
在AI驱动的知识管理时代,构建一个稳定、高效、可扩展的后端架构,是RAG(检索增强生成)应用成功的关键。一个优秀的架构不仅要支撑海量数据的存储与检索,更要优雅地应对分布式系统带来的种种挑战。
本文将分享腾讯AI智能工作台IMA的知识库后端从0到1的完整架构演进之路。通过本文,您将深入了解到我们如何:
- 从满足基本需求的单体应用,逐步演进为支持高并发、高可用的微服务集群。
- 在实践中巧妙解决数据一致性、异步任务、服务拆分等分布式系统的经典难题。
- 为RAG等AI场景,构建一个稳定、可靠、易于扩展的数据底座。
知识库是什么
简单来说,知识库是一个用于集中管理和分享信息的数字仓库。像我们熟悉的iWiki、共享文档、项目资料库等都可以认为是知识库。
传统时代里,知识库+搜索便得到了个人的数字图书馆,用户输入明确的关键词,就能找到想要的书籍和章节。而在AI时代,随着RAG(检索增强生成)和LLM(大语言模型)的出现和普及,知识库的能力得到了飞跃式的升级。它进化成了一个能够理解和对话的“智能助手”。
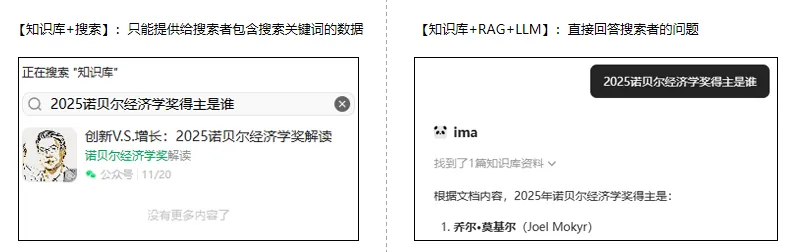
图1-1:知识库应用差异
知识库核心业务流程
在探讨技术架构之前,我们首先需要明确 IMA 知识库的核心业务流程。从用户的角度看,整个系统可以被简化为三个关键环节:知识入库、知识管理和知识应用,这三个环节构成了一个完整的知识生命周期。
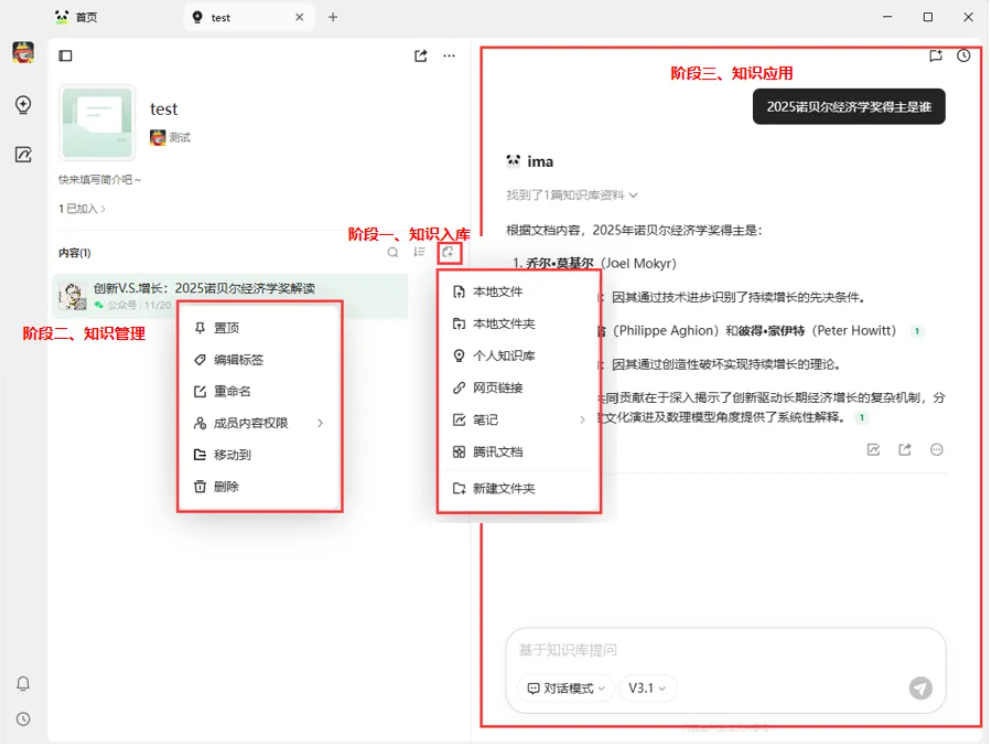
图2-1:知识库核心业务流程
知识库架构设计
知识入库
知识入库是整个系统的基石,其可拓展性和稳定性直接决定了知识库的上限。在设计其架构时,我们面临以下三大核心挑战。
挑战一:数据源的多样性与异构性
从项目立项以来,IMA一直希望能够支持尽可能多的数据格式,从最初的PDF、Word到如今的XMind、各类音频,IMA如今已经支持了20余种不同类型的数据格式。
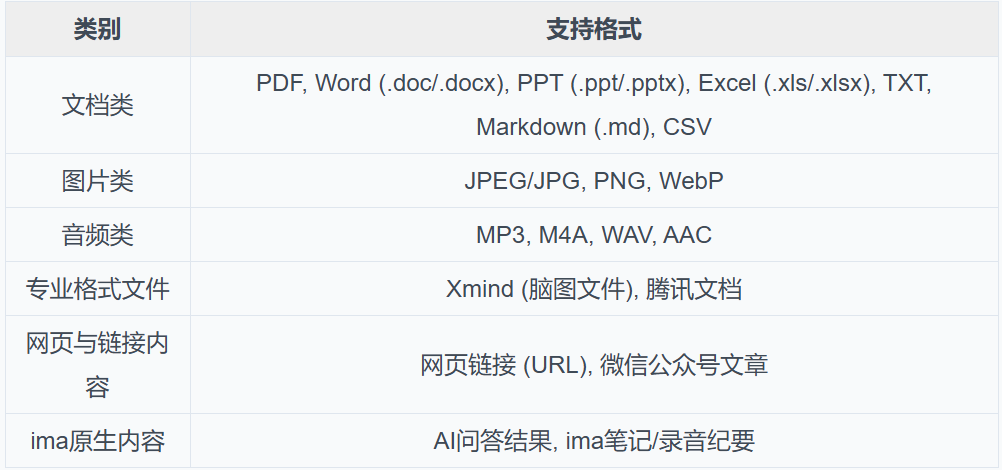
表3-1:IMA支持的文件格式
如果每接入一种新格式,就需要对现有系统进行大幅改动,开发成本无疑是巨大的,系统也将变得高度耦合且脆弱。
解法:建立统一的内部数据格式,解耦外部源与内部系统
我们的核心策略是定义一套IMA专属的、标准化的内部数据格式。无论外部数据源的格式多么多样,一旦进入IMA系统,都将被转换成我们内部的统一结构。这个策略通过两个层面的格式定义来实现:
-
面向用户侧的统一结构:Media
Media是为用户进行展示和管理而设计的统一数据结构。它代表了用户添加到 IMA 的任何一份知识资产。
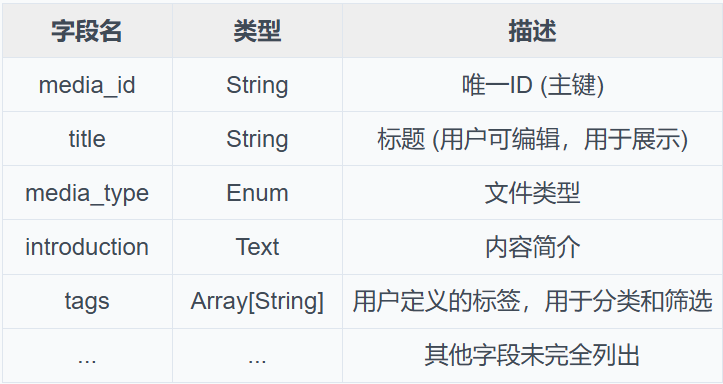
表3-2:Media字段简介
-
面向 RAG 系统的统一结构:Chunk
Chunk是为底层进行解析、索引和 RAG 检索而设计的标准数据单元。它是知识在 RAG 系统内部流通和处理的最小载体。
基于这两个基础概念,我们设计了以下架构作为整体项目的基础原型:
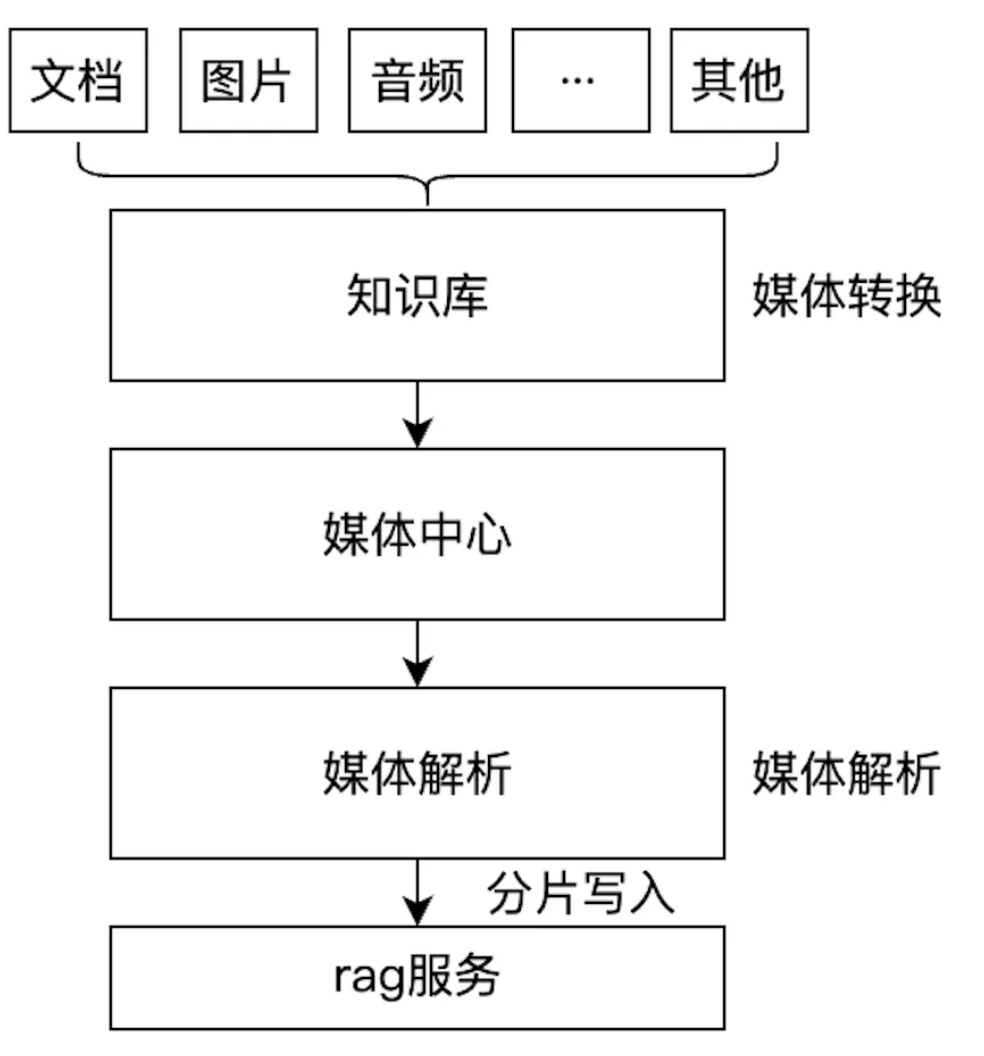
图3-1:基础原型
整个流程分为三个阶段:
- 阶段一:媒体转换 知识库服务作为统一入口,负责接收用户输入的各类数据。它立即将其元信息创建并持久化为统一的
Media 结构,存入媒体中心。
- 阶段二:媒体解析 媒体解析服务会根据
Media 的类型,将原始文件解析并切分成一系列标准化的 Chunk 结构。
- 阶段三:分片写入 这一批结构完全一致的
Chunk 被写入底层 RAG 服务,用于后续的索引、检索以及最终的 AI 应用。
挑战二:处理流程的标准化与统一
不同数据源的获取方式和处理逻辑差异巨大,例如本地文件上传、网络链接抓取、第三方API同步等,如果为每一种组合都编写独立流程,系统将迅速混乱。
解法:隔离变化,构建解耦的知识入库流程
我们将知识库入库流程拆分为两个关注点不同的层级——稳定的“统一接入层”和灵活的“独立解析层”。

表3-4:统一接入层与独立解析层的职责与价值对比
由此我们的架构引入多个新模块,以确保整个入库流程的稳定性与可拓展性:
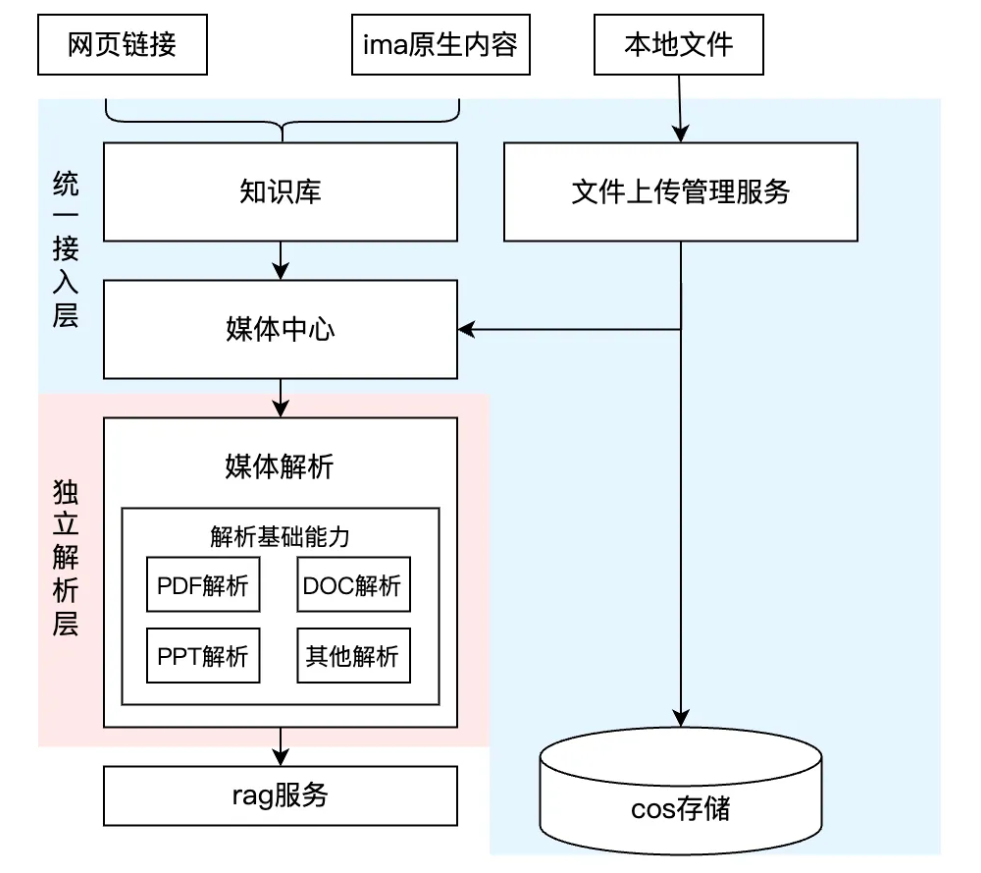
图3-2:统一接入层与独立解析层
挑战三:入库洪峰的冲击与解析能力的瓶颈
IMA 的知识入库流量呈现出脉冲式特征(如团队批量上传),而文件解析是CPU/内存密集型任务,存在刚性瓶颈。同步架构下,洪峰冲击瓶颈会导致请求堆积、超时甚至服务雪崩。
解法:异步削峰与体验优化
我们采用异步化架构,利用消息队列对前端请求与后端处理进行解耦,实现流量的“削峰填谷”。我们结合 IMA 的实际场景做了细节处理,例如用户无感知的快速响应、后台任务的进度追踪与状态同步等。
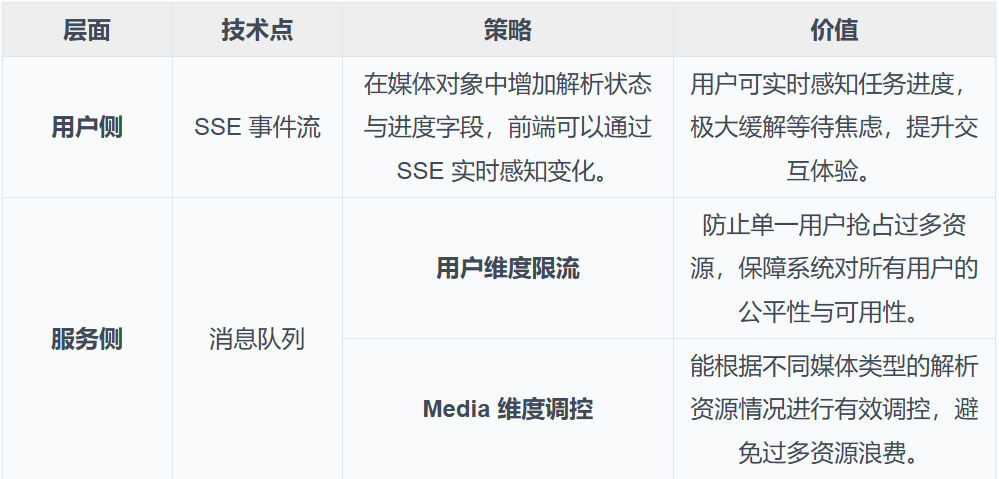
表3-6:异步处理策略详解
系统处理流程更新为下图所示的异步解析架构:
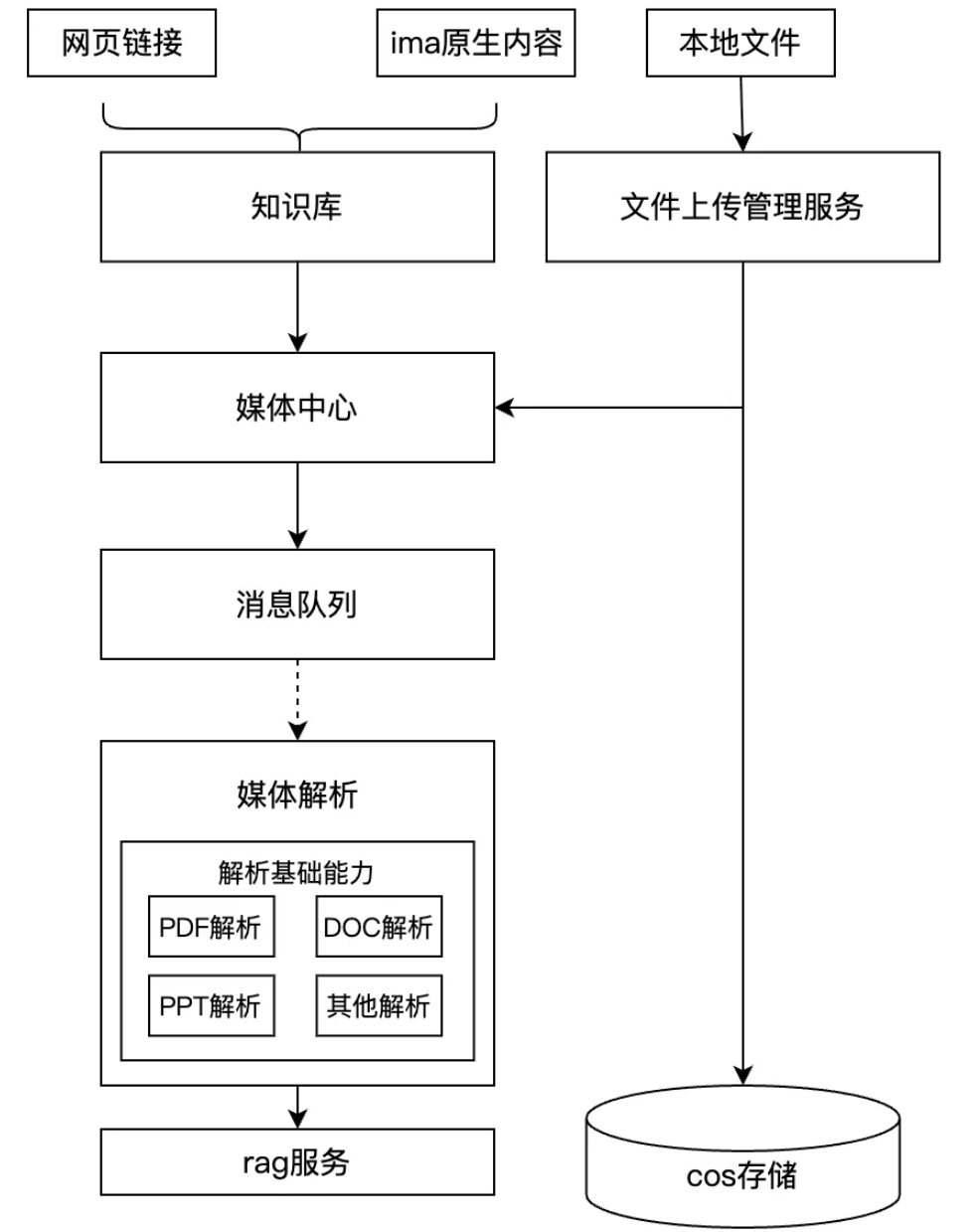
图3-3:异步解析架构
知识管理
解决了知识入库的稳定性问题后,我们聚焦于知识“如何被管好、用好”。随着用户增长,批量修改、文件夹管理等操作对后端系统的可扩展性、一致性和安全性提出了严峻考验。
挑战一:数据操作的复杂化
用户的单一操作,在后端可能演变为需要操作多个组件的复杂流程。例如,“删除知识库内容”需要清理知识列表、Media、分片和COS对象存储中的文件。
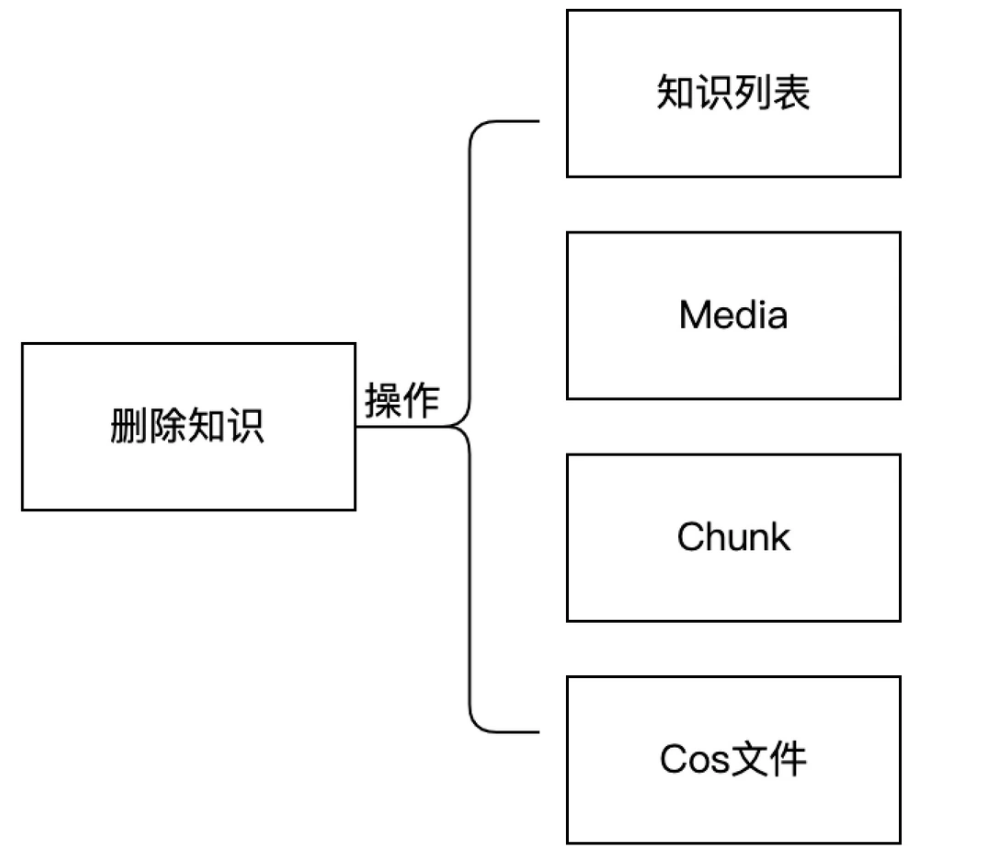
图3-4:删除操作的背后
解法:明确模块职责,聚合业务流程
我们的核心思路是进行彻底的职责分离,将服务系统划分为两大角色:原子服务和聚合服务。
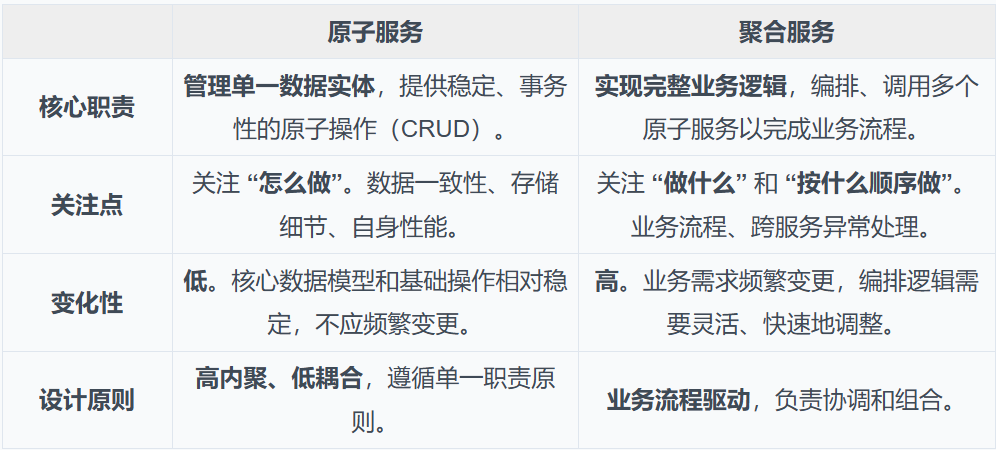
表3-7:服务拆分说明
拆分后,系统架构变得更加清晰和原子化:
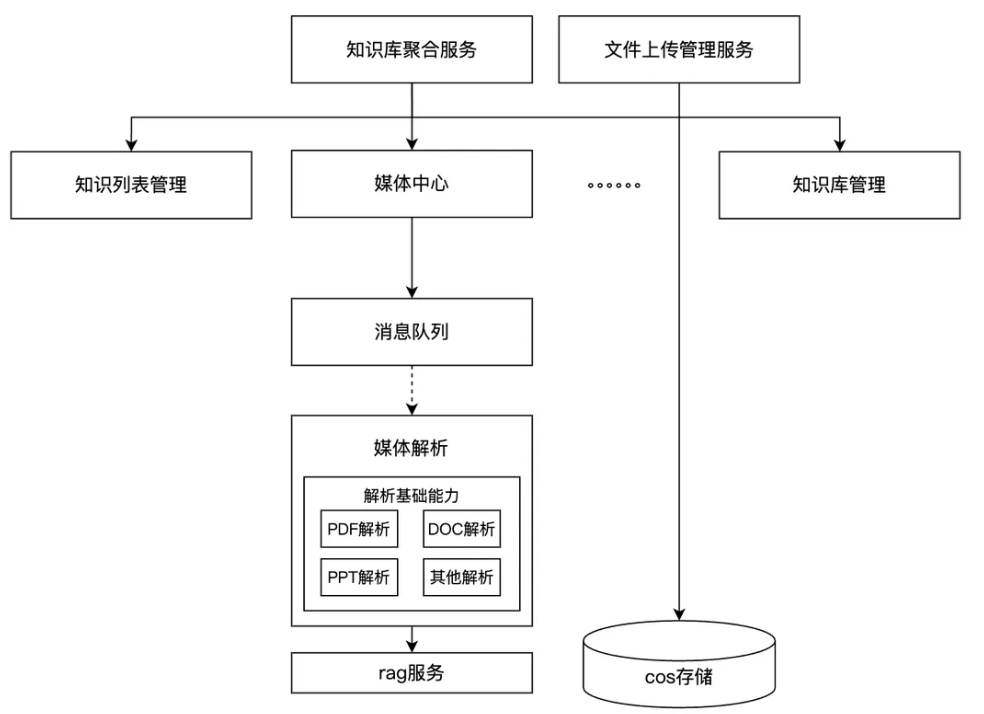
图3-5:服务拆分
挑战二:异步架构下的数据一致性
异步处理Media和Chunk,客观上造成了在任何时间点,用户侧的Media对象与RAG系统的Chunk之间可能存在状态不一致。
解法:以Media为核心,配合最终一致性修正
我们设计了一套双重保障机制:以Media状态为核心,提供即时判断依据;增加异步对账服务,确保最终一致性。这套机制保障了在复杂的数据库与中间件操作环境下的数据可靠。

表3-8:数据一致性保障机制说明
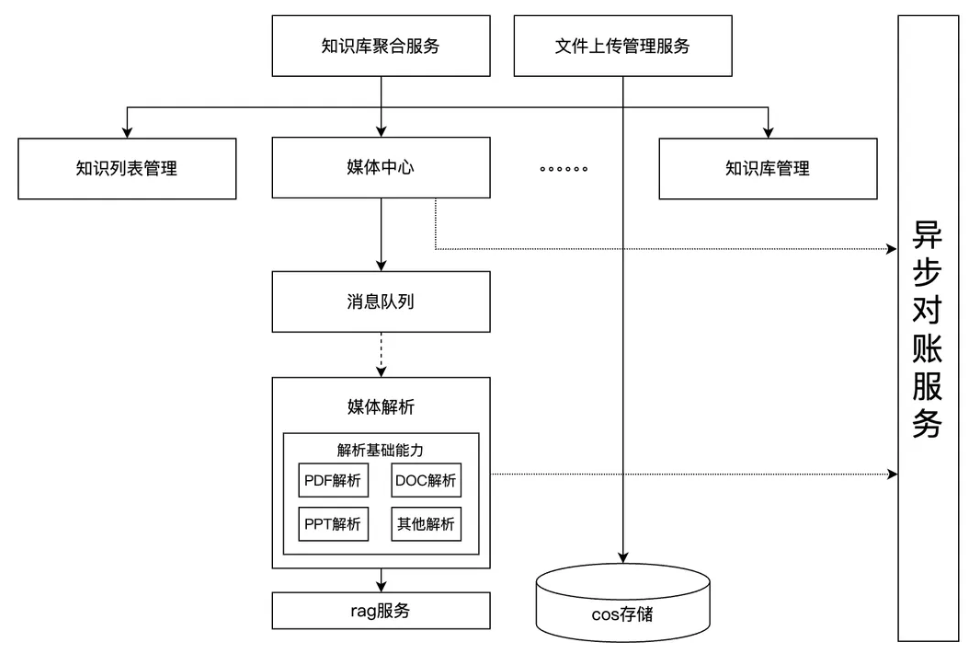
图3-6:增加对账后的框架图
挑战三:多级权限下的数据安全
权限体系是保障数据安全的生命线。IMA 知识库的权限体系需要支持从个人使用到大规模团队协作的复杂场景。

表3-9:IMA权限体系发展史
解法:权限深度建模+统一权限网关
我们确立了明确的架构设计哲学,总体思路概括为两大核心:权限深度建模与统一权限网关。这套体系不仅满足了当前严密、多维度的权限需求,更为未来的功能扩展预留了基础,极大地简化了后端Node.js服务层的鉴权逻辑。
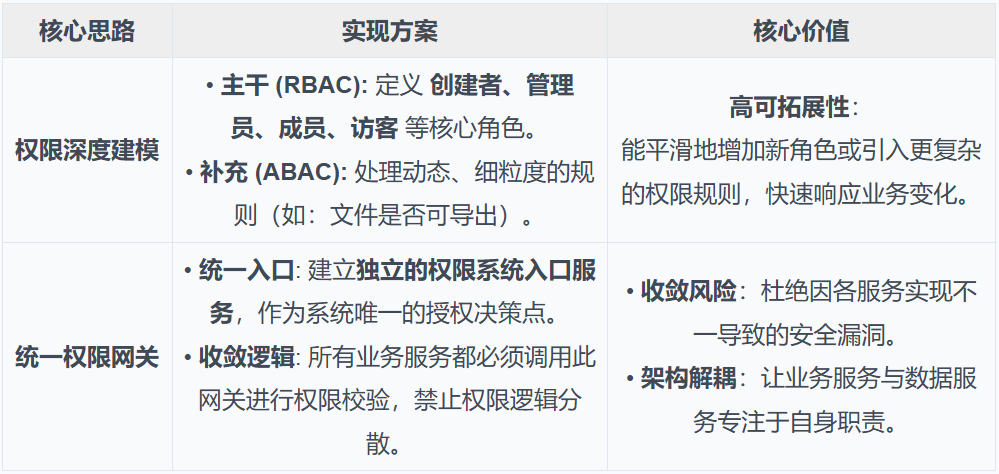
表3-10:权限安全核心解法
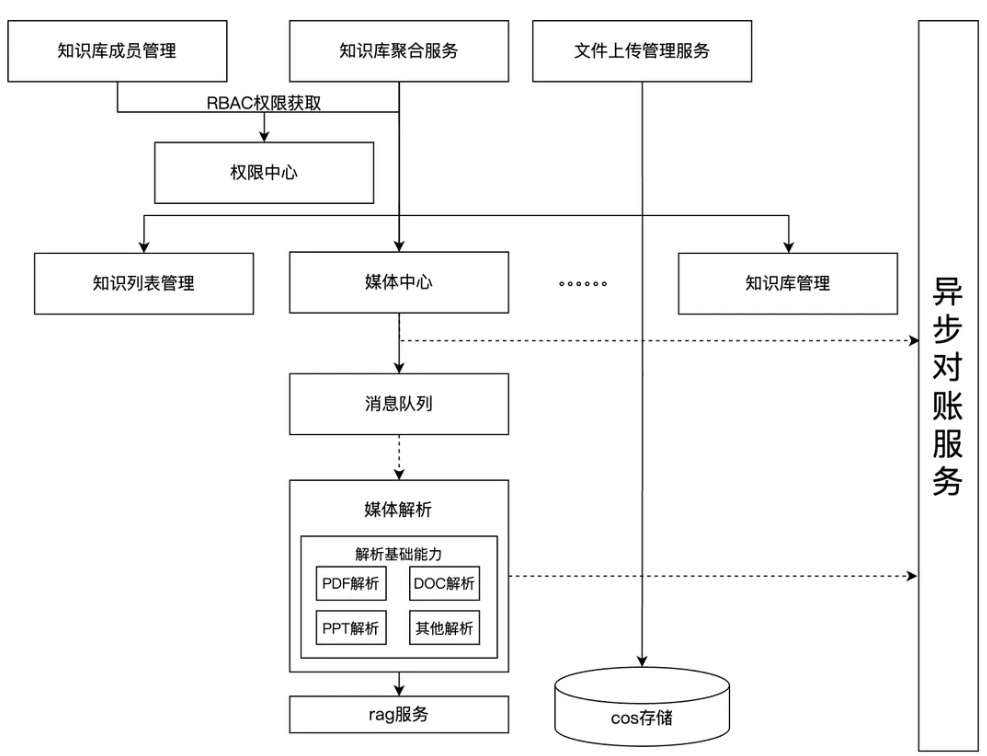
图3-7:演进中的权限体系
知识应用
知识库的核心价值在于应用。在完成了知识入库、知识管理之后,这些高质量、高时效性的私域知识便能够被用户便捷地利用。在IMA中,最核心的应用场景便是基于RAG和LLM的智能问答。本文核心是探讨知识库的架构,AI问答系统的深入架构此处仅作流程性介绍。
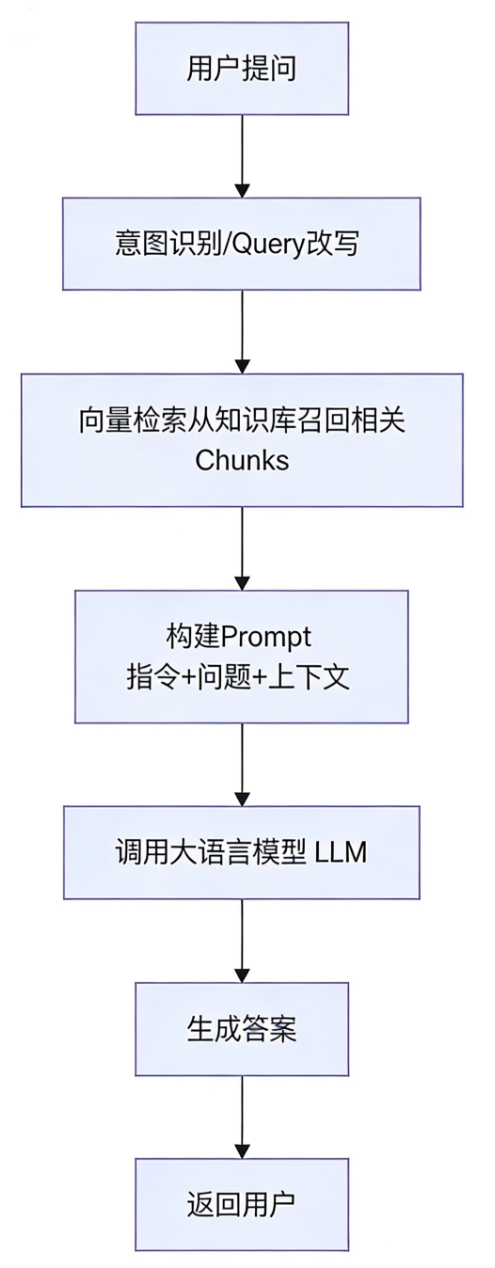
图3-8:简单的问答流程示意图
成果与业务价值
IMA知识库目前仍处于快速迭代和发展的初期阶段,但其核心架构已初步验证了其价值,具体请看下图:

图4-1:IMA知识库的发展
总结
架构的生命力在于演进。优秀架构并非一蹴而就,而是在持续变化的需求中,通过不断识别并优化其薄弱点,逐步演进而成的。IMA知识库的架构演进,正是云原生理念与具体业务场景深度结合的实践。
架构的价值在于务实。软件开发没有银弹,任何方法论的落地都必须结合业务本身,架构设计更是权衡的艺术。衡量其好坏的最终标准,是它能否真正地方便开发、稳健地解决业务难题。
 发表于 2025-12-25 09:55:26
|
查看: 392|
回复: 0
发表于 2025-12-25 09:55:26
|
查看: 392|
回复: 0
