在当前处理各式各样文档(如报告、论文、票据等)的实际业务场景中,我们往往面临几个共同的难题。无论是采用基于集成的方案,将多个专业模型组装成复杂的流水线,还是使用基于端到端的方法,让视觉语言模型自回归地直接输出结构化结果,都难以在精度、速度和成本之间找到完美的平衡点。
复杂的版面布局(如跨行表格、多栏文本)常常让模型措手不及,导致内容缺失或格式错乱;大多数模型逐页处理的方式,又会让跨页的段落或表格信息变得支离破碎。更重要的是,想要获得理想的解析效果,往往需要动用并微调数十亿参数的大模型配合专业显卡,这不仅部署成本高昂,推理速度也难以满足生产环境对实时性的要求。
那么,是否存在一种方案,既能精准解析复杂的文档布局,又能兼顾高效推理与轻量级部署呢?
近期,LightOnAI开源的LightOnOCR-2-1B模型,为我们提供了一个颇具吸引力的新选择。作为第二代仅10亿参数的OCR模型,它旨在直接将PDF等文档页面一次性转换为清晰、结构化的文本,摒弃了传统的多阶段流程,在速度、精度和模型体积上取得了显著的突破。

相关资源链接:
为什么我们需要轻量级的端到端OCR模型?
现实世界中的文档处理任务充满了挑战。多栏布局中的阅读顺序时常模糊不清,表格需要维持其原有的行列结构,而科研文献PDF中则常常混合了密集的文字排版、复杂的数学公式、图表以及质量不佳的扫描图像。
目前主流的OCR解决方案,例如PaddleOCR等,通常依赖于一套复杂的多阶段流程:先进行版面分析(Layout Analysis),接着检测文本区域(Text Detection),然后识别文字内容(Text Recognition),最后再重建阅读顺序。这套“组合拳”虽然模块清晰,但任何一个环节出现差错都可能引发连锁反应,导致最终结果不佳。此外,针对新的文档类型,往往需要为每个模块重新标注和调整,成本不菲。多阶段处理本身也带来了额外的计算与时间开销。
而目前采用端到端方法的模型,尤其是类似GPT-4o、Qwen2.5-VL这类大型视觉语言模型,在直接处理文档图像并生成结构化表示方面展现出了强大潜力。它们不仅能提取文字,还能完成表格分析、图表解读等复杂任务。
但这类方案的瓶颈同样明显:模型参数量巨大、推理速度缓慢、资源消耗极高。处理一张A4文档可能需要数秒,这在高吞吐量的生产场景中几乎是不可接受的。因此,我们迫切需要一种既轻量又高效的解析模型。
LightOnOCR-2-1B的核心亮点
1. 综合精度全面领先
在权威的OlmOCR-Bench评测中,LightOnOCR-2-1B取得了综合得分83.2的成绩,超越了所有参评系统,其中包括许多参数规模更大的模型。
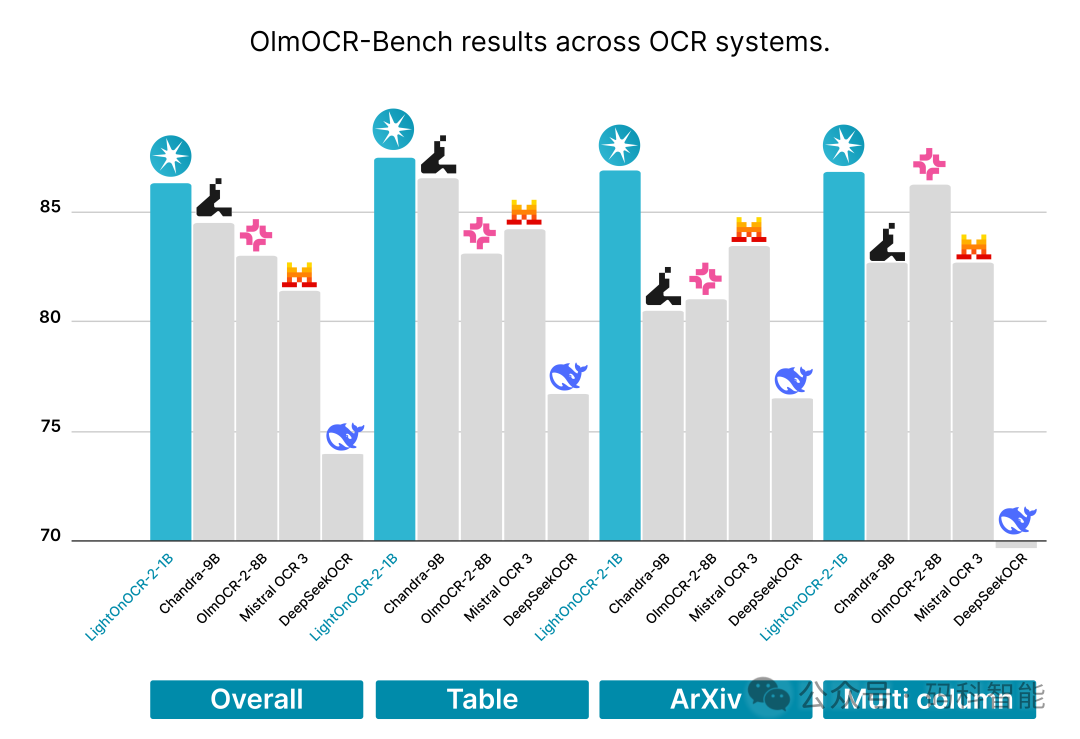
尤其是在处理科学文献(ArXiv)、包含数学公式的旧扫描件以及复杂表格数据等传统OCR难点领域,其表现尤为突出。下面的对比表格直观展示了其领先地位:
| 模型 |
参数规模 |
OlmOCR分数 |
相对速度 |
| LightOnOCR-2-1B |
10亿 |
83.2 |
基准 |
| Chandra-9B |
90亿 |
81.7 |
慢3.3倍 |
| OlmOCR-2-8B |
约28亿 |
81.5 |
慢1.7倍 |
| PaddleOCR-VL |
9亿 |
80.5 |
慢2倍 |
2. 推理速度优势明显
在生产环境中,吞吐量与精度同等重要。在NVIDIA H100上的全流程测试显示,LightOnOCR-2-1B的速度表现卓越:
- 比 Chandra-9B 快 3.3倍
- 比 PaddleOCR-VL-0.9B 快 2倍
- 比 DeepSeek-OCR 快 1.73倍
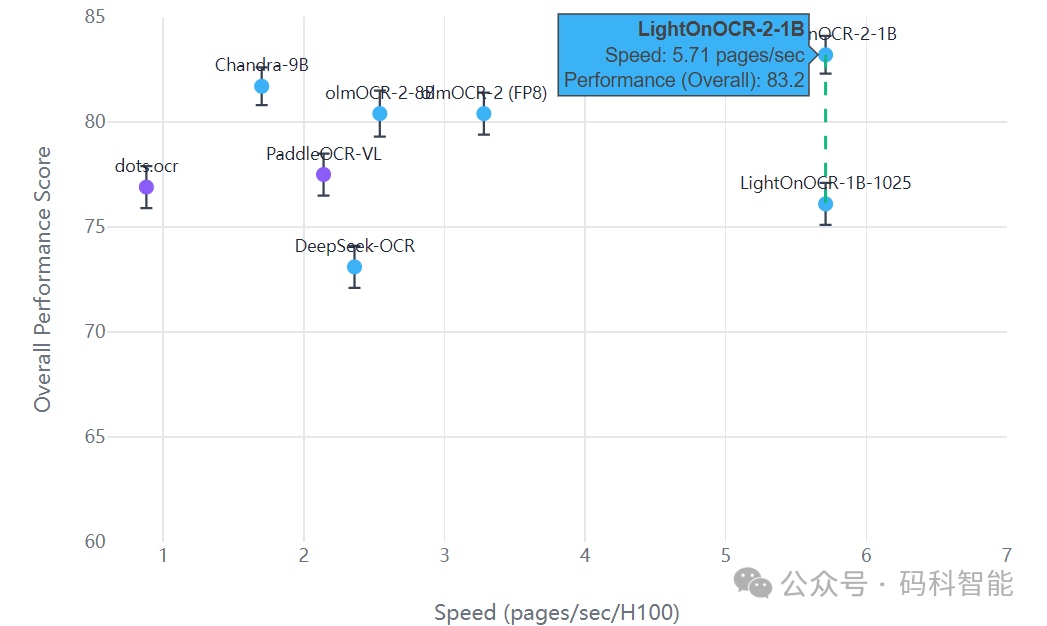
上图的散点分布清晰表明,LightOnOCR-2-1B(右上角高亮点)在速度和整体性能得分上均处于领先位置,实现了“又快又好”的目标。
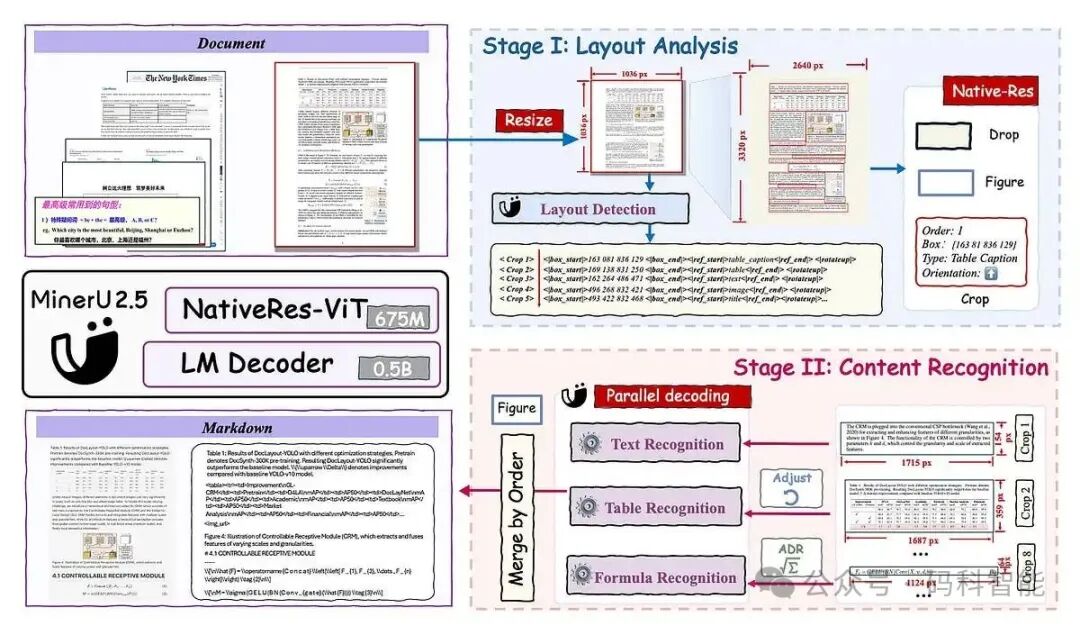
3. 先进且简洁的模型架构
该模型采用简洁高效的架构设计:
- 视觉编码器:基于Mistral-Small-3.1,具备处理原生高分辨率图像的能力。
- 语言解码器:基于Qwen2.5,负责输出线性化的、结构清晰的文档表示。
这种设计避免了传统流程的冗余步骤,通过端到端训练,使模型能更好地理解文档的全局上下文与局部细节之间的关系。
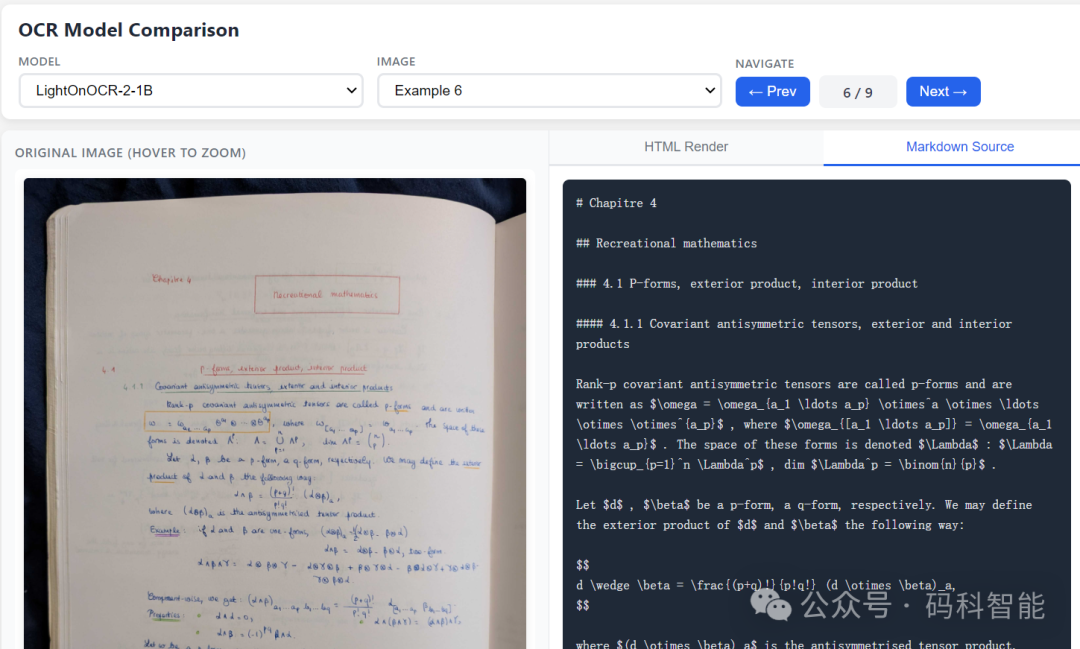
4. 强大的复杂文档解析能力
对于包含手写公式、密集排版等元素的复杂文档,LightOnOCR-2-1B能够准确识别并还原其结构和内容,例如将手写数学笔记转换为规范的Markdown格式,并正确保留LaTeX公式。
5. 开放与灵活的生态
LightOnAI同步开源了用于训练的两个高质量数据集,为社区进一步的开源实战与研究提供了宝贵资源:
- 包含超过1600万个高质量标注的文档页面。
- 包含近50万个带有图形和图像边界框的高质量标注。
此外,模型系列提供了多种选项,包括仅文本识别的版本、带边界框输出功能的版本、预训练模型以及用于领域微调的基础模型。这使得用户不仅能提取文本,还能获取文档中图片、图表的位置及其与周围文字的关联信息。
总结
LightOnOCR-2-1B的出现,为轻量级、高性能的文档智能解析提供了一个强有力的新选项。它通过端到端的方式,直接将文档图像转换为干净、有序的结构化文本,绕过了传统OCR流程中脆弱的多阶段依赖。其在OlmOCR-Bench上达到的先进性能,结合比同类最佳模型小数倍的体积和显著的推理速度提升,使其在需要平衡效果、效率与成本的实用场景中具有很大的吸引力。
对于正在寻找高效文档解析解决方案的开发者而言,这个10亿参数的模型无疑值得深入尝试和评估。其开源的特性也允许社区在其基础上进行微调与改进,以适应更多样化的具体需求。想了解更多前沿技术解析与实战心得,欢迎在云栈社区与更多开发者交流讨论。
 发表于 2026-1-27 04:21:13
|
查看: 152|
回复: 0
发表于 2026-1-27 04:21:13
|
查看: 152|
回复: 0
