
我所在团队负责的服务端应用D历史悠久,其代码库最早可追溯至淘宝APP无线端迁移。随着业务迭代,应用中积存了大量已无线上流量的代码。这些“腐朽代码”不仅增加了新人的学习成本,也提升了日常开发和维护的复杂度。然而,仅凭业务经验清理代码费时费力,且极易误删仍在使用的业务逻辑。因此,我们迫切需要一种工具来辅助进行精准、高效的代码下线,这正是基于代码执行染色和覆盖率分析方案诞生的背景。
该方案的核心是:利用 JVM Agent 的插桩能力实现线上代码的实时染色,通过解析采样数据得到确切的代码执行情况,让清理工作“有据可依”。为了进一步提升效率,我们将数据采集、覆盖率计算与可视化集成至IDEA插件中,使得无效代码的识别与清理过程既准又快。
一、代码覆盖率采集方案选型
1.1 JVM Agent 概述
在Java中,插桩(Instrumentation)接口为开发者提供了在JVM运行时动态修改类字节码的能力,这是Java Agent机制的核心,常用于性能监控、AOP、代码覆盖率分析等场景。
对线上代码进行插桩,必须通过Java Agent机制在JVM启动时或运行时介入类加载过程。Agent可通过-javaagent参数在启动时加载,也可通过Attach API在运行时动态加载。两种方式对比如下:
| 类别 |
依赖重启 |
长期采集 |
资源占用 |
| agent |
是 |
稳定 |
共用JVM |
| attach |
否 |
重启失效 |
独立JVM |
- Agent方式:在JVM启动参数中指定
-javaagent加载Agent的JAR包,Agent需实现AgentMain接口。
- Attach方式:创建独立JVM,通过Attach API将插桩JAR包加载到目标JVM,插桩JAR需实现
PreMain接口。代码示例如下:
String jarFile = args[0];
String pid = getPid(args);
logger.info("Attaching agent to PID: " + pid);
VirtualMachine vm = null;
try {
vm = VirtualMachine.attach(pid);
vm.loadAgent(jarFile);
logger.info("Agent attached successfully");
} catch (IOException ioException) {
logger.critical("load agent jar fail: " + jarFile);
} catch (AttachNotSupportedException attachNotSupportedException) {
logger.critical("attach to jvm fail: " + pid);
} catch (AgentLoadException | AgentInitializationException agentException) {
logger.critical("jvm load agent or agent init fail: " + pid);
} finally {
if (vm!=null) {
vm.detach();
}
}
1.2 代码执行覆盖统计
统计代码执行情况通常基于覆盖率,包括行覆盖、分支覆盖、方法覆盖等。针对无效代码清理,我们主要关注行覆盖率,以此判断指定包或类的代码活跃情况。
1.2.1 自研插桩方案
自研插桩基于上述Agent或Attach机制,结合ASM库实现字节码修改。可按行或按方法插入探针。自定义方案的优点是数据处理灵活,但存在明显缺点:
- 执行效率低,按行插桩侵入性大。
- 高并发下存在锁竞争风险(尽管对统计结果无影响)。
- 结果数据不便与IDEA集成,可视化支持难度高。
1.2.2 JaCoCo方案
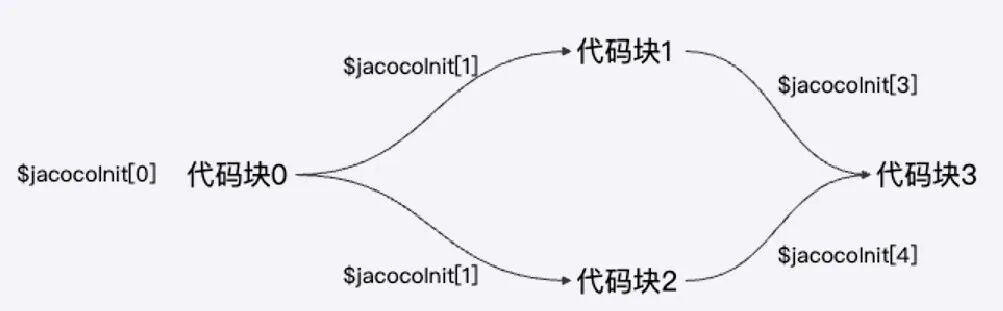
JaCoCo (Java Code Coverage) 通过在类加载时修改字节码来插入探针。它采用boolean[] $jacocoData数组记录执行情况,数组长度由控制流图(CFG)分析得出的代码块数量决定。每个布尔值代表一个基本代码块是否被执行。例如:
public void exampleMethod(int a, int b) {
// do some thing 代码块0
if(a > 0){
// do some thing 代码块1
}else if(b > 0){
// do some thing 代码块2
}
// do some thing 代码块3
}
上述代码经插桩后,探针记录逻辑如下图所示。按代码块插桩比逐行记录更高效,且使用布尔数组避免了数值累加的锁竞争问题,对性能影响极小。JaCoCo提供了成熟的Agent和CLI工具。
1.3 采集方案对比与选择
| 1.3.1 自研插桩 vs JaCoCo工具 |
方案 |
优点 |
缺点 |
| 自研插桩 |
灵活性高,数据处理方便 |
开发成本高,需稳定性验证 |
| JaCoCo工具 |
稳定高效,快速集成 |
数据格式固定,需二次加工 |
考虑到应用D对稳定性和采集性能要求极高,采用JaCoCo方案更为合适。
| 1.3.2 Agent vs Attach方式 |
对比项 |
Agent方式 |
Attach方式 |
| 使用方式 |
JVM启动参数指定 |
运行时动态附加 |
| 性能影响 |
随JVM启动,业务无感,平均CPU小幅上涨 |
Attach时触发插桩会导致CPU飙升,之后趋于稳定 |
| 重启影响 |
重启不失效 |
重启失效 |
| 卸载插桩 |
需重新发布 |
无需重启 |
- Agent方式:有一定侵入性,适合长期、稳定的覆盖率数据采集。
- Attach方式:更灵活,适合临时、单机的代码采样分析(类似Arthas)。
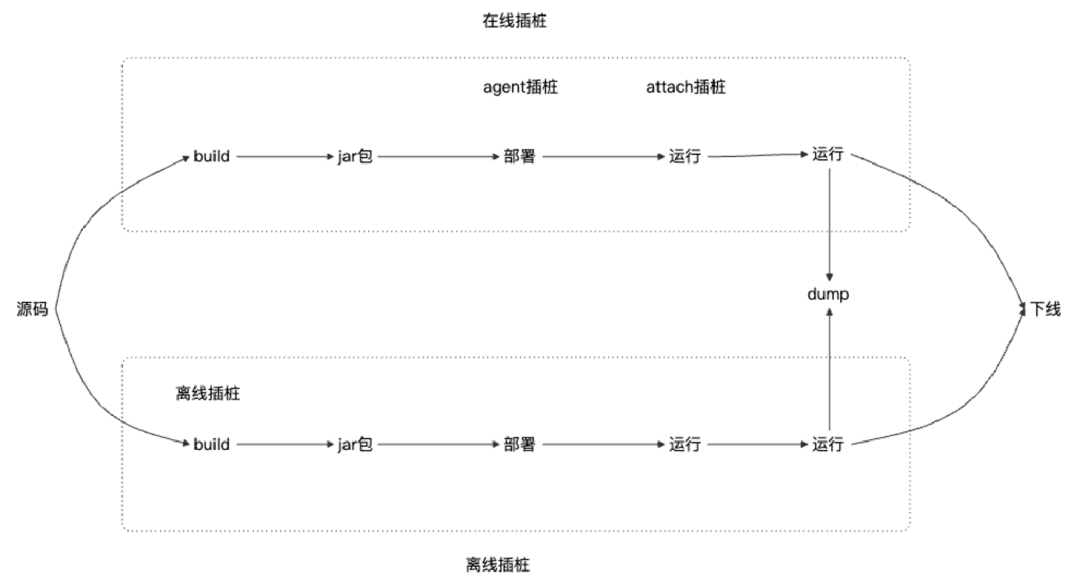
1.3.3 在线 vs 离线插桩
- 在线插桩:JVM启动后,通过Agent动态修改已加载或即将加载的类字节码。
- 离线插桩:在代码编译打包阶段,通过Maven插件直接修改字节码,部署时已是插桩后的代码。
离线插桩需在部署时引入JaCoCo的runtime依赖,否则会出现java.lang.TypeNotPresentException。
<!-- https://mvnrepository.com/artifact/org.jacoco/org.jacoco.agent -->
<dependency>
<groupId>org.jacoco</groupId>
<artifactId>org.jacoco.agent</artifactId>
<version>0.8.12</version>
<scope>runtime</scope>
<classifier>runtime</classifier>
</dependency>
离线方案适合热部署场景,但需要为采集和非采集环境分别打不同的部署包,增加了部署调度的复杂性。
1.4 最终方案选择
应用D的代码治理是长期过程,需要持续、周期性采集数据,同时兼顾稳定性和效率。因此,我们最终选择以Agent方式集成JaCoCo的方案。该方案成熟可靠,对运行时影响低。通过在Dockerfile集成依赖,在环境脚本中为JVM指定Agent参数,并限定在安全生产环境采集,实现了对线上代码执行数据的稳定采样。
二、方案落地与实现
核心工作链路如下图所示:
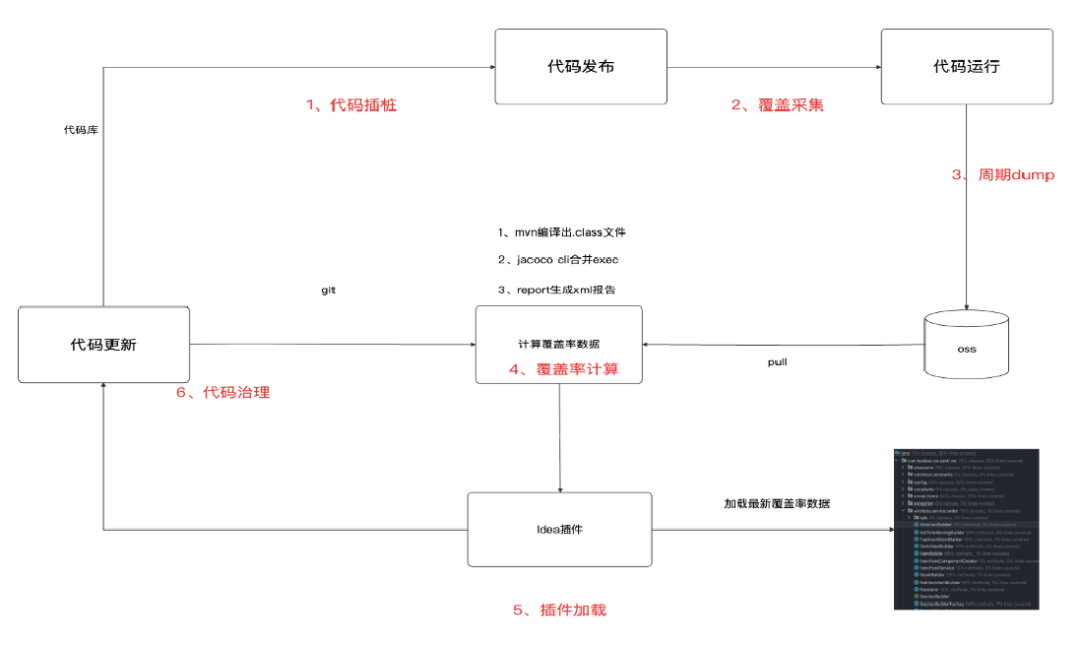
整个流程包括:代码插桩 → 覆盖采集 → 周期Dump → 报告生成 → 插件加载 → 代码治理,形成完整闭环。
2.1 整体设计目标
系统需具备以下功能:
- 代码采集:基于Agent持续采集.exec文件,不影响业务逻辑,支持多天数据合并。
- 数据合并:将.exec文件与最新版本的.class文件结合,生成完整的XML覆盖率报告。
- IDEA插件:实现覆盖率数据的可视化。插件需支持:
- 自动/手动下载OSS覆盖率数据。
- 在项目视图和编辑器侧边栏展示包、类、行级覆盖率。
- 支持数据缓存、刷新及配置管理(如OSS配置、缓存周期等)。
2.2 代码采集实施细节
2.2.1 应对热部署架构
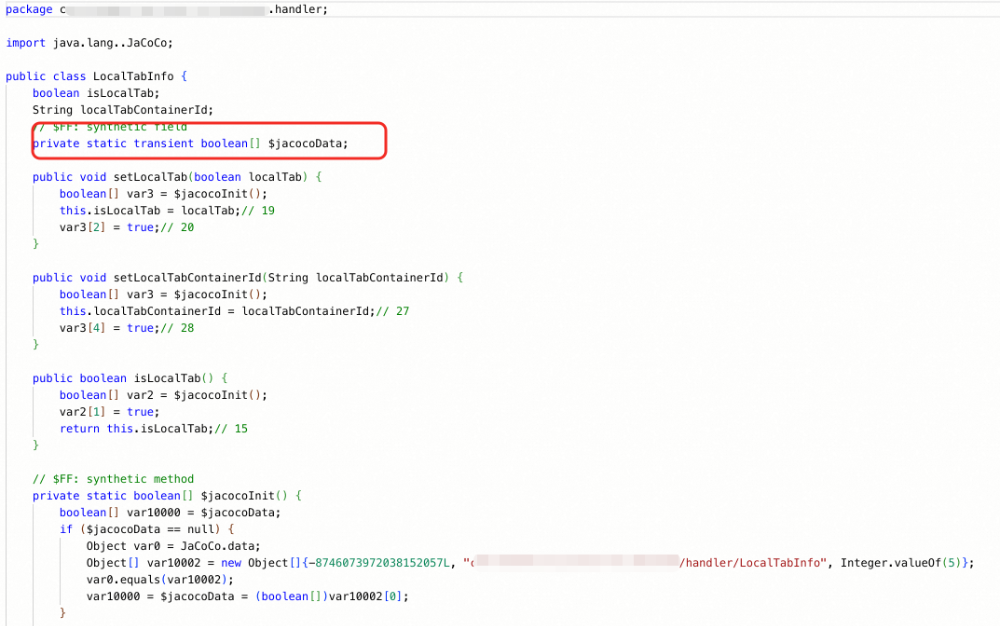
应用D之上通过自研热部署方案承载了R和B应用。业务逻辑以插件形式在R和B中开发迭代。关键在于,热部署使用的自定义ClassLoader(如YardAppClassLoader)其父加载器仍是D应用的核心ClassLoader。因此,Agent插桩对D、R、B的代码均能生效,反编译结果也验证了这一点。
- D应用插桩代码反编译示例:

- R应用插桩代码反编译示例:
2.2.2 具体改造步骤
采用Agent方式,在应用启动时加载并常驻内存。
- Dockerfile改造:在基础镜像中下载JaCoCo Agent的runtime包。
wget -c -O /home/admin/app/jacoco-runtime.jar "https://repo1.maven.org/maven2/org/JaCoCo/org.jacoco.agent/0.8.12/org.jacoco.agent-0.8.12-runtime.jar" && \
- JVM参数配置:在环境脚本中增加
-javaagent参数,并设置白名单以限定插桩范围(如D、R、B的类路径),仅在生产安全环境生效,以隔离影响。

- 周期Dump数据:部署后,代码执行数据记录在内存中。需定时将数据Dump到磁盘并上传至OSS。
boolean jacocoDump(String filePath) throws IOException {
Agent iAgent = Agent.getInstance();
if (iAgent == null) {
DosaLogUtil.warnNew("Jacoco agent not found!");
return false;
}
AgentOptions agentOptions = buildOptions(filePath);
FileOutput fileOutput = new FileOutput();
fileOutput.startup(agentOptions, iAgent.getData());
fileOutput.writeExecutionData(true);
return true;
}
我们设置了每天凌晨定时Dump,以确保分析时数据的时效性。
2.3 覆盖率数据合并与报告生成
完整的覆盖率报告(XML)由两部分合成:插桩执行文件(.exec)+ 类原始编译文件(.class)。
步骤为:
- 从OSS下载最新的.exec文件。
- 通过jGit拉取最新master代码,并在服务器本地编译生成.class文件。
- 使用JaCoCo的Report功能,合并.exec和.class,生成详细的XML覆盖率报告。
- 将报告上传至OSS。
2.3.1 使用jGit克隆代码
使用库Token(非个人账号)进行安全克隆。
public String cloneRepository(CodeProfilerAppConfigDO config) {
String appName = config.getAppName();
String localRepoPath = buildLocalRepoPath(appName);
try {
String ciToken = kcUtil.decrypt(config.getCiToken());
GitCloneRequest cloneRequest = new GitCloneRequest()
.setRepoUrl(config.getGitUrl())
.setBranch(config.getDefaultBranch())
.setTargetDir(localRepoPath)
.setCiToken(ciToken);
GitHelper.clone(cloneRequest);
return localRepoPath;
} catch (Exception exception) {
LOGGER.error("cloneRepository:clone failed for app: " + appName, exception);
return null;
}
}
2.3.2 本地Maven编译
服务器需预装Maven。使用ProcessBuilder执行Maven编译命令。
public boolean compileProject(CodeProfilerAppConfigDO config, String localRepoPath) {
String appName = config.getAppName();
String[] commands = new String[] {
MAVEN_CMD, MAVEN_COMPILE, MAVEN_SKIP_TESTS, MAVEN_TEST_SKIP, MAVEN_AUTO_CONFIG_INTERACTIVE,
MAVEN_PROJECT_BUILD_SOURCE_ENCODING
};
try {
int exitCode = MavenHelper.execute(commands, localRepoPath);
if (exitCode == 0) {
LOGGER.info("maven build succeeded for app: " + appName);
return true;
} else {
LOGGER.error("maven build failed with exit code:" + exitCode);
return false;
}
} catch (IOException | InterruptedException exception) {
LOGGER.error("compileProject:maven build failed for app:" + appName, exception);
return false;
}
}

2.3.3 生成XML报告
调用JaCoCo API,将加载的.exec数据与.class文件结合,生成最终报告。
private void createXmlReport(ExecFileLoader execFileLoader, IBundleCoverage bundleCoverage, String xmlPath)
throws Exception {
final List<IReportVisitor> visitors = new ArrayList<>();
final XMLFormatter formatter = new XMLFormatter();
visitors.add(formatter.createVisitor(Files.newOutputStream(Paths.get(xmlPath))));
IReportVisitor reportVisitor = new MultiReportVisitor(visitors);
reportVisitor.visitInfo(execFileLoader.getSessionInfoStore().getInfos(),
execFileLoader.getExecutionDataStore().getContents());
reportVisitor.visitBundle(bundleCoverage, null);
reportVisitor.visitEnd();
}
生成的XML报告按应用和日期归档在OSS。
2.4 IDEA插件设计与实现
为提升使用效率,我们开发了 IDEA插件 ,将覆盖率数据可视化集成到开发环境中。
2.4.1 插件核心功能
- 展示/隐藏覆盖率:在编辑器中标示行覆盖情况(绿-已执行,红-未执行,黄-部分执行)。
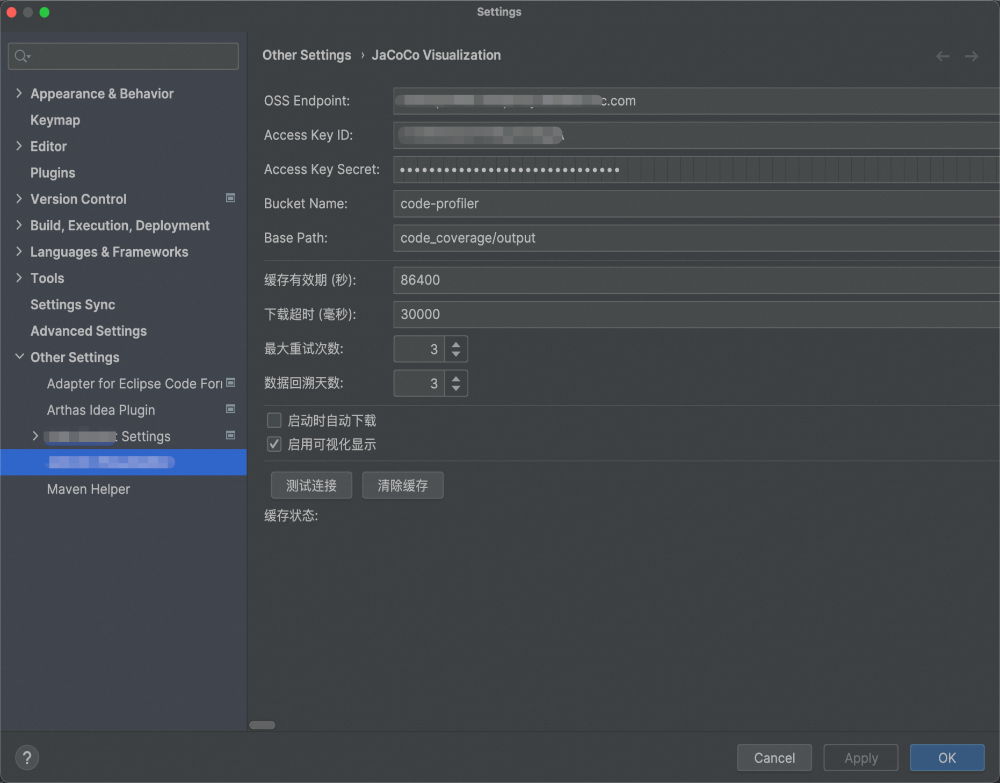
- 数据同步:自动或手动从OSS下载最新覆盖率报告。
- 配置管理:支持配置OSS信息、缓存策略、分析文件数量等。
- 数据缓存:本地缓存报告文件,提升加载速度。
2.4.2 插件实现要点
插件开发涉及IntelliJ Platform的若干概念:
- Action:处理用户交互行为,如“显示覆盖率”、“隐藏覆盖率”。
- ProjectService:封装插件核心业务逻辑。
- ApplicationConfigurable:提供插件配置界面。
这些组件需在plugin.xml中注册。插件的主要交互逻辑围绕Action展开。

2.4.3 插件使用效果
- 右键菜单:在编辑器右键菜单中提供操作入口。
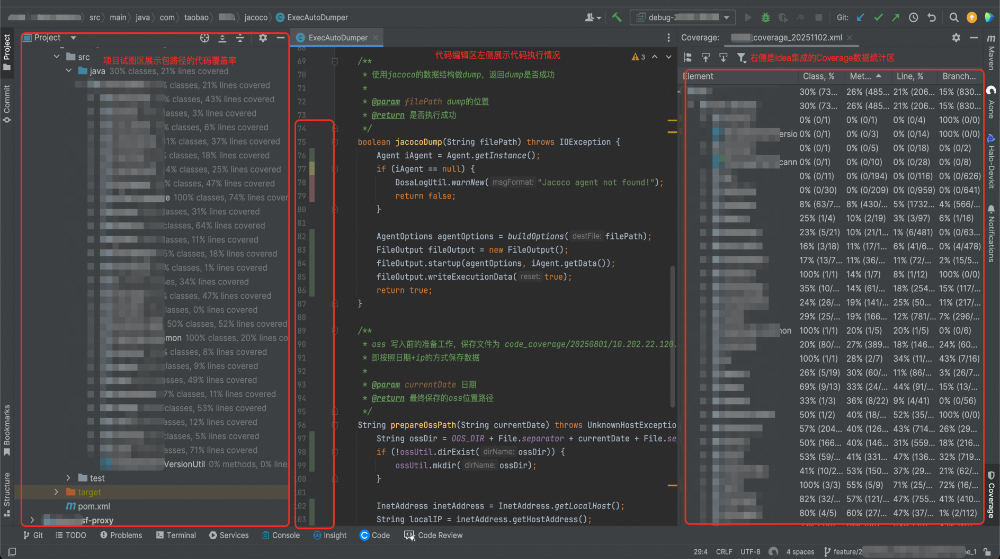
- 覆盖率展示:
- 项目视图显示包/类覆盖率,便于快速定位低覆盖率模块。
- 编辑器侧边栏显示行级覆盖状态。
- Coverage工具窗口展示详细数据,支持筛选。
- 配置界面:在
Tools -> Code Coverage Config 中打开配置面板。
三、治理效果
借助准确的执行数据和可视化插件,代码清理工作变得高效且精准。清理示例如下:
- R应用清理示例:
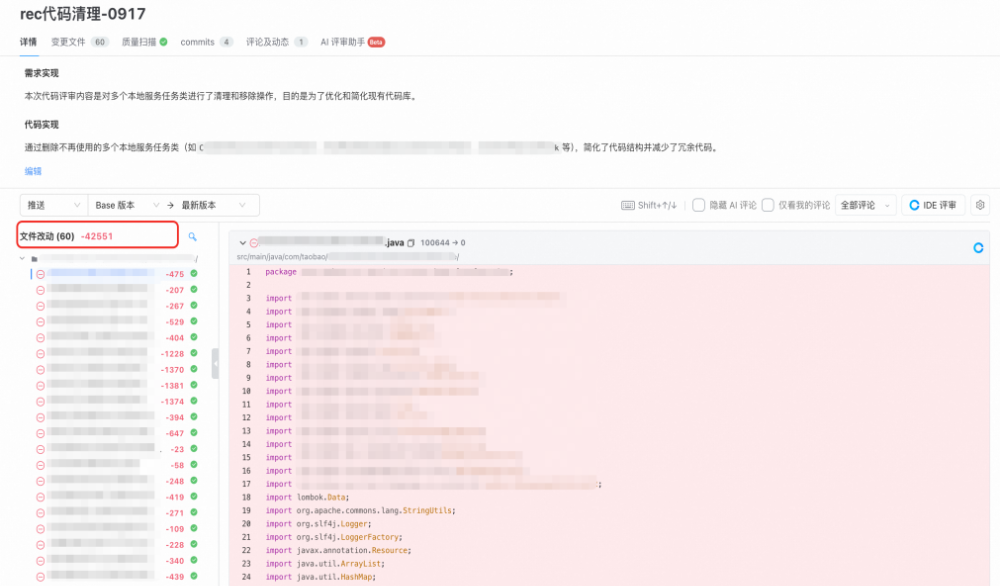
- B应用清理示例:
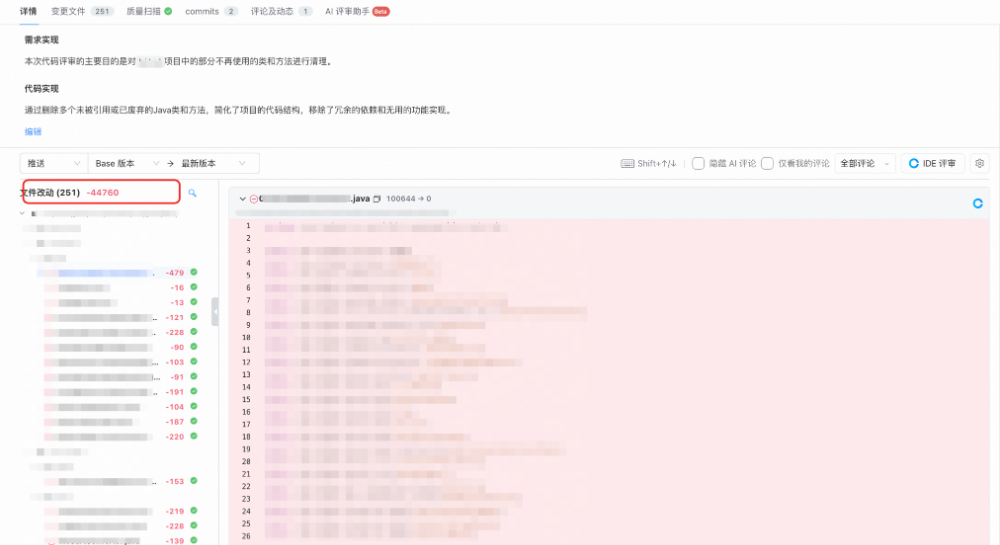
对核心应用的清理效果统计:
| 应用 |
清理前代码量 |
清理代码量 |
降低比例 |
| B应用 |
21.5万行 |
15.4万行 |
71% |
| R应用 |
43.1万行 |
18.7万行 |
43% |
| D应用 |
25.2万行 |
2.1万行 |
8.3% |
B应用因与R应用存在较多冗余,清理效果最显著;R应用作为主迭代应用,仍有清理空间;D应用作为底层依赖,清理较为谨慎,仍在进行中。
四、总结与反思
收获:
- 深入理解了JaCoCo基于ASM和访问者模式的设计,并成功借鉴其框架。
- 实现了对历史代码的规模化、精准化清理,且对业务透明。
- 掌握了IDEA插件开发流程,并通过调试社区版源码深化了对平台的理解。
反思与挑战:
- 初期对热部署的类加载机制理解不足,导致问题定位走弯路。
- 在 IDEA插件开发 初期,过度依赖AI生成完整代码,导致设计僵化和维护困难。后期转为“人工设计核心逻辑(如复用IDEA覆盖率接口)+ AI辅助定位修复”的模式,效率和质量更高。
- 安全生产环境的流量无法100%覆盖所有线上场景(如冷链路、大促链路),清理时仍需结合业务知识谨慎评估,曾遇到清理后仍有极少流量触发的情况。
参考资料
 发表于 2025-12-24 22:06:21
|
查看: 197|
回复: 0
发表于 2025-12-24 22:06:21
|
查看: 197|
回复: 0
