在与大语言模型(LLM)交互时,许多实践者都会遇到一个共性问题:随着对话轮次增加或输入内容变长,模型的回答容易出现冗余、复读甚至忽略关键指令的情况。这并非偶然,研究发现,大模型处理长文本时的注意力分配模式,与人类记忆中的心理学效应高度相似。
利用心理学中的首因效应(Primacy Effect)与近因效应(Recency Effect),我们可以为优化大模型输入信息的顺序找到坚实的科学依据。
1. 核心现象:被“遗忘”的中间信息
多项研究表明,当输入的上下文过长时,模型的注意力分布会呈现出一条明显的“U型曲线”。模型对序列开头和结尾的信息处理效果最佳,而对处于中间位置的大量信息,其关注度会显著下降,这种现象在技术论文中被称为“迷失在中间”(Lost in the Middle)。
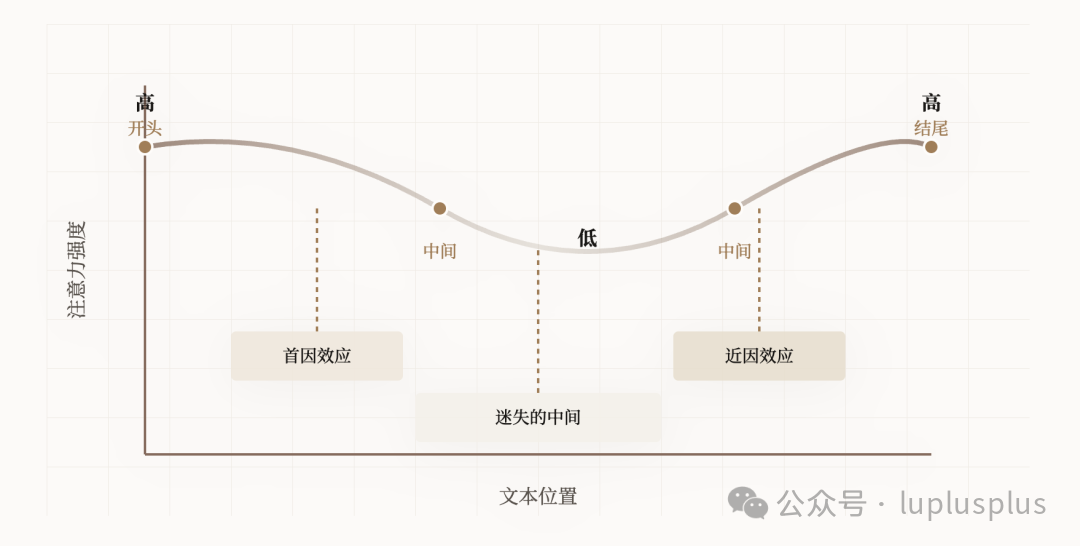
相关研究:Lost in the Middle: How Language Models Use Long Contexts (https://arxiv.org/abs/2307.03172)
2. 从心理学效应到提示词工程
我们可以将这两个经典的心理学效应,直接映射到大模型提示词工程的实践中:
| 效应名称 |
心理学定义 |
在大模型中的表现 |
提示词工程应用 |
| 首因效应 |
第一印象至关重要,序列开头的信息最易进入长期记忆。 |
提示词最前面的指令,基本决定了模型拟扮演的角色和输出的整体基调。 |
设定核心规则:将最关键的身份定义、任务目标和格式要求置于输入的最上方。 |
| 近因效应 |
最近的印象很重要,序列末尾的信息因距离当前时刻最近,最容易被提取。 |
模型在生成回答时,离生成位置最近的指令对其影响最大。 |
明确当前任务:将具体的待处理问题或最后的约束条件放在输入框的最底端。 |

3. 实战技巧:“三段式”输入结构编排
基于上述理论,一个高效的上下文工程策略是采用清晰的“三段式”结构来组织你的输入:

A. 开头:确立权威与基调(利用首因效应)
在输入序列的最顶端,清晰、有力地给出最核心的指令。
- 示例:
你是一名资深的数据分析师。请严格依据以下提供的销售数据,生成一份总结报告。报告需使用专业术语,并包含关键趋势分析。
- 目的:在模型开始处理后续信息前,就锁定其“角色”和任务框架,防止长文本背景稀释核心意图。
B. 中间:放置参考素材(注意力洼地)
将需要模型处理的长篇文档、背景资料、历史对话或原始数据放置在此区域。
- 处理建议:如果中间内容非常庞大,可以为关键部分添加清晰的标记(如
## 原始数据开始 ## 和 ## 原始数据结束 ##),或提供简明的目录摘要,帮助模型更好地理解与定位信息结构。
C. 结尾:强化指令与提问(利用近因效应)
在输入的最后,重申或细化最重要的操作限制,并明确提出具体问题。
- 示例:
基于以上所有数据,请生成报告的执行摘要部分。注意:摘要需控制在3个要点以内,每点不超过100字。
- 目的:在模型即将开始生成回答的“临门一脚”阶段,强化其短期记忆,直接且精准地引导输出行为。
4. 核心结论与行动指南
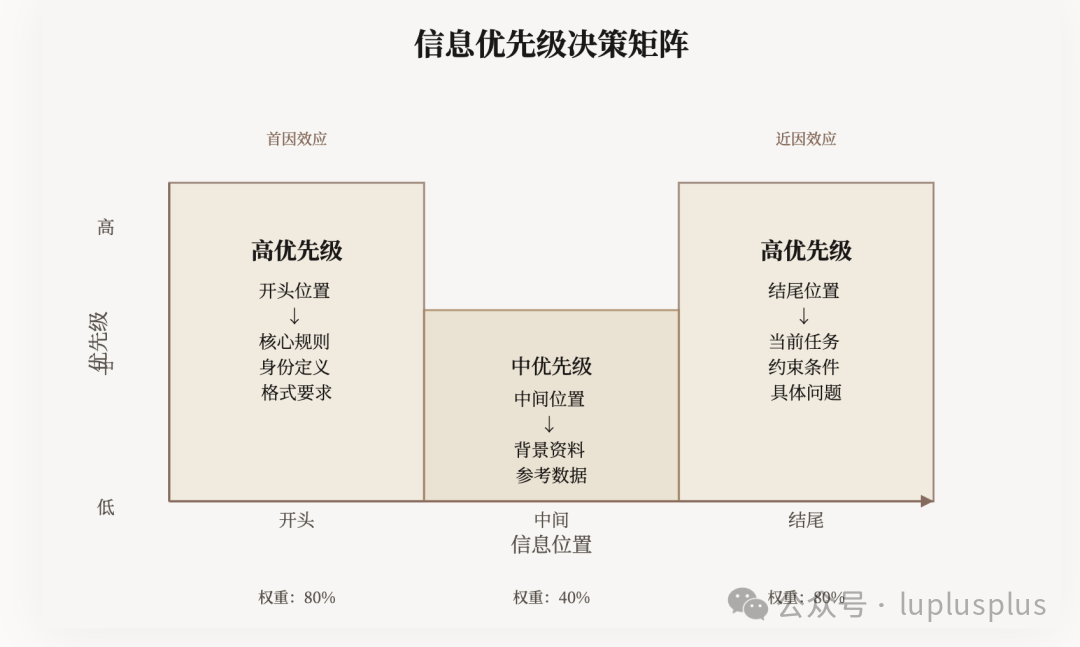
大模型的注意力是一种非均匀分布的稀缺资源。掌握其规律是进行高效上下文工程的关键。
- 如果有必须遵守的“死命令”(如输出格式、角色设定),请务必放在开头。
- 如果有希望立刻执行的“具体任务”(如回答问题、执行分析),请明确放在结尾。
- 如果发现模型反复忽略了某段中间内容,最有效的调试策略之一是尝试将其移动到更靠近开头或结尾的位置。
|  发表于 2025-12-25 09:13:49
|
查看: 323|
回复: 0
发表于 2025-12-25 09:13:49
|
查看: 323|
回复: 0
