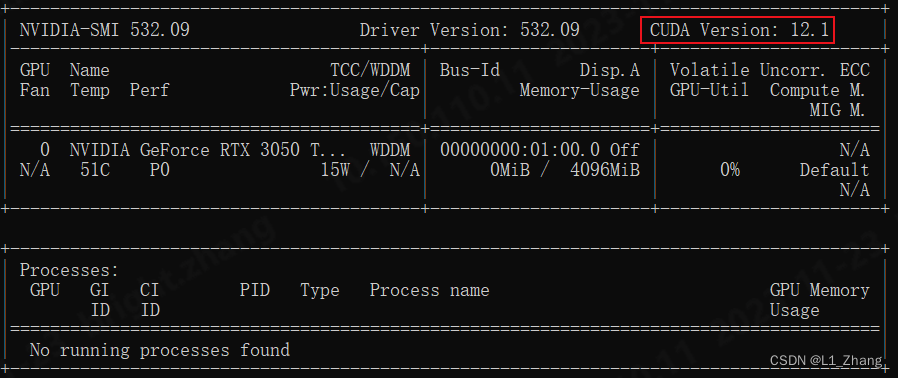
- CUDA Runtime 版本:由 CUDA Toolkit 安装,通过
nvcc --version 命令查看。

两者版本可以不同,但 Runtime 版本不能高于 Driver 版本所支持的最高版本。理解 系统与网络 底层驱动与运行时库的关系有助于排查复杂环境问题。
cuDNN安装
cuDNN 是 NVIDIA 提供的深度神经网络加速库。
- 下载:访问 NVIDIA cuDNN 下载页面(需注册登录),选择与您安装的 CUDA 版本对应的 cuDNN 版本进行下载。
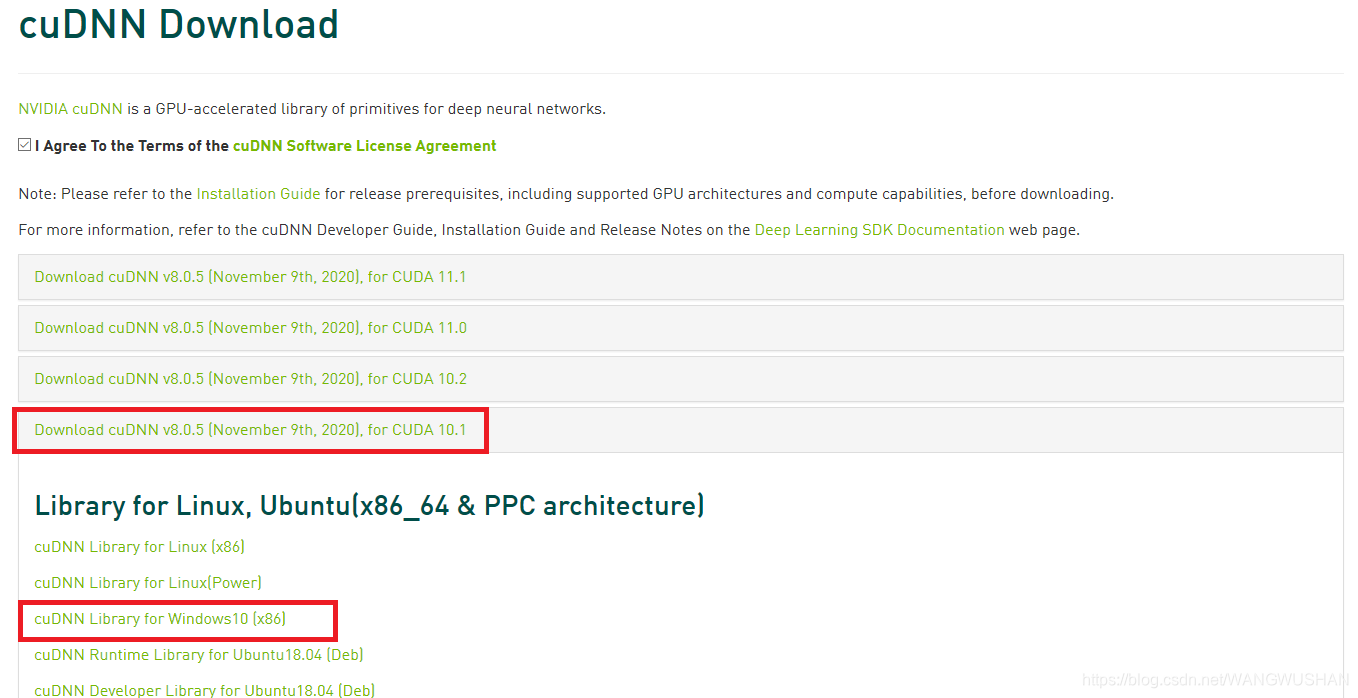
- 安装:将下载的压缩包解压,将其中的
bin、include、lib 文件夹内的内容,分别复制到 CUDA 的安装目录(默认为 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1)的对应文件夹中。
安装过程中可能遇到的bug
ImportError: numpy.core.multiarray failed to import
安装完成后,在 Python 中执行 import torch 若出现此错误,通常是由于 NumPy 版本过高或与当前 PyTorch 版本不兼容所致。
解决方案:卸载当前 NumPy,安装一个兼容的较低版本,例如:
pip uninstall numpy
pip install numpy==1.15.0
基本使用
环境配置完成后,可以进行以下基本操作验证和利用 GPU 资源。
信息获取
import torch
# 查看CUDA版本
print(torch.version.cuda)
# 查看可用GPU数量
print(torch.cuda.device_count())
# 检查CUDA是否可用
print(torch.cuda.is_available())
查找并使用显存最大的GPU
以下脚本可以自动选择当前剩余显存最多的 GPU 作为运行设备。
import os
import numpy as np
# 获取每个GPU的剩余显存
os.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp')
memory_gpu = [int(x.split()[2]) for x in open('tmp', 'r').readlines()]
# 设置可见GPU为剩余显存最大的那个
os.environ['CUDA_VISIBLE_DEVICES'] = str(np.argmax(memory_gpu))
# 也可使用 torch.cuda.set_device(np.argmax(memory_gpu))
os.system('rm tmp') # 删除临时文件
执行代码时指定GPU卡
如果系统有多张 GPU,可以在代码开头指定使用的 GPU 编号(如使用第 0 和第 1 号 GPU)。
import os
# 此设置需在 import torch 之前执行
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
import torch
清理僵尸进程
当 GPU 已不再进行计算,但显存仍被占用时,可能是由僵尸进程导致。可以按以下步骤清理:
- 查询占用 GPU 的进程:
fuser -v /dev/nvidia*
- 强制结束指定进程(将
1793 替换为实际进程号):
kill -9 1793
- 一键清理所有占用 GPU 0 的进程:
sudo fuser -v /dev/nvidia0 | awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh
参考文献
- PyTorch GitHub: https://github.com/pytorch/pytorch
- torchvision PyPI: https://pypi.org/project/torchvision/
- PyTorch Wheel Index: https://download.pytorch.org/whl/torch_stable.html
- NVIDIA CUDA Toolkit Archive: https://developer.nvidia.com/cuda-toolkit-archive
 发表于 2025-12-24 09:01:14
|
查看: 249|
回复: 0
发表于 2025-12-24 09:01:14
|
查看: 249|
回复: 0
