
在多模态大模型快速演进的时代,语音交互正经历一场范式变革,从传统的“语音识别+文本大模型+语音合成”串行流水线,迈向真正一体化的端到端语音智能新阶段。
Fun-Audio-Chat 是该领域的一个关键开源项目,由阿里通义语音团队贡献。它是一个支持 Speech-to-Speech(语音直接生成语音) 的大型音频语言模型,在语音理解、问答、情绪共鸣与实时交互方面展现出了卓越性能,为人工智能驱动的自然对话提供了新思路。
一、项目背景与定位
Fun-Audio-Chat 致力于打造更自然、延迟更低、更贴近人类真实交流方式的语音交互系统。与传统方案不同,它摒弃了对显式中间文本表示的依赖,直接在音频模态下完成对输入的理解和语音的生成。
项目地址:
二、整体架构:端到端 Speech-to-Speech
1️⃣ 摆脱三段式语音流水线
传统的语音对话系统通常遵循如下流程:
ASR(语音识别) → LLM(文本推理) → TTS(语音合成)
这一结构存在几个固有缺陷:
- 累积延迟高
- 系统组件复杂,维护成本大
- 说话人情绪、语气、韵律等丰富信息在ASR转文本阶段大量丢失
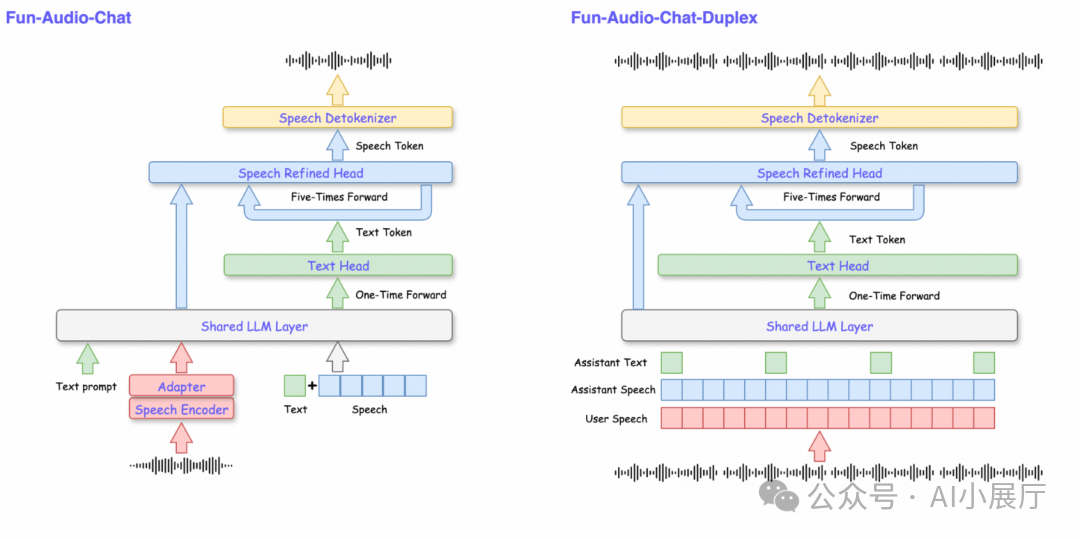
Fun-Audio-Chat 采用了端到端的 Speech-to-Speech 架构,模型直接从原始语音输入生成语音回复,极大简化了系统流程,为实现流畅、低延迟的实时对话体验奠定了基础。
2️⃣ 双分辨率语音表示(Dual-Resolution)
这是 Fun-Audio-Chat 的一项核心技术创新。模型将语音建模任务拆分为两个时间分辨率不同的子模块进行协同处理:
- 低分辨率语义主干(约 5 Hz)
- 负责核心的语言理解和语义建模。
- 低帧率处理显著降低了计算复杂度和内存占用。
- 高分辨率语音生成头(约 25 Hz)
- 负责合成高质量的语音细节,包括音色、韵律和自然度。
- 保证最终输出语音的听觉效果。
这种巧妙的深度学习架构设计,在基本不牺牲合成音质的前提下,大幅降低了推理成本。据评估,相比传统的高帧率语音建模方案,其GPU计算量可减少约50%。
三、Core-Cocktail:多任务统一训练策略
Fun-Audio-Chat 并非针对单一语音生成任务进行训练,而是采用了 Core-Cocktail 多任务训练策略,将多种相关能力整合到同一个模型中。
该策略的主要特点包括:
- 保留并继承了文本大模型级别的强大语言理解与推理能力。
- 联合训练语音理解、语音问答、指令跟随、情绪感知等多个任务。
- 显著提升了模型在复杂、开放的真实场景下的泛化与应用能力。
这种训练方式有效避免了模型“只会模仿语音,而不懂内容”的局限,确保了其在语义层面的扎实功底。
四、核心能力详解
1️⃣ 语音问答(Spoken QA)
模型能够直接理解用户的语音问题,并用语音进行回答,覆盖范围包括:
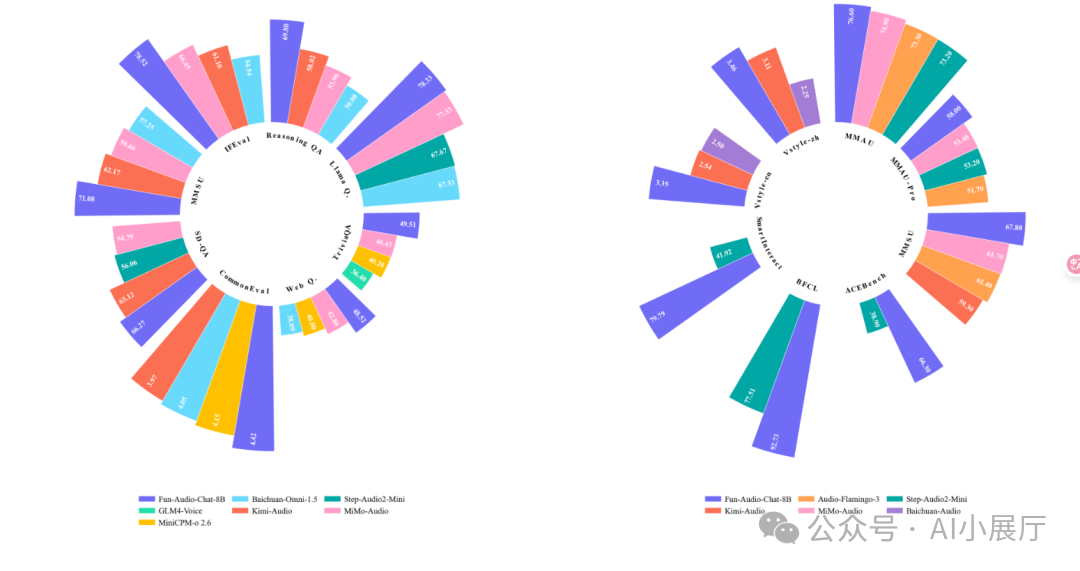
在 OpenAudioBench、VoiceBench、UltraEval-Audio 等权威基准测试中,Fun-Audio-Chat 在同参数规模模型中表现处于领先地位。
2️⃣ 语音理解(Audio Understanding)
能力不止于“听清字词”,还包括更深层次的:
- 说话人情绪识别
- 音频事件识别(如笑声、掌声)
- 背景声音理解
- 多说话人语境分析
这使得模型能从复杂的音频环境中提取更丰富、更具上下文价值的语义信息。
3️⃣ 语音指令与函数调用(Speech Function Calling)
Fun-Audio-Chat 能够将自然的语音指令映射为结构化的函数调用,例如:
- “帮我设置明天上午10点的会议提醒”
- “查询北京今天的天气”
- “打开客厅的灯”
这一能力为构建更智能的语音 Agent 和交互式助手提供了关键技术支撑。
4️⃣ 语音指令属性控制
用户可以通过语音直接控制合成输出的风格属性,例如:
- 语速:“说慢一点”
- 情绪:“用开心的语气说”
- 表达风格:“正式一点”
模型能够理解这些高层控制指令,并在语音生成阶段准确体现。
5️⃣ 情感共鸣(Voice Empathy)
模型具备基础的共情与情绪感知能力,可以根据用户的语气和内容生成更贴合语境的回应。例如,当感知到用户情绪低落时,它会生成更温和、更具同理心的语音反馈。
6️⃣ 全双工实时交互(Full-Duplex)
区别于传统的“一问一答”式系统,Fun-Audio-Chat 支持全双工交互模式:
- 模型在说话时,可以继续监听用户的输入。
- 用户可以随时打断模型的回应。
- 交互节奏更接近真实、自然的人类对话。
这一特性对于实时语音助手、智能客服等需要流畅打断和抢话的场景至关重要。
五、模型规模与部署信息
- 参数规模:8B(80亿参数)
- 语言支持:中英双语
- 推理显存需求:约需 24GB GPU 显存
- 训练方式:基于多任务联合训练的端到端语音建模
项目官方已提供了完整的推理代码与部署示例,便于研究者进行实验和开发者进行二次开发集成。
六、适用场景
Fun-Audio-Chat 适用于多种需要智能语音交互的场景,包括但不限于:
- 新一代智能语音助手(如手机、智能音箱)
- 智能客服与语音应答系统
- 语音陪伴、教育及娱乐应用
- 语音控制的家居或车载设备
- 情感计算与语音交互前沿研究
 发表于 2025-12-25 04:45:55
|
查看: 205|
回复: 0
发表于 2025-12-25 04:45:55
|
查看: 205|
回复: 0
