Crawl4AI是一个开源的网页爬虫和内容刮取器,其核心目标是将杂乱的网页内容转换为干净、结构化的Markdown格式,以便直接输入给大语言模型(LLM)。它支持动态内容渲染、媒体提取、结构化数据抽取,并具备智能噪音过滤能力。
核心功能
- 生成带引用和格式的干净Markdown
- 支持基于CSS/XPath或LLM驱动的结构化提取
- 处理JavaScript动态页面、懒加载和无限滚动
- 浏览器池管理、代理支持和隐身模式
- 提供Docker部署与API服务
适用人群:Python开发者、AI工程师、构建RAG系统或AI代理的团队,以及需要自托管数据管道的企业。如果你正在使用LangChain、LlamaIndex或开发自定义AI应用,Crawl4AI将是一个高效的辅助工具。
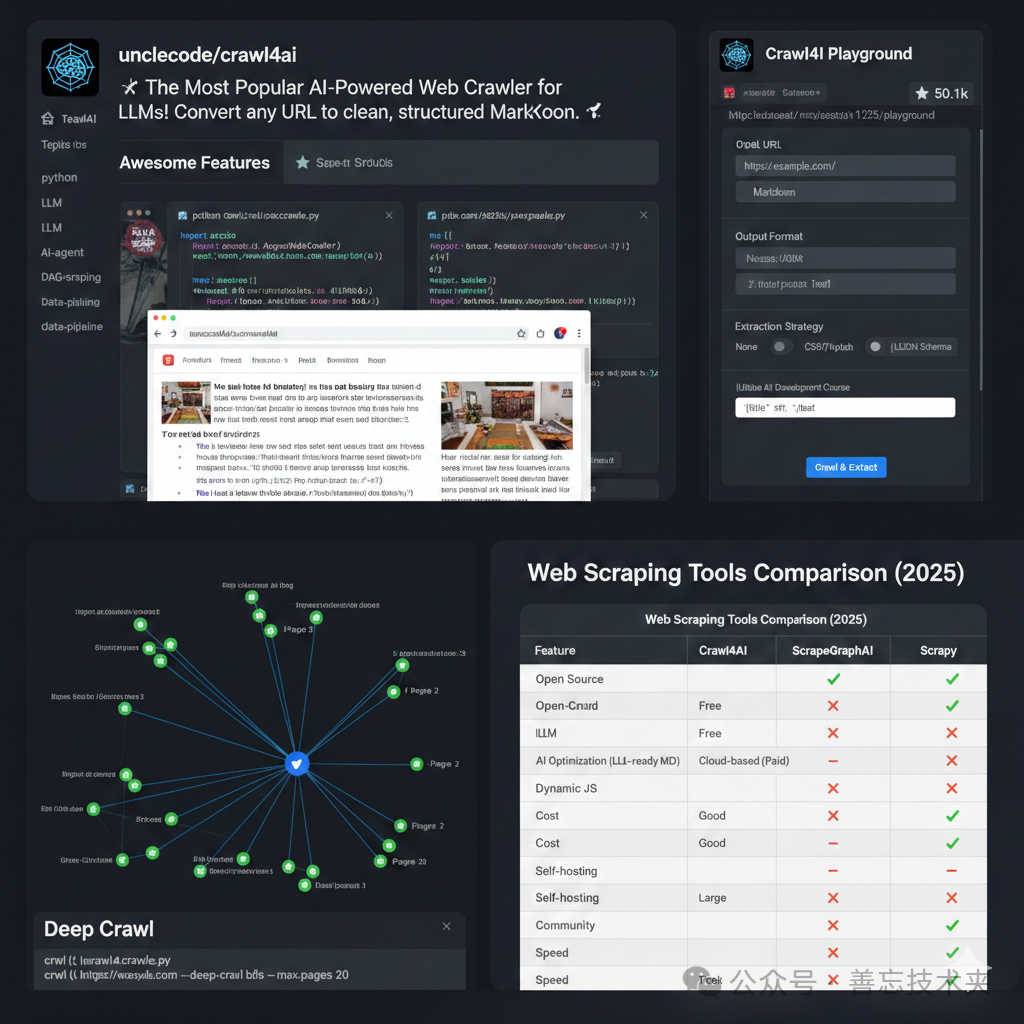
使用方法
上手过程简单快捷,几分钟内即可运行。
安装步骤(推荐异步版本):
- 使用pip安装:
pip install -U crawl4ai
- 运行设置命令:
crawl4ai-setup(自动安装Playwright浏览器)
- 检查安装状态:
crawl4ai-doctor
如需使用Docker部署:
docker pull unclecode/crawl4ai:latest
docker run -d -p 11235:11235 --shm-size=1g unclecode/crawl4ai:latest
部署后,可通过 http://localhost:11235/playground 进行测试。
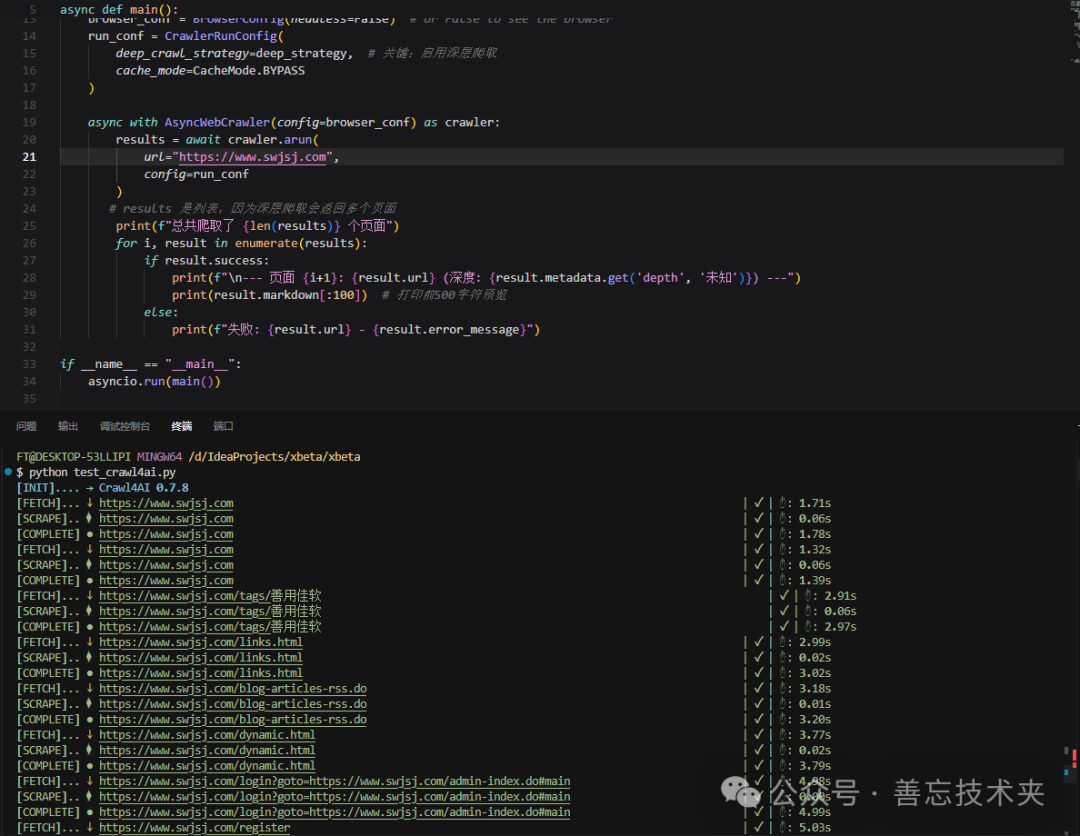
基础使用示例:
抓取网页并输出Markdown:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.swjsj.com")
print(result.markdown) # 直接获取干净Markdown
asyncio.run(main())
进行结构化提取,可使用LLM或CSS策略:
from crawl4ai import LLMExtractionStrategy
strategy = LLMExtractionStrategy(schema={"title": "str", "price": "float"})
result = await crawler.arun(url="https://www.swjsj.com", extraction_strategy=strategy)
print(result.extracted_content) # 输出JSON格式数据
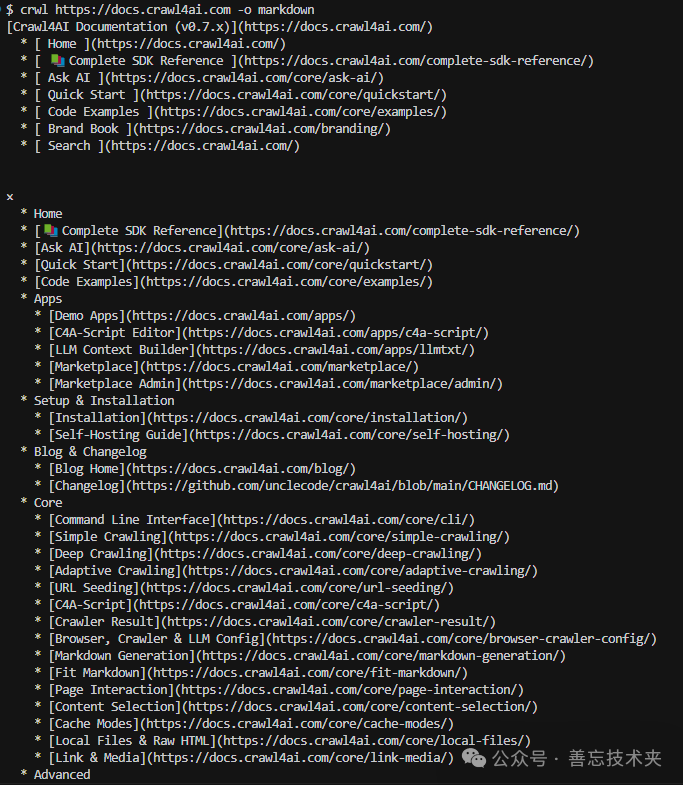
命令行工具同样支持:crwl https://docs.crawl4ai.com -o markdown
优势亮点
与传统工具如BeautifulSoup、Selenium或Scrapy相比,Crawl4AI的主要优势包括:
- 完全开源免费:无需API密钥或订阅,自托管零成本
- AI优化输出:专为LLM设计,支持语义引用、智能分块和基于BM25算法的噪音过滤
- 异步高性能:利用浏览器池和Playwright,实现高效的批量爬取
- 灵活控制:提供自定义钩子、会话持久化、代理与隐身模式,以及反爬虫规避
- 生产就绪:集成Docker、FastAPI和监控仪表盘,适合大规模部署
- 活跃社区:GitHub上星标数领先,文档齐全且更新频繁
简而言之,Crawl4AI不仅是一个爬虫工具,更是AI数据预处理的高效“清洗机”。
扩展推荐
同类工具对比:
- Firecrawl:提供云服务,简单但收费;Crawl4AI在免费和自控方面更具优势
- ScrapeGraphAI:支持自然语言驱动,适合快速原型开发;但稳定性和效率不及Crawl4AI
- Scrapy:老牌爬虫框架,适合超大规模抓取;但缺乏内置的AI优化功能,需自行处理Markdown转换
效率提升技巧:
- 使用深度爬取模式批量抓取站点:
crwl https://example.com --deep-crawl bfs --max-pages 20
- 结合本地LLM(如Ollama)进行零成本的结构化提取
- 启用缓存避免重复爬取:设置
CacheMode.ENABLED
- 针对复杂页面添加JavaScript钩子:例如自定义点击“加载更多”按钮
更多高级用法,请参考官方文档:https://docs.crawl4ai.com
|  发表于 2025-12-24 16:57:05
|
查看: 202|
回复: 0
发表于 2025-12-24 16:57:05
|
查看: 202|
回复: 0
