1. 定时器挑战:从简单到复杂的需求演进
在计算机系统中,定时器无处不在,它们如同系统的脉搏,驱动着许多核心功能的执行:
- • 网络协议中的超时重传
- • 进程调度的时间片轮转
- • 多媒体播放的帧同步
- • 用户空间的定时任务
早期的Linux内核使用简单的单链表来管理定时器。然而,随着系统复杂性和性能要求的飞速提升,尤其是在高并发网络服务中需要管理海量连接超时,这种简单结构的局限性暴露无遗。
1.1 传统定时器的问题
// 传统链表定时器的简化表示
struct timer_list {
unsigned long expires; // 到期时间
void (*function)(unsigned long); // 回调函数
unsigned long data; // 回调数据
struct timer_list *next; // 下一个定时器
};
性能瓶颈:当定时器数量膨胀到数万甚至数十万时,链表的O(n)插入和删除操作成为严重的性能瓶颈。可以想象,在一个繁忙的邮局里,所有信件都杂乱地堆在一个篮子里,每次有新信件到来,都需要从头到尾翻找合适的位置——这正是单链表定时器管理所面临的困境。
2. 时间轮的诞生:时间维度的哈希表
时间轮(Timer Wheel)的概念由George Varghese和Tony Lauck在1996年提出,其核心思想是将时间映射到一个循环队列上,类似于时钟的表盘。
2.1 单级时间轮:最简单的实现
我们先看一个简化版的单级时间轮:
#define TVR_SIZE 256 // 时间轮大小
#define TVR_MASK (TVR_SIZE - 1) // 掩码
struct timer_vec {
struct list_head vec[TVR_SIZE]; // 每个槽位的定时器链表
};
// 计算定时器应该插入的槽位
static inline unsigned int calc_index(unsigned long expires)
{
return expires & TVR_MASK; // 取模运算
}
生活比喻:想象一个拥有256个格子的旋转书架,每个格子对应未来的一个特定时间点。随着时间流逝(书架旋转),当前指针指向的格子中所有定时器都会到期并触发。
3. 多级时间轮:时间的分层管理艺术
单级时间轮存在明显局限——要么精度高但时间范围小,要么范围大但精度粗糙。为此,Linux内核采用了多级时间轮架构,巧妙地解决了这一矛盾。
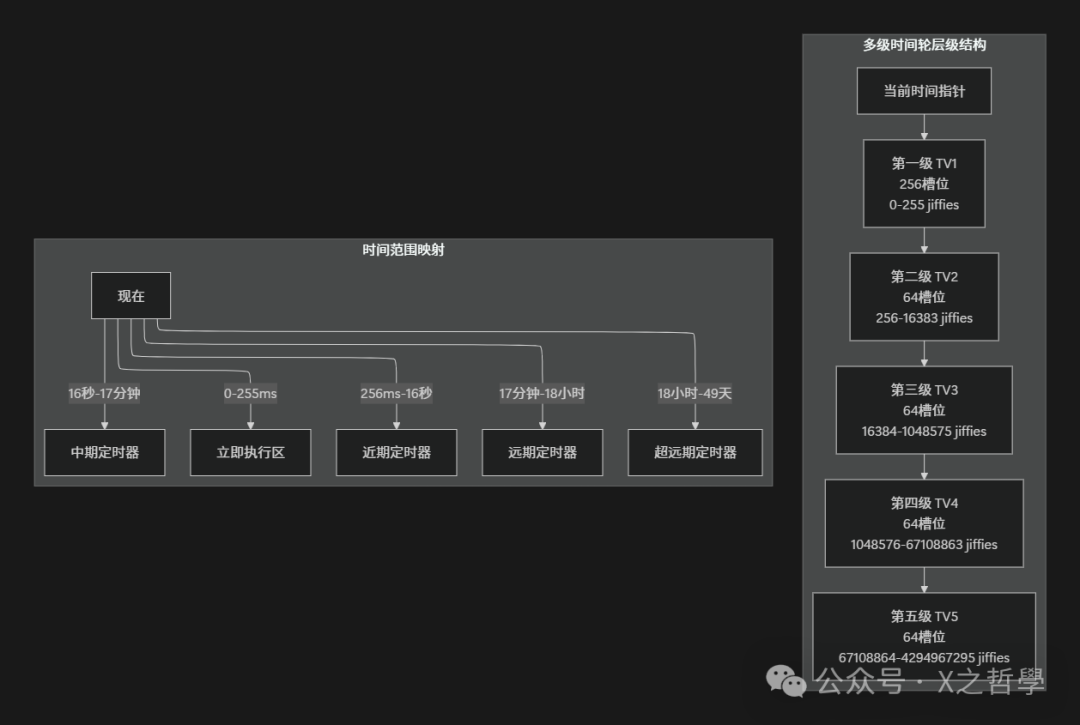
3.1 Linux内核的五级时间轮结构
// Linux 2.6+ 内核中的多级时间轮结构(简化)
#define TVR_BITS 8
#define TVN_BITS 6
#define TVR_SIZE (1 << TVR_BITS) // 256
#define TVN_SIZE (1 << TVN_BITS) // 64
struct timer_vec_root {
struct list_head vec[TVR_SIZE]; // 第一级:0-255
};
struct timer_vec {
struct list_head vec[TVN_SIZE]; // 第二到五级:各64个槽位
};
struct tvec_base {
struct timer_vec_root tv1; // 第一级:近期定时器
struct timer_vec tv2; // 第二级:中期定时器
struct timer_vec tv3; // 第三级:远期定时器
struct timer_vec tv4; // 第四级:更远期
struct timer_vec tv5; // 第五级:最远期
unsigned long timer_jiffies; // 当前时间指针
};
3.2 五级时间轮示意图
3.3 各层级时间范围计算表
| 层级 |
槽位数 |
时间范围(假设HZ=1000) |
总时间跨度 |
类比 |
| TV1 |
256 |
0-255毫秒 |
256毫秒 |
邮局的“今日投递”分拣区 |
| TV2 |
64 |
256毫秒-16.383秒 |
~16秒 |
邮局的“本市明日”分拣区 |
| TV3 |
64 |
16.384秒-17.47分钟 |
~17分钟 |
邮局的“本省本周”分拣区 |
| TV4 |
64 |
17.47分钟-18.6小时 |
~18小时 |
邮局的“国内本月”分拣区 |
| TV5 |
64 |
18.6小时-49.7天 |
~49天 |
邮局的“国际”分拣区 |
4. 工作原理详解:定时器的插入与触发
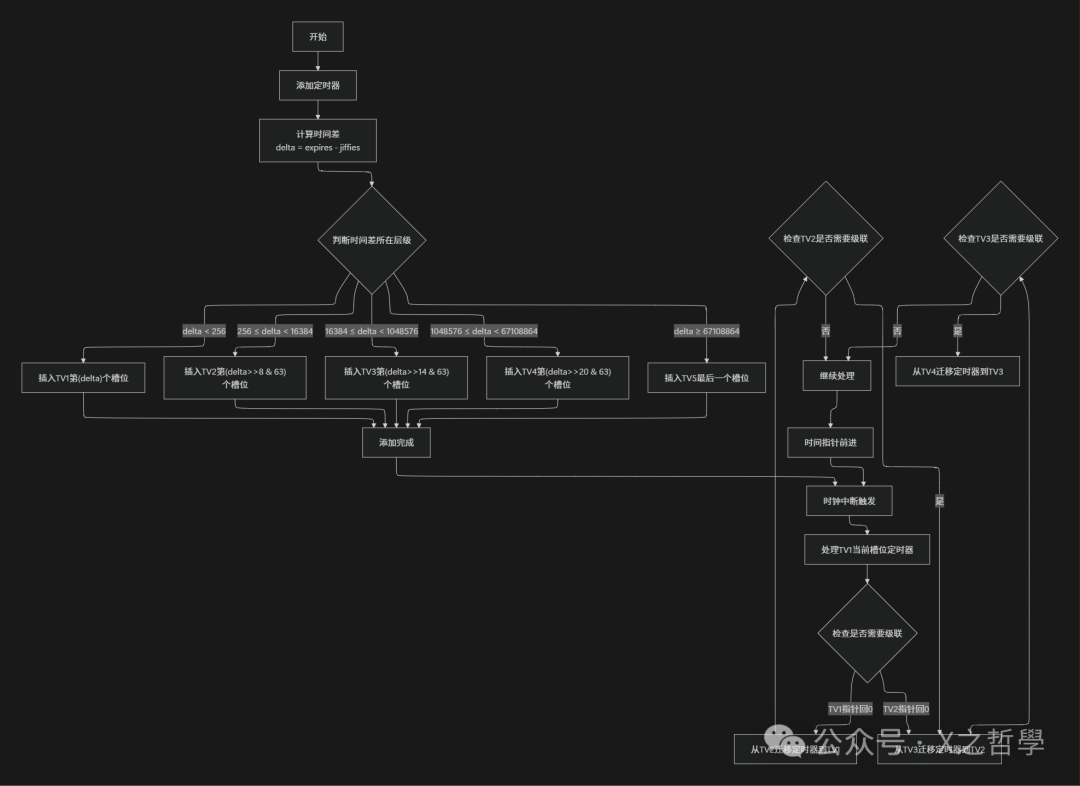
4.1 定时器插入算法
// 简化的定时器插入函数
static void internal_add_timer(struct tvec_base *base, struct timer_list *timer)
{
unsigned long expires = timer->expires;
unsigned long idx = expires - base->timer_jiffies;
struct list_head *vec;
// 根据时间差决定插入哪一级
if (idx < TVR_SIZE) {
// 近期定时器:插入TV1
int i = expires & TVR_MASK;
vec = base->tv1.vec + i;
} else if (idx < (1 << (TVR_BITS + TVN_BITS))) {
// 中期定时器:插入TV2
int i = (expires >> TVR_BITS) & TVN_MASK;
vec = base->tv2.vec + i;
} else if (idx < (1 << (TVR_BITS + 2 * TVN_BITS))) {
// 插入TV3
int i = (expires >> (TVR_BITS + TVN_BITS)) & TVN_MASK;
vec = base->tv3.vec + i;
} else if (idx < (1 << (TVR_BITS + 3 * TVN_BITS))) {
// 插入TV4
int i = (expires >> (TVR_BITS + 2 * TVN_BITS)) & TVN_MASK;
vec = base->tv4.vec + i;
} else {
// 超远期定时器:插入TV5(或TV5的最后一个槽位)
int i = (expires >> (TVR_BITS + 3 * TVN_BITS)) & TVN_MASK;
vec = base->tv5.vec + i;
}
// 将定时器添加到对应槽位的链表尾部
list_add_tail(&timer->entry, vec);
}
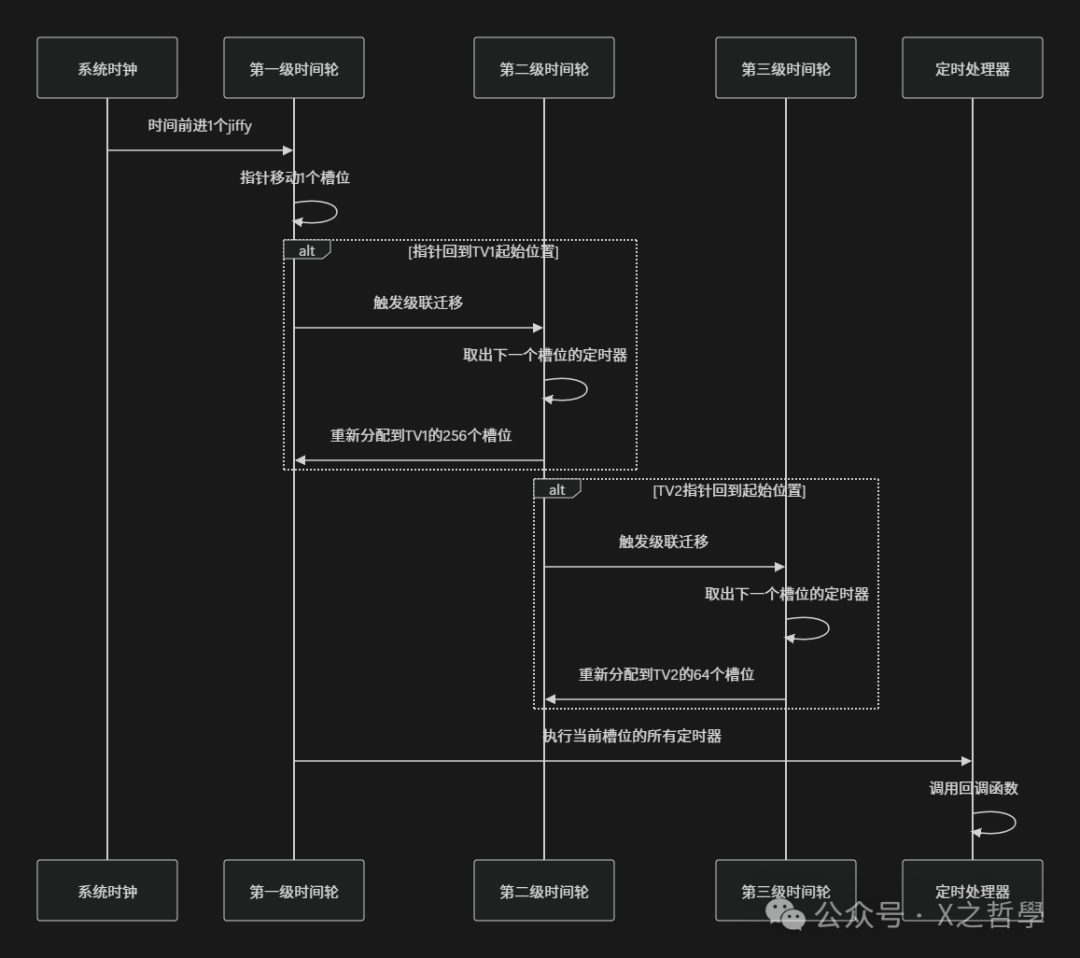
4.2 时间推进与级联迁移
当系统时间向前推进时,时间轮需要处理到期的定时器,并进行关键的级联迁移操作。
// 简化的时间轮推进函数
static int cascade(struct tvec_base *base, struct timer_vec *tv, int index)
{
struct list_head timer_list;
struct list_head *pos, *next;
// 将当前槽位的所有定时器取出
list_replace_init(tv->vec + index, &timer_list);
// 将这些定时器重新插入到合适的位置
list_for_each_safe(pos, next, &timer_list) {
struct timer_list *timer = list_entry(pos, struct timer_list, entry);
internal_add_timer(base, timer); // 重新插入
}
return index;
}
// 时间轮推进的主函数
static void __run_timers(struct tvec_base *base)
{
while (time_after_eq(jiffies, base->timer_jiffies)) {
// 计算TV1中的索引
int index = base->timer_jiffies & TVR_MASK;
// 如果索引回到0,说明TV1完成一轮,需要级联迁移
if (!index &&
(!cascade(base, &base->tv2, (base->timer_jiffies >> TVR_BITS) & TVN_MASK)) &&
(!cascade(base, &base->tv3, (base->timer_jiffies >> (TVR_BITS + TVN_BITS)) & TVN_MASK)) &&
(!cascade(base, &base->tv4, (base->timer_jiffies >> (TVR_BITS + 2*TVN_BITS)) & TVN_MASK))) {
cascade(base, &base->tv5, (base->timer_jiffies >> (TVR_BITS + 3*TVN_BITS)) & TVN_MASK);
}
// 执行当前槽位的所有定时器
struct list_head *head = &base->tv1.vec[index];
while (!list_empty(head)) {
struct timer_list *timer = list_first_entry(head, struct timer_list, entry);
list_del(&timer->entry);
// 执行定时器回调
timer->function(timer->data);
}
base->timer_jiffies++; // 时间指针向前移动
}
}
4.3 级联迁移过程示意图
5. 多级时间轮设计思想剖析
5.1 分而治之的时间管理哲学
多级时间轮的核心设计思想是分而治之,它将不同时间跨度的定时器智能地分配到不同的管理层级:
- 时间局部性原理:大多数定时器在近期触发,因此TV1被设计为具有最细的粒度(256个槽位)。
- 空间换时间:通过预分配多级固定大小的数组,将链表的O(n)操作转换为近似O(1)的操作。
- 惰性迁移:定时器只有在时间推进到需要的时候,才会从高级时间轮“级联”迁移到低级时间轮,避免了大量不必要的即时计算。
5.2 时间复杂度对比
| 操作类型 |
单链表定时器 |
单级时间轮 |
多级时间轮 |
| 添加定时器 |
O(n) |
O(1) |
O(1) |
| 删除定时器 |
O(n) |
O(1) |
O(1) |
| 触发定时器 |
O(n) |
O(1) |
O(1) |
| 空间复杂度 |
O(n) |
O(m) |
O(m) |
注:n为定时器数量,m为时间轮大小
5.3 邮局分拣系统比喻
让我们用一个更生动的比喻来理解多级时间轮的工作机制:
想象一个大型国际邮局的分拣系统
- • TV1:今日投递区(256个格子),每个格子代表未来15分钟的一个时间段。
- • TV2:本市明日区(64个格子),每个格子代表未来4小时。
- • TV3:本省本周区(64个格子),每个格子代表未来6小时。
- • TV4:国内本月区(64个格子),每个格子代表未来1天。
- • TV5:国际区(64个格子),每个格子代表未来3天。
每天早上8点(对应系统时钟的一次滴答):
- 邮局员工(定时器子系统)处理“今日投递区”当前时间格子的所有信件(定时器)。
- 如果“今日投递区”处理完一整轮(256个格子),就从“本市明日区”取出下一个格子的信件,根据其具体投递时间,重新精细分拣到“今日投递区”的256个格子中。
- 类似地,各级之间都会在必要时进行这样的“级联迁移”。
这样的设计确保了:
- • 紧急信件(近期定时器)能得到最快速度的处理。
- • 远期信件不会占用处理近期事务的宝贵资源。
- • 分拣员(CPU)不需要费力记住每封信的具体投递时间,只需按格处理即可,极大地提升了在网络与系统编程中的处理效率。
6. Linux内核实现细节
6.1 内核中的实际数据结构
// Linux内核实际的时间轮结构(kernel/timer.c)
struct tvec_base {
spinlock_t lock;
struct timer_list *running_timer;
unsigned long timer_jiffies;
unsigned long next_timer;
struct tvec_root tv1;
struct tvec tv2;
struct tvec tv3;
struct tvec tv4;
struct tvec tv5;
} ____cacheline_aligned;
// 定时器结构
struct timer_list {
struct list_head entry;
unsigned long expires;
void (*function)(unsigned long);
unsigned long data;
struct tvec_base *base;
int slack;
};
6.2 定时器API使用示例
#include <linux/module.h>
#include <linux/timer.h>
#include <linux/jiffies.h>
struct my_data {
struct timer_list my_timer;
int count;
};
static void my_timer_callback(unsigned long data)
{
struct my_data *md = (struct my_data *)data;
pr_info("定时器触发! 计数: %d\n", md->count);
// 重新设置定时器(实现周期性触发)
md->count++;
mod_timer(&md->my_timer, jiffies + msecs_to_jiffies(1000));
}
static int __init my_module_init(void)
{
struct my_data *md;
md = kmalloc(sizeof(*md), GFP_KERNEL);
if (!md)
return -ENOMEM;
md->count = 0;
// 初始化定时器结构
init_timer(&md->my_timer);
md->my_timer.function = my_timer_callback;
md->my_timer.data = (unsigned long)md;
md->my_timer.expires = jiffies + msecs_to_jiffies(1000);
// 添加定时器到时间轮
add_timer(&md->my_timer);
pr_info("定时器模块加载\n");
return 0;
}
6.3 时间轮操作流程图
7. 性能优化与高级特性
7.1 松弛时间(Timer Slack)
为了进一步优化系统性能和功耗,Linux内核引入了松弛时间的概念。它允许定时器在到期时间附近的一个时间窗口内触发,而非严格准时。
struct timer_list {
// ... 其他字段
int slack; // 松弛时间,单位为jiffies
};
// 设置定时器时可以指定松弛时间
timer->slack = msecs_to_jiffies(10); // 10毫秒的松弛窗口
为什么需要松弛时间?
- • 批量处理:允许内核将到期时间相近的多个定时器合并处理,减少处理次数。
- • 降低功耗:减少CPU被频繁唤醒的次数,对移动设备和服务器节能至关重要。
- • 提高缓存效率:批量处理有利于提高CPU缓存的命中率。
7.2 高精度定时器(hrtimer)
对于需要微秒甚至纳秒级精度的应用(如音视频同步、实时控制),标准时间轮无法满足要求。为此,Linux提供了独立的高精度定时器子系统。
// 高精度定时器结构
struct hrtimer {
struct timerqueue_node node;
ktime_t _softexpires;
enum hrtimer_restart (*function)(struct hrtimer *);
struct hrtimer_clock_base *base;
unsigned long state;
};
// 使用示例
static enum hrtimer_restart hrtimer_callback(struct hrtimer *timer)
{
pr_info("高精度定时器触发!\n");
return HRTIMER_NORESTART;
}
// 设置1毫秒精度的定时器
hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);
timer.function = hrtimer_callback;
hrtimer_start(&timer, ms_to_ktime(1), HRTIMER_MODE_REL);
7.3 多CPU时间轮扩展
在现代多核系统中,为了解决锁竞争问题,Linux为每个CPU核心都维护了独立的时间轮结构。
// 每个CPU都有自己独立的时间轮指针
DEFINE_PER_CPU(struct tvec_base *, tvec_bases);
// 定时器默认被添加到当前CPU的时间轮,减少锁竞争
void add_timer(struct timer_list *timer)
{
struct tvec_base *base = get_cpu_var(tvec_bases);
spin_lock(&base->lock);
// 添加定时器到当前CPU的时间轮
internal_add_timer(base, timer);
spin_unlock(&base->lock);
put_cpu_var(tvec_bases);
}
这种每CPU变量的设计是Linux内核应对高并发挑战的常见优化手段之一。
8. 调试与监控工具
8.1 内核调试接口
# 查看系统定时器统计信息
cat /proc/timer_stats
# 查看高精度定时器的详细列表和状态
cat /proc/timer_list
# 动态启用定时器相关代码的调试打印
echo 'file kernel/timer.c +p' > /sys/kernel/debug/dynamic_debug/control
8.2 ftrace跟踪定时器
# 启用定时器相关的跟踪点
echo 1 > /sys/kernel/debug/tracing/events/timer/enable
# 查看实时的定时器跟踪信息
cat /sys/kernel/debug/tracing/trace
# 可以过滤特定事件,例如只查看定时器到期事件
echo "timer_expire_entry != 0" > /sys/kernel/debug/tracing/events/timer/filter
8.3 SystemTap监控脚本
// 监控定时器的添加和删除
probe kernel.function("add_timer") {
printf("添加定时器: %p, 到期时间: %d\n",
$timer, $timer->expires - timer_jiffies());
}
probe kernel.function("del_timer") {
printf("删除定时器: %p\n", $timer);
}
// 监控定时器批处理执行过程
probe kernel.function("__run_timers") {
printf("运行定时器批次,当前jiffies: %d\n", timer_jiffies());
}
掌握这些运维与调试工具对于深入理解内核行为和排查复杂问题非常有帮助。
9. 用户空间定时器实现示例
尽管多级时间轮主要服务于内核,但其精巧的设计思想同样可以应用于用户空间的高性能网络库或游戏服务器中,用于管理海量连接超时或技能冷却。
// 用户空间多级时间轮简化实现
#include <stdint.h>
#include <stdlib.h>
#include <sys/time.h>
#define TVR_BITS 8
#define TVN_BITS 6
#define TVR_SIZE (1 << TVR_BITS)
#define TVN_SIZE (1 << TVN_BITS)
typedef void (*timer_cb)(void *arg);
struct timer_node {
struct timer_node *next;
uint64_t expire;
timer_cb callback;
void *arg;
};
struct timer_wheel {
struct timer_node *tv1[TVR_SIZE];
struct timer_node *tv2[TVN_SIZE];
struct timer_node *tv3[TVN_SIZE];
struct timer_node *tv4[TVN_SIZE];
uint64_t current_time;
};
// 计算时间差并决定插入位置
void add_timer(struct timer_wheel *tw, uint64_t expire,
timer_cb cb, void *arg) {
uint64_t diff = expire - tw->current_time;
struct timer_node *node = malloc(sizeof(struct timer_node));
node->expire = expire;
node->callback = cb;
node->arg = arg;
if (diff < TVR_SIZE) {
// 插入tv1
int index = expire & (TVR_SIZE - 1);
node->next = tw->tv1[index];
tw->tv1[index] = node;
} else if (diff < (1 << (TVR_BITS + TVN_BITS))) {
// 插入tv2
int index = (expire >> TVR_BITS) & (TVN_SIZE - 1);
node->next = tw->tv2[index];
tw->tv2[index] = node;
}
// ... 其他级别的处理逻辑类似
}
// 执行到期的定时器
void execute_timers(struct timer_wheel *tw) {
int index = tw->current_time & (TVR_SIZE - 1);
// 处理当前槽位的所有定时器
struct timer_node **pp = &tw->tv1[index];
while (*pp) {
struct timer_node *node = *pp;
if (node->expire <= tw->current_time) {
// 执行回调
node->callback(node->arg);
// 从链表中移除并释放
*pp = node->next;
free(node);
} else {
pp = &(*pp)->next;
}
}
tw->current_time++;
// 级联迁移(当tv1完成一轮时)
if (index == 0) {
cascade(tw, tw->tv2, (tw->current_time >> TVR_BITS) & (TVN_SIZE - 1));
}
}
10. 多级时间轮的演进与替代方案
10.1 现代Linux的时间管理演进
| 内核版本 |
定时器系统改进 |
特点 |
| 2.4及之前 |
单链表定时器 |
实现简单,但性能差 |
| 2.6 |
引入多级时间轮 |
O(1)时间复杂度,支持长延时定时器 |
| 2.6.16 |
引入高精度定时器(hrtimer) |
提供纳秒级精度 |
| 3.0+ |
时间轮持续优化 |
减少锁竞争,更好的多核支持 |
| 4.14+ |
timer migration 机制 |
优化定时器在CPU间的迁移,提升负载均衡 |
10.2 替代数据结构对比
| 数据结构 |
插入复杂度 |
删除复杂度 |
触发复杂度 |
适用场景 |
| 排序链表 |
O(n) |
O(n) |
O(1) |
定时器数量极少的场景 |
| 最小堆 |
O(log n) |
O(log n) |
O(log n) |
定时器数量中等,对精度要求高 |
| 时间轮 |
O(1) |
O(1) |
O(1) |
定时器数量多,到期时间分布离散 |
| 红黑树 |
O(log n) |
O(log n) |
O(log n) |
需要频繁动态调整或取消定时器 |
10.3 未来发展方向
- 硬件辅助定时器:更深度地利用现代CPU提供的硬件定时器资源,进一步降低延迟和CPU开销。
- 无锁化设计:探索完全无锁的时间轮实现,彻底消除锁竞争,适应极端高并发场景。
- 智能批处理:基于历史数据或简单预测模型,智能调整定时器的批处理策略,在延迟和吞吐量之间寻找更优平衡。
- 功耗优先调度:为移动设备和数据中心设计更省电的定时器唤醒策略,将功耗作为核心优化指标。
11. 总结:多级时间轮的设计哲学
通过深入分析Linux多级时间轮,我们可以总结出以下核心设计原则,这些原则在许多系统软件设计中都具有普适性:
11.1 核心设计思想总结
| 设计原则 |
具体实现 |
带来的好处 |
| 分而治之 |
五级时间轮分层管理 |
完美平衡了时间管理精度与范围 |
| 时间局部性优化 |
TV1粒度最细,槽位最多 |
显著提高近期定时器的处理效率 |
| 惰性计算 |
只在必要时进行级联迁移 |
大幅减少不必要的计算开销 |
| 空间换时间 |
预分配固定大小的槽位数组 |
实现O(1)时间复杂度的关键操作 |
| 分级细化 |
越近期的时间轮,其粒度越精细 |
符合实际应用中定时器到期时间分布的统计规律 |
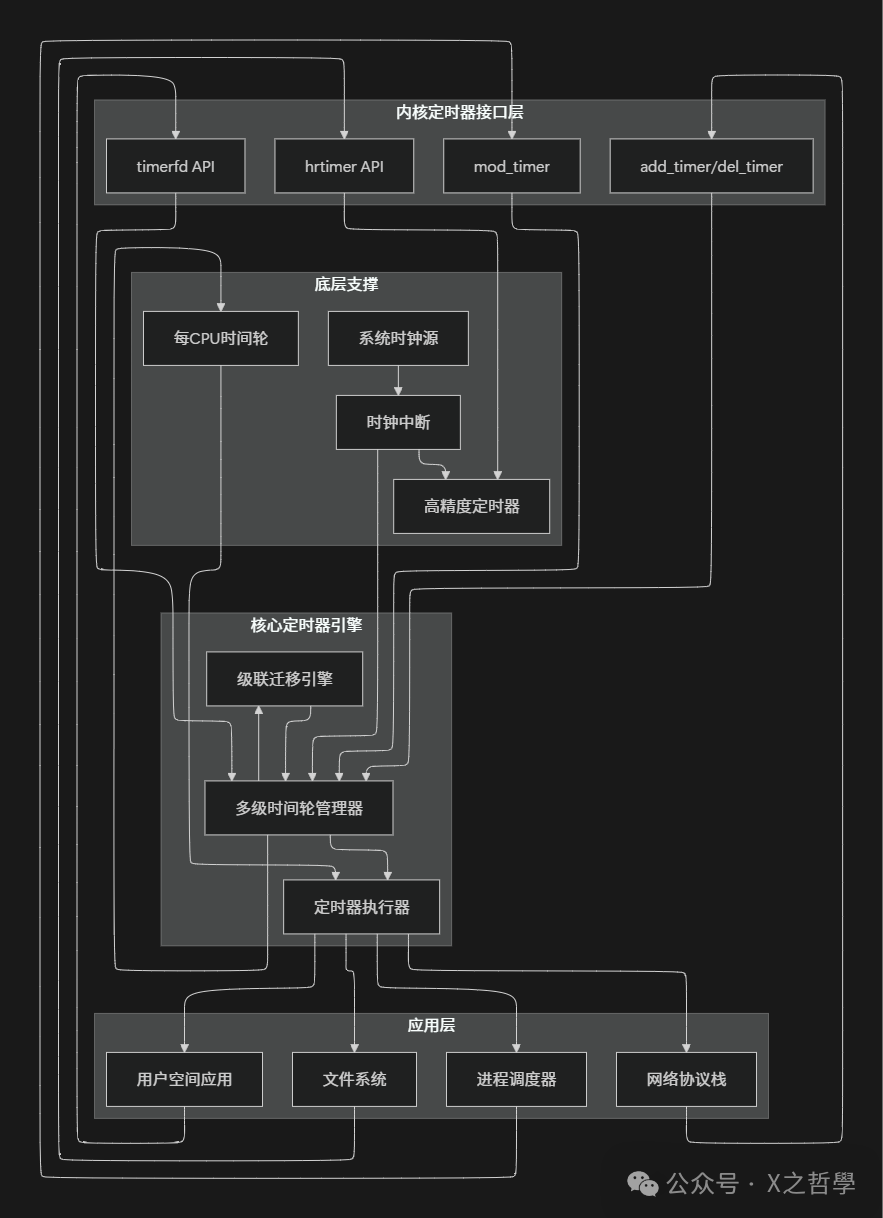
11.2 系统架构全景图
11.3 关键启示
- 简单性并不总是最优解:单链表虽然简单直观,但在海量数据场景下,精心设计的复杂数据结构(如时间轮)反而能带来整体系统架构的简化与性能的飞跃。
- 深刻理解数据特性是成功的关键:时间轮的成功,根本在于对“定时器到期时间分布”这一数据特性的深刻洞察与利用。
- 分层是解决“范围-精度”矛盾的利器:这一思想不仅应用于定时器,在网络路由、文件系统缓存、内存管理等诸多领域都有广泛应用。
- 工程是权衡的艺术:Linux的五级时间轮(8-6-6-6-6)并非唯一解,而是性能、内存占用、代码复杂度三者之间经过千锤百炼后找到的精巧平衡点。
Linux多级时间轮是操作系统底层设计中的一颗明珠,它优雅地展示了如何通过精巧的数据结构,将一个看似简单的定时器管理问题,转化为高效、可扩展的核心系统组件。这一设计思想的影响早已超出内核范畴,为众多分布式系统、网络设备、实时应用和游戏服务器提供了宝贵的设计范本。
 发表于 2025-12-25 04:43:47
|
查看: 157|
回复: 0
发表于 2025-12-25 04:43:47
|
查看: 157|
回复: 0
