在复杂的分布式系统中,如何保证核心数据库操作与异步消息发送之间的一致性,是一个经典且棘手的架构问题。一个典型的场景是:用户支付成功后,需要同步更新订单状态(写入MySQL),并异步通知积分系统增加用户积分(发送MQ消息)。若处理不当,极易出现数据不一致的情况。
本文将深入探讨如何使用RocketMQ事务消息来实现这一场景下的最终一致性,并提供一个能应对生产环境复杂性的闭环解决方案。
一、 概念澄清:追求最终一致性,而非强一致性
面对此类问题,首先需要明确一点:在分布式、高并发的业务场景(如支付)中,追求跨数据库与消息队列的“强一致性”(ACID中的C)通常是不切实际的,它会严重牺牲系统的可用性和性能。
正确的架构思路是采用 最终一致性(Eventual Consistency) ,这是BASE理论的核心。它允许系统在短时间内处于不一致状态,但通过一系列补偿和保障机制,确保数据最终达成一致。RocketMQ提供的事务消息机制,正是实现最终一致性的重要工具。
二、 核心挑战与架构演进:为何需要本地事务表?
1. 基础方案的缺陷与“回查死局”
一个常见的误区是,在RocketMQ的回查逻辑(checkLocalTransaction)中直接查询业务表(如订单表)来判断本地事务状态。这种方案在并发或数据库压力下存在严重缺陷。
竞态条件(Race Condition)场景模拟:
- 生产者发送半消息(Half Message)成功。
- 执行本地事务(如插入订单),但数据库发生锁竞争,事务阻塞数秒未提交。
- MQ Broker发起事务回查。
- 回查逻辑查询订单表,由于事务未提交,查不到数据。
- 误判为事务失败,返回
ROLLBACK指令,MQ丢弃该消息。
- 下一秒,本地事务提交成功,订单数据落库。
结果:订单创建成功,但对应的积分消息已丢失,数据永久不一致。
2. 优化方案:引入事务日志表与状态机
为了解决上述“执行中”与“失败”的状态歧义问题,必须引入一张独立的事务日志表(t_transaction_log),其核心是与业务操作在同一个数据库事务中完成写入。同时,回查逻辑需要结合时间窗口进行更精细的状态判断。
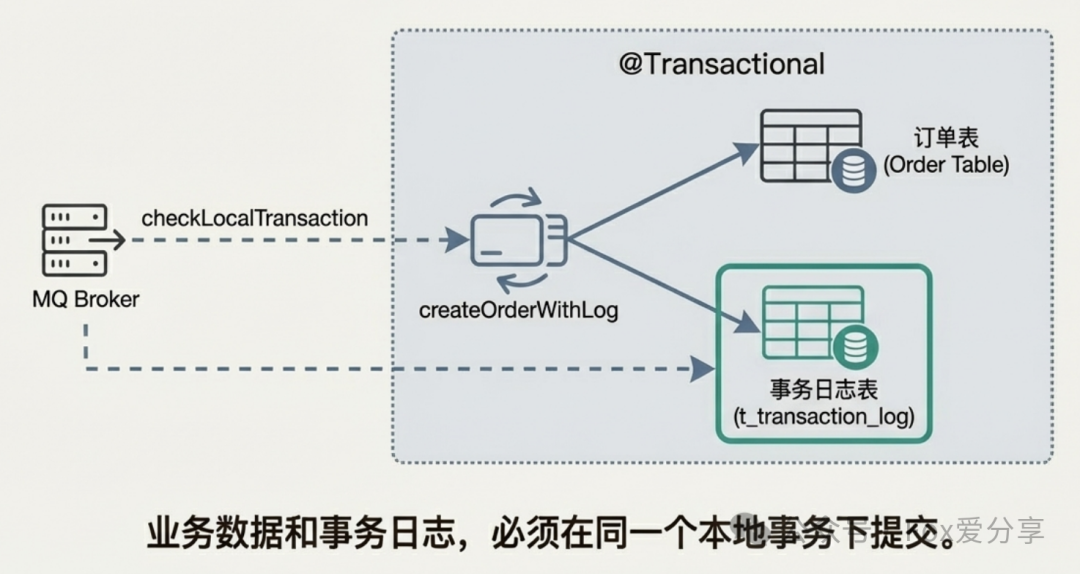
这张表记录了本地事务与MQ消息的关联关系,其写入与业务表更新具有原子性,从而为可靠的回查提供了依据。
三、 生产级代码实现:构建防悬挂与原子幂等的闭环
1. 生产者端:防误杀与防悬挂
以下代码展示了如何利用事务日志表和超时机制来优化回查逻辑。
@Component
@RocketMQTransactionListener
public class OrderTransactionListener implements RocketMQLocalTransactionListener {
@Autowired
private OrderService orderService;
@Autowired
private TransactionLogMapper logMapper;
/**
* 执行本地事务
* 核心:业务操作(如写订单表)与记录事务日志必须在同一个@Transactional中完成。
*/
@Override
public RocketMQLocalTransactionState executeLocalTransaction(Message msg, Object arg) {
try {
// 此方法内部包含在一个事务中,同时写入订单表和事务日志表
orderService.createOrderWithLog((OrderParam) arg);
return RocketMQLocalTransactionState.COMMIT;
} catch (Exception e) {
return RocketMQLocalTransactionState.ROLLBACK;
}
}
/**
* 事务回查:解决竞态条件下的误判问题
*/
@Override
public RocketMQLocalTransactionState checkLocalTransaction(Message msg) {
String orderId = msg.getHeaders().get(“orderId”).toString();
// 1. 优先查询事务日志表
int count = logMapper.countByBizId(orderId);
if (count > 0) {
return RocketMQLocalTransactionState.COMMIT; // 日志存在,说明事务已提交
}
// 2. 【关键补丁】处理“执行中”状态
// 未查到日志,可能是事务尚未提交(阻塞中)。不能立即判定失败。
// 引入超时机制:仅当消息产生时间超过阈值(如5分钟),才判定为真正的失败。
long bornTime = Long.parseLong(msg.getProperty(“BORN_TIMESTAMP”));
if (System.currentTimeMillis() - bornTime < 5 * 60 * 1000) {
// 返回UNKNOWN,告知Broker稍后重试回查
return RocketMQLocalTransactionState.UNKNOWN;
}
// 超时后仍无日志,判定为失败
return RocketMQLocalTransactionState.ROLLBACK;
}
}
2. 消费者端:实现原子性幂等消费
消费者端的陷阱在于幂等性判断与业务执行可能不在一个事务中。以下方案利用数据库唯一约束和事务确保原子性。
@Service
@RocketMQMessageListener(topic = “topic_order”, consumerGroup = “group_points”)
public class PointsConsumer implements RocketMQListener<String> {
@Autowired
private PointsService pointsService;
@Autowired
private IdempotentMapper idempotentMapper;
@Override
@Transactional(rollbackFor = Exception.class) // 关键:开启事务
public void onMessage(String message) {
OrderMsg msg = JSON.parseObject(message, OrderMsg.class);
// 1. 幂等性前置检查:利用数据库唯一索引
// 表结构:idempotent_key (varchar, unique)
try {
idempotentMapper.insertBarrier(msg.getOrderId()); // 插入防重记录
} catch (DuplicateKeyException e) {
// 唯一键冲突,说明已消费,直接返回
return;
}
// 2. 执行业务逻辑(如增加积分)
// 如果此处发生异常,事务将回滚,上一步插入的防重记录也会被撤销。
// 从而保证消息在重试时能够再次通过幂等检查并执行业务。
pointsService.addPoints(msg.getUserId(), msg.getPoints());
}
}
四、 进阶架构考量与运维方案
1. 事务日志表的治理策略
事务日志表会持续增长,需有对应的数据治理策略。
- 专家方案:使用MySQL分区表功能,按时间(如天)分区。清理历史数据时,直接
DROP PARTITION,操作高效且避免了大表删除导致的锁表问题。
- 冷热分离:通过定时任务将超过一定时间(如3天)的日志数据归档至大数据平台(如Hive)供审计查询,线上库仅保留近期热数据。
2. 死信队列(DLQ)的自动化处理
消息消费多次失败进入死信队列后,人工处理效率低下。
- 平台化思维:构建死信消息重投平台。当消息进入DLQ时自动告警,运维人员可在平台界面筛选消息,进行批量重投或修复参数后重投,极大提升处理效率。
- 最终兜底:对于平台重投仍无法处理的消息,才启动人工介入数据库修复流程。
3. 技术选型对比:本地消息表方案
除了依赖特定中间件的事务消息,还有一种经典的通用的解决方案——本地消息表。
- 原理:将待发送的消息与业务数据保存在同一个数据库中,利用本地事务保证一致性。通过独立的定时任务轮询消息表,将消息投递给消息中间件(如Kafka)。
- 对比:
- RocketMQ事务消息:实时性高,对业务代码侵入较少,但依赖于特定MQ的实现。
- 本地消息表:方案通用,与MQ解耦,但需要额外的轮询组件,存在一定延迟,并增加了数据库的压力。
架构没有银弹,需要根据业务的实时性要求、技术栈统一性等具体场景进行选择。
五、 总结
保障数据库与消息队列间的数据一致性,是分布式系统设计的核心挑战之一。RocketMQ事务消息是一个强大的工具,但并非“开箱即用”的完美解决方案。一个健壮的架构需要具备闭环思维:
- 明确定位:在分布式场景下,首要目标是实现最终一致性。
- 设计严谨:通过事务日志表和结合超时机制的状态回查,解决生产端的竞态条件问题。
- 消费可靠:在消费端利用数据库事务与唯一约束,实现原子性的幂等消费。
- 运维兜底:为系统的不确定性设计后路,建立监控告警、死信处理平台等运维保障机制。
掌握从原理到生产实践的全链路思考,才能从容应对高标准的架构挑战。
 发表于 2025-12-24 20:51:59
|
查看: 212|
回复: 0
发表于 2025-12-24 20:51:59
|
查看: 212|
回复: 0
