如果说通用大语言模型是AI时代的“入场券”,那么企业的独特竞争力,则必须构建在“企业专属数据+模型”深度融合的自主智能系统之上。
这样一个系统的效能,高度依赖于「模型的创新潜力」与「数据的利用效率」。这要求新一代的数据基础设施,不仅能支撑图像、文本、音视频等多模态数据的智能化处理,更能形成一个反馈闭环,持续驱动模型与业务协同进化。可以说,数据基建已成为企业能否真正驾驭AI、释放模型商业价值的关键前提。
为此,火山引擎在其FORCE大会“Data+AI”论坛上,正式发布了《AI时代企业数据基建升级路线图》。该路线图首次为企业勾勒出一条从“传统数据处理”到“拥有模型能力”,最终迈向“驾驭业务智能”的清晰演进路径,系统性地解答了如何通过升级数据基建设施,实现这一根本性跨越。
以“赋能模型”为核心的数据基建新范式
新兴的AI业务催生出对数据的新需求。无论是AIGC应用的实时内容生成,还是智能体(Agent)对用户意图的精准识别,都依赖于模型能够即时理解上下文数据,并做出高效、准确的响应。
例如,在游戏场景中,它体现为玩家与NPC的实时、动态交互;在智能驾驶领域,是系统对“Corner Case”(长尾场景)的自动挖掘与应对;在传媒行业,则是图文、视频素材能被智能检索、取用与二次创作。这些创新能力的实现,无一不依赖于模型对海量、多模态数据的极速“消费”与理解。
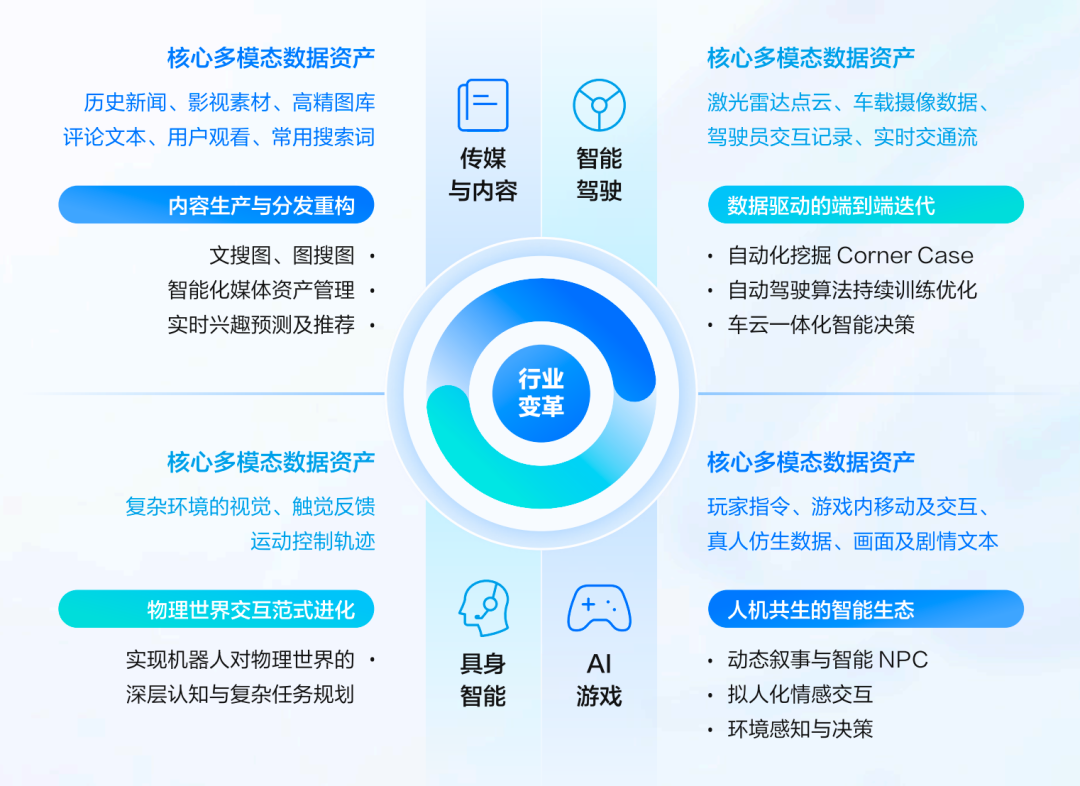
模型的能力深深根植于其底层的数据基座。模型能达到的高度,既取决于处理多模态数据时的“质”(准确度、深度),也取决于数据反馈闭环的“效”(价值)与“时”(实时性)。
当多模态数据流动的速率成为智能应用的“脉搏”,数据基建的角色就已超越传统的“数据仓库”或“数据湖”,升级为以模型为中心、以Token为价值计量单位的智能底座。它通过打通从数据接入、处理、标注到模型训练、推理、评估的全链路价值循环,从而为各类Agent及AI原生应用提供坚实支撑。因此,数据基建本身就是AI时代一项以 “赋能大模型” 为核心的关键战略投资。
AI时代企业数据基建升级的三阶段路线图
在火山引擎发布的这份路线图中,系统性提出了企业数据基建面向AI时代的升级路径,旨在为企业提供分阶段、可落地的全景参考。
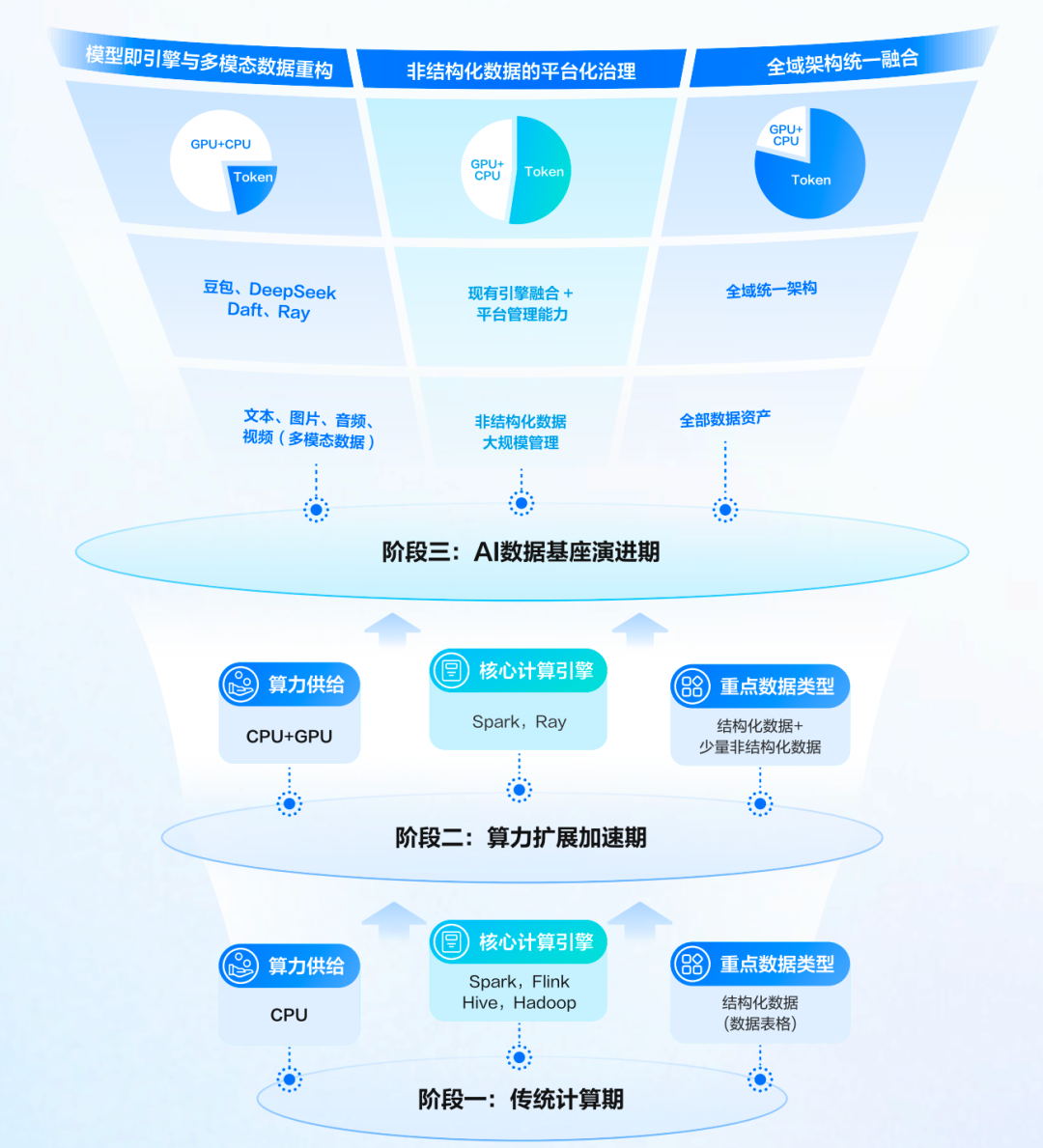
这场升级并非一蹴而就,它将从资源、引擎到平台层,经历一场从“底层算力”、“中层框架”到“顶层治理”的渐进式迭代。
第一阶段:异构算力引入与分布式引擎扩展
本阶段是企业算力架构的奠基期,核心任务在于对传统单一的CPU算力模式进行异构化重构,以化解供给瓶颈,为持续增长的AI计算与大数据处理负载构建弹性、可扩展的底层基座。
面对数据规模的指数级增长,本阶段的技术演进采取 “双轨并行”的核心策略,以兼顾稳定与创新。一方面,持续强化基于CPU的传统大数据处理生态(如Spark, Flink, Hive),保障海量结构化数据处理与存量业务的稳定可靠;另一方面,积极引入面向CPU+GPU异构算力的新一代分布式框架(如Daft、Ray),突破纯CPU的算力瓶颈,以原生支持AI训练、推理等计算密集型任务。
该阶段的目标在于化解核心算力矛盾:通过构建弹性灵活的算力资源池,同时承载AI的高性能计算与数据的高吞吐处理,为企业智能化转型奠定统一的算力基石。
第二阶段:“模型即引擎”与多模态数据重构
随着大语言模型(LLM)及视觉语言模型(VLM)能力的日益成熟,数据处理的核心范式,开始从传统的“基于逻辑规则”驱动向“基于模型语义”驱动迁移。
本阶段的关键在于构建面向多模态数据的原生处理能力。这不仅意味着处理对象从表格扩展到音、视频、文本,更代表着处理方式从确定性规则驱动转变为概率性语义驱动。“模型即引擎”逐渐成为新一代数据处理的通用架构方向。
这一概念极大地拓展了传统ETL的定义边界,它将预训练模型本身视为核心处理引擎。借助模型卓越的语义理解与生成能力,企业可以直接对非结构化数据进行深度解析、信息提取和格式转换,从而替代基于复杂正则表达式或手工规则的传统方式,显著提升数据处理的泛化能力与准确性。
此阶段还将引入Token作为核心的资源计量与调度单位,构建“Token + GPU + CPU”的联合算力评估与供给体系。同时,计算范式开始向推理式计算演进,深度聚焦并挖掘模型的理解与推理价值。
第三阶段:全域数据资产治理与平台融合
面对非结构化数据的指数级增长,企业数据基础设施的建设重心,开始从早期的“算力堆叠”转向深度的“平台化治理”与“架构融合”。
本阶段的核心目标,是构建企业级、专用化的非结构化数据资产治理体系,以支撑海量模型训练数据、评测数据集的高效存储、智能检索与安全管理。技术实践上将致力于构建AI领域的“数据飞轮”,即建立起“数据准备 -> 模型训练 -> 模型推理 -> 数据反馈”的自动化质量闭环,并配套完善AI资产(如模型、数据集、Prompt)的安全与全生命周期管理机制。
其终极价值在于,弥合传统结构化数据平台与新兴AI非结构化数据平台之间的割裂,通过统一的云原生数据架构,驱动两类数据的深度协同与价值复用。
总而言之,AI时代的企业数据基建升级,并非单一计算组件的能力提升,而是一场涵盖异构算力、智能引擎、统一平台和全局治理的系统性工程。
结语:从“拥有数据”迈向“驾驭智能”
企业数据基建的核心目标,正在发生根本性转变:从追求“拥有多少信息”转向追求“驾驭多少智能”。火山引擎发布的《AI时代企业数据基建升级路线图》,正是为这一历史性跨越绘制的系统蓝图。它不仅帮助企业明确自身所处的阶段与下一阶段的升级路径,更旨在从基础设施层面,根本性释放AI原生应用与智能体(Agent)的潜能上限。
我们相信,真正的业务智能,始于数据的自由流动,成于模型的持续生长。而这一切进化与创新的源动力,都已深植于现代化、面向未来的数据基础设施的基因之中。
 发表于 2025-12-24 15:51:42
|
查看: 268|
回复: 0
发表于 2025-12-24 15:51:42
|
查看: 268|
回复: 0
