大语言模型(LLM)推理服务正迅速成为企业级应用的核心基础设施,其生产级落地的关键在于平衡性能、稳定性与成本。当前,推理架构正从单体模式向分布式演进,主流方向包括 Prefill-Decode 分离与 KVCache 外置,其根本动因是模型规模与长上下文带来的显存压力。将 KVCache 解耦外置,不仅能突破单机容量瓶颈,更能实现跨请求缓存共享、弹性伸缩等关键能力。
Mooncake 正是为应对这一挑战而生的分布式 KVCache 存储引擎,它为 SGLang 等推理框架提供高吞吐、低延迟的缓存服务。然而,在生产中管理由 Prefill、Decode 和 Mooncake 缓存节点组成的分布式系统,对传统的 Kubernetes 编排能力提出了新挑战:部署运维复杂,且滚动升级易导致缓存丢失,引发性能毛刺。
为根治这些痛点,RoleBasedGroup(RBG) 应运而生。作为面向 AI 推理的 Kubernetes 原生 API,RBG 通过多角色协同编排,将 Mooncake 缓存与 SGLang 推理节点视为同一服务的不同角色,统一管理其部署、升级与弹性,从而在保障性能最大化的同时,提升生产环境的稳定性与可运维性。
Mooncake:面向大模型推理的分布式 KVCache 存储引擎
Mooncake 是 SGLang HiCache(层级缓存)的高性能分布式 L3 存储后端,通过 RDMA 实现跨机 KVCache 共享,突破单机 GPU/CPU 缓存容量瓶颈。
核心组件:
- Master Service: 管理集群存储池、元数据与节点生命周期。
- Store Service: 提供分布式缓存存储,支持多副本、条带化传输与热点负载均衡。
核心特性:
- RDMA 加速 + 零拷贝机制,实现高带宽、低延迟数据访问。
- 智能预取与 GPU 直传,最大化 I/O 效率。
- 支持 PD 分离架构,提升大规模集群 Token 吞吐量。
快速预览:
# 启动 Master
mooncake_master --http_metadata_server_port=9080
# 启动 Store 服务(配置 RDMA 设备与内存池)
python -m mooncake.mooncake_store_service --config=config.json
# 启动 SGLang(启用 Mooncake 后端)
python -m sglang.launch_server \
--enable-hierarchical-cache \
--hicache-storage-backend mooncake \
--model-path <model_path>
RoleBasedGroup (RBG):面向大模型推理的弹性角色编排引擎
核心问题:大模型推理生产落地的五大挑战
大模型推理正演变为“最昂贵的微服务”,生产环境面临五大根本性挑战:
- 快速架构迭代:分离式架构演进快,传统平台难以及时适配。
- 性能敏感:关键指标对GPU拓扑、RDMA亲和性有亚毫秒级敏感度。
- 组件强依赖:关键角色间存在强绑定关系,升级回滚需保持原子性。
- 运维效率低:缺乏多角色统一视角,手动协调导致资源空置浪费。
- 资源潮汐显著:流量峰谷差大,静态配置下GPU平均利用率长期偏低。
RBG 设计理念:角色即一等公民
RBG 将一次推理服务视为拓扑化、有状态、可协同的“角色有机体”。基于此,RBG 提出了面向生产环境的 SCOPE 核心能力框架:
- S – Stable:面向拓扑感知的确定性运维
- C – Coordination:跨角色协同策略引擎
- O – Orchestration:有编排语义的角色与服务发现
- P – Performance:拓扑感知的高性能调度
- E – Extensible:面向未来的声明式抽象
SCOPE 核心能力解析
- Stable (稳定):通过为每个 Pod 注入全局唯一 RoleID,并遵循“最小替换域”原则,确保运维操作在原有硬件拓扑范围内完成,避免拓扑漂移导致的性能抖动。
roles:
- name: prefill
replicas: 3
rolloutStrategy:
rollingUpdate:
type: InplaceIfPossible
maxUnavailable: 1
- Coordination (协同):内置声明式协同引擎,精确定义角色间在部署、升级、故障、伸缩时的依赖关系与联动策略。
coordination:
- name: prefill-decode-co-update
type: RollingUpdate
roles:
- prefill
- decode
strategy:
maxUnavailable: 5%
maxSkew: 1% # 两个角色在升级的过程中新版本比例的最大偏差
partition: 20%
- Orchestration (编排):显式定义角色依赖与启动顺序,并提供拓扑自感知的内建服务发现,将完整拓扑信息注入Pod环境,降低集成复杂度。
- Performance (性能):引入拓扑感知的装箱策略,支持GPU拓扑优先级、角色间亲和/反亲和约束等,以保障TTFT、TPOT等关键指标。
- Extensible (可扩展):通过声明式API与插件化机制,将角色关系定义与部署管理解耦,支持快速适配社区演进的新架构。
基于RBG部署PD分离架构+Mooncake推理服务
部署架构
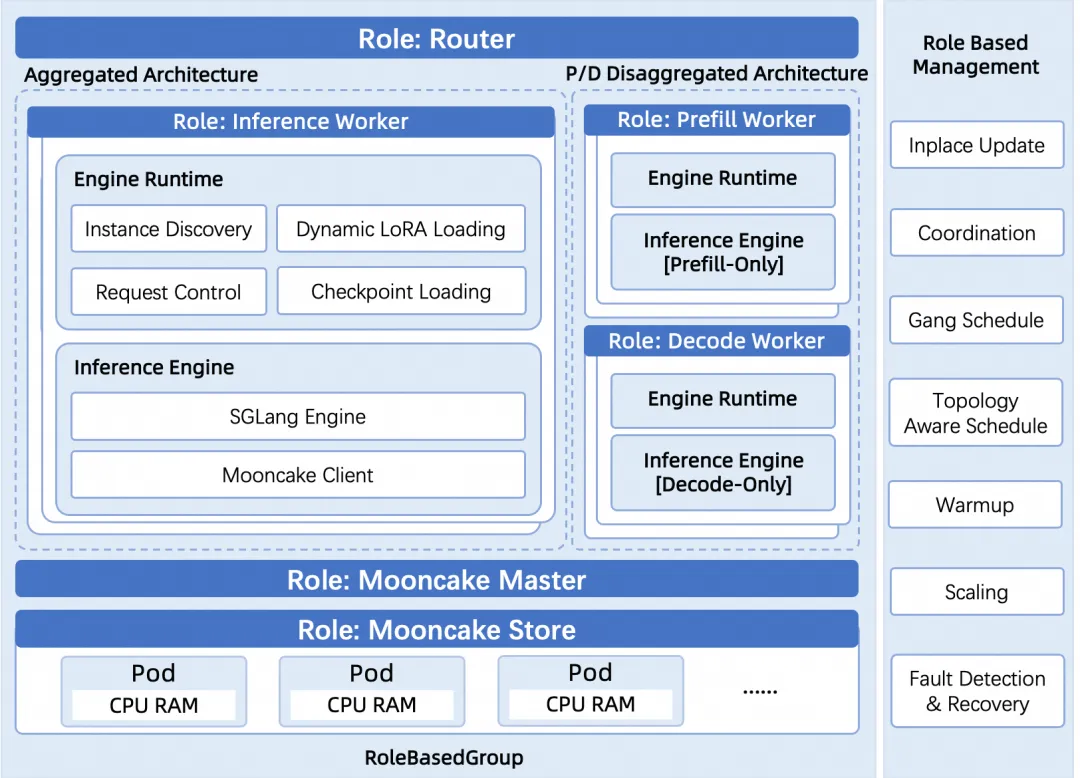
核心角色包括:
- SGLang Router: 统一请求入口与流量调度器。
- Prefill Serving Backend: 处理提示词前向计算,生成初始KVCache。
- Decode Serving Backend: 执行自回归生成,依赖KVCache进行高效推理。
- Mooncake Master/Store: 提供分布式KVCache存储服务,突破单机容量限制。
部署步骤
- 安装 RBG:参考官方安装指南。
- 镜像准备:可使用SGLang官方镜像或参考附录Dockerfile自行构建。
- 服务部署:使用示例YAML文件进行部署,环境变量说明参考Mooncake Store文档。
- 查看部署结果:
kubectl get pods -l rolebasedgroup.workloads.x-k8s.io/name=sglang-pd-with-mooncake-demo
Benchmark 测试结果:多级缓存加速显著
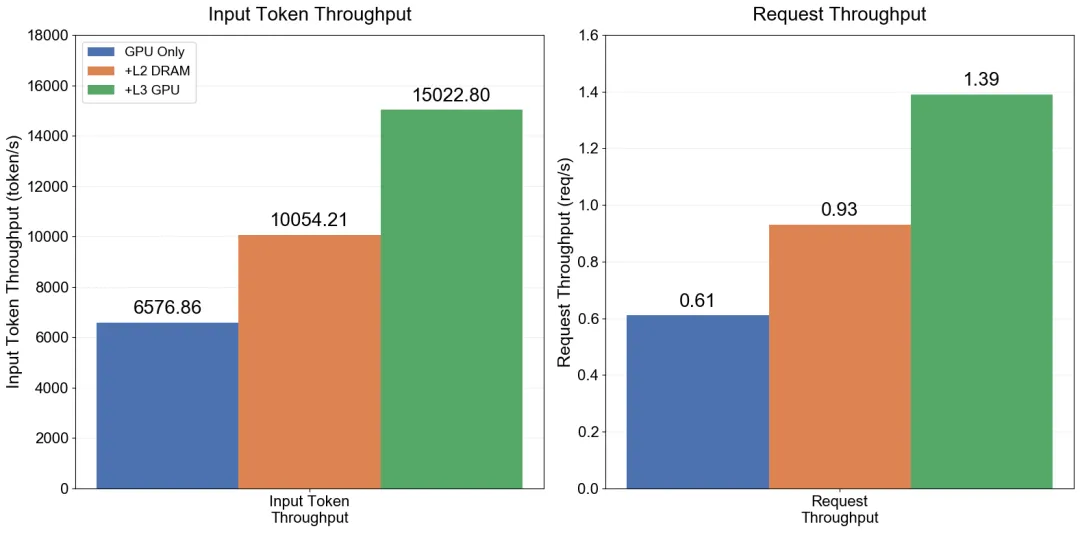
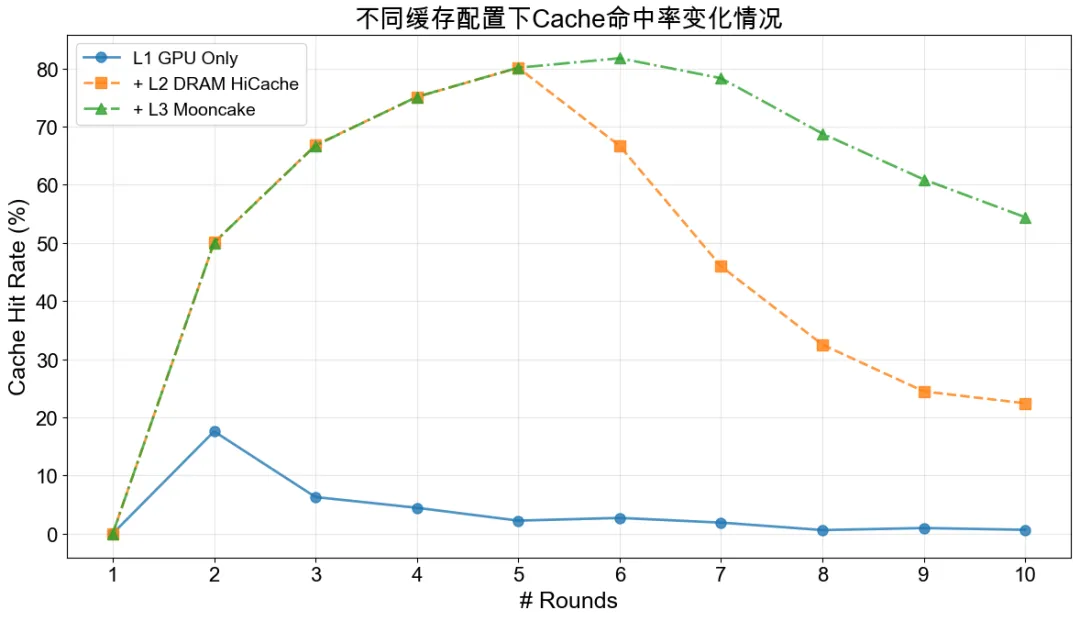
多轮对话场景测试表明,多级缓存架构显著提升了KVCache命中率与推理性能:
- Baseline(仅GPU显存):平均TTFT 5.91s,P90 12.16s,InputToken吞吐 6576.85 token/s。
- L2 DRAM HiCache:命中率40.62%,平均TTFT降至3.77s(↓36.2%),吞吐提升至10054.21 token/s(↑52.89%)。
- L3 Mooncake 缓存:平均TTFT降至2.58s(↓56.3%),P90大幅改善至6.97s(↓42.7%),吞吐提升至15022.80 token/s(↑49.41%)。
通过原地升级实现Mooncake版本平滑升级
Mooncake与推理引擎的transfer-engine需保持严格版本一致。传统滚动升级会导致缓存Pod重建,内存中KVCache丢失,进而引发P99延迟毛刺与吞吐下跌。
解决方案:Mooncake缓存本地持久化 + RBG原地升级。
- Mooncake缓存持久化:支持将KVCache元数据与热数据快照持久化至节点本地,进程重启后可快速恢复。
- RBG原地升级:升级时避免重建Pod,而是原地替换容器镜像并复用本地持久化数据,实现“无缝”版本切换。
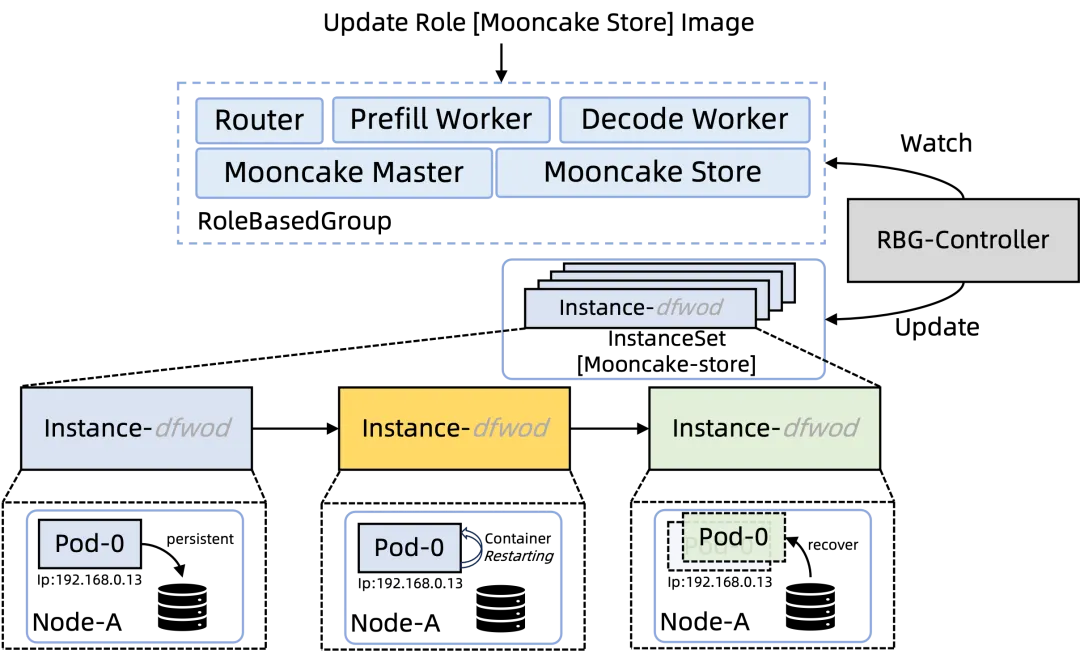
操作示例:将引擎版本从v0.5.5更新至v0.5.6。
kubectl patch rolebasedgroup sglang-pd-with-mooncake-demo \
--type='json' \
-p='[{"op": "replace", "path": "/spec/roles/1/template/spec/containers/0/image", "value": "lmsysorg/sglang:v0.5.6"}]'
升级后,Mooncake Store Pod仅容器重启,Pod本身(包括IP、调度节点)未发生改变,结合缓存持久化能力,实现了升级无感。
总结与展望
本文阐述了如何通过RBG与Mooncake协同,构建生产级的高性能PD分离推理服务:
- RBG 重新定义了LLM推理服务的编排范式,通过多角色协同与拓扑感知调度,解决了分布式部署复杂性,并利用原地升级攻克了有状态缓存服务平滑演进的难题。
- Mooncake 作为L3缓存层,通过分布式内存池与RDMA加速,显著提升缓存命中率与推理性能,同时助力GPU利用率提升。
- 分级缓存架构(GPU HBM → DRAM → Mooncake)被证明是长上下文、高并发推理场景的必由之路。
RBG + Mooncake的实践表明,只有将高性能系统设计与云原生运维能力深度融合,才能让大模型推理真正从“能用”走向“好用”。
附录
镜像构建
部署样例可直接使用官方镜像 lmsysorg/sglang:v0.5.5。定制化构建可参考示例Dockerfile。
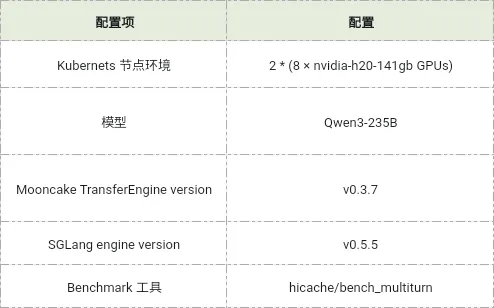
Benchmark测试详情
 发表于 2025-12-25 18:02:24
|
查看: 224|
回复: 0
发表于 2025-12-25 18:02:24
|
查看: 224|
回复: 0