
将AMD、英特尔和英伟达的显卡成功连接到树莓派后,一个核心问题浮现出来:这种配置的实际价值是什么?
树莓派仅有一条PCIe Gen 3通道用于连接外接显卡(eGPU),带宽有限。相比之下,现代台式机通常拥有具备16条PCIe Gen 5通道的插槽,带宽差距悬殊,分别为8 GT/s和512 GT/s。
但带宽是否总是性能的决定性因素?为了探寻树莓派eGPU的实际效用,我们通过四种不同的应用场景,对比了树莓派5与现代台式电脑的性能表现:
- Jellyfin媒体转码
- 纯GPU图形渲染性能(通过GravityMark测试)
- 大语言模型/人工智能性能(包括预填充和推理)
- 多显卡应用(以大语言模型运行为例)
本次测试不局限于单显卡。借助在超级计算大会25上获得的Dolphin ICS PCIe Gen 4外部交换机和3槽背板,我们可以轻松同时运行两块显卡:

结论是:在许多场景下,树莓派都能胜任工作——如果你愿意牺牲2%-5%的峰值性能,它在能效上甚至经常大幅领先!
四卡并行:树莓派的潜力
更令人惊讶的是,在测试期间,GitHub用户mpsparrow成功将四块英伟达RTX A5000显卡连接至一块树莓派。
运行Llama 3 70b模型时,该配置的性能与使用相同显卡的现代参考服务器相差不到2%:
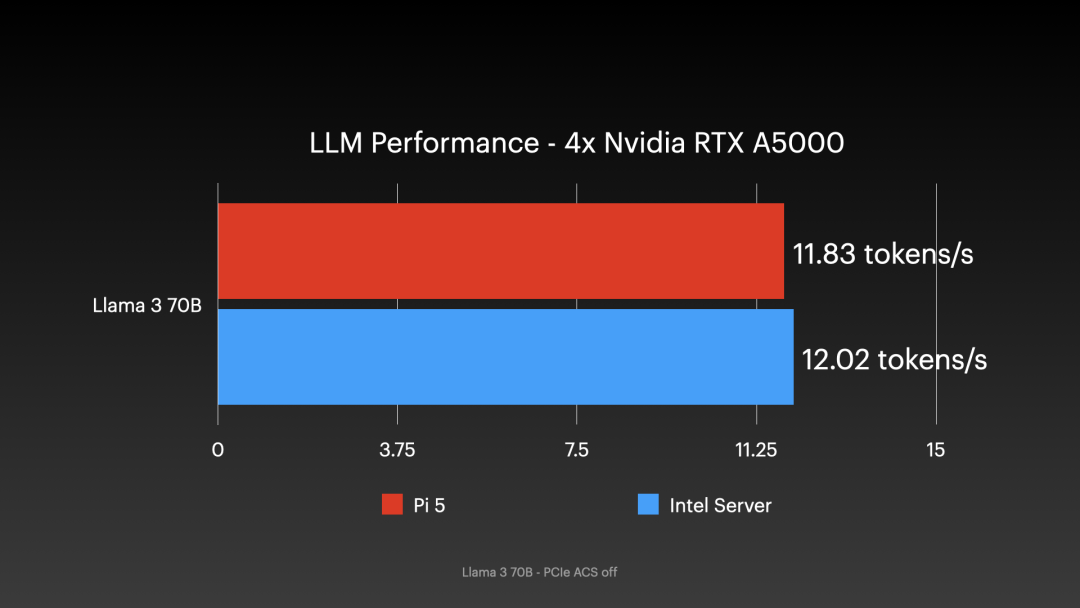
树莓派配置每秒生成11.83个文本标记,而服务器为每秒12个。这如何实现?关键在于,当使用多块支持通过PCIe总线共享内存访问的英伟达显卡时,树莓派本身并非瓶颈。外部PCIe交换机可能允许显卡以Gen 4或Gen 5的速度直接通过总线共享内存,无需经过树莓派有限的PCIe Gen 3通道。
即便不依赖多卡和PCIe交换技术,树莓派在部分场景下的性能仍可媲美甚至偶有超越现代PC。
成本与能效考量
除了性能,成本与能效也是重要因素(以下配置均不含显卡价格):
| 树莓派eGPU配置 |
英特尔PC配置 |
| 总价:350-400美元 |
总价:1500-2000美元 |
| 树莓派CM5(16GB)+ IO板 |
英特尔酷睿Ultra 265K |
| Minisforum eGPU扩展坞 |
华硕ProArt主板 |
| M.2转Oculink适配器 |
Noctua Redux散热器 |
| USB固态硬盘 |
64GB DDR5内存 |
| 850W电源 |
M.2 NVMe固态硬盘 |
| 测试平台/机箱 |
850W电源 |
若不对峰值性能有极致追求,树莓派的空闲功耗仅4-5瓦,而PC空闲功耗约为30瓦(未连接显卡,仅连接基础键鼠)。
单显卡对决:树莓派 vs 英特尔酷睿Ultra
本次测试聚焦于原始GPU性能,暂未包含游戏测试。我们通过三项基准测试来考验每个系统:Jellyfin转码、GravityMark渲染和大语言模型推理。
基准测试结果:Jellyfin媒体转码
首先从最实用的应用开始:将树莓派作为媒体转码服务器。
使用编码器基准测试工具时,PC凭借其高I/O吞吐量大幅领先。树莓派的PCIe总线最高速度约850 MB/秒,且通过USB 3.0固态硬盘持续读写约300 MB/秒。而PC的PCIe Gen 4 x4固态硬盘速度可达2 GB/秒。
然而,对于典型的家庭媒体库(存储H.264/H.265文件),转码所需带宽并不极端。安装Jellyfin并启用NVENC硬件编码后,树莓派表现流畅。
在对1080p影片进行转码或切换比特率模拟远程播放时,均无卡顿。即使是4K H.265文件也能在各种比特率下流畅播放。
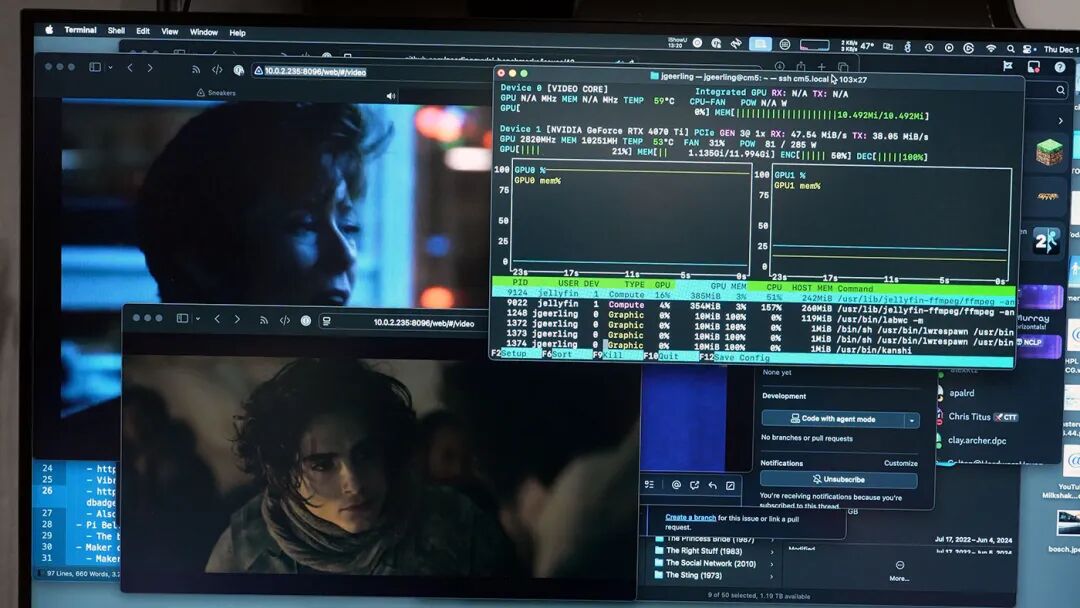
同时处理两个转码任务(如4K和1080p影片)也运行顺畅。虽然解码引擎负载较高,但未造成卡顿。
尽管PC在原始吞吐量上获胜,适合构建全功能转码服务器,但对于大多数家庭流媒体场景(如OBS、Plex或Jellyfin),在Debian Trixie上运行的树莓派已足够使用。
基准测试结果:GravityMark图形渲染
为了测试纯3D渲染性能,我们运行了GravityMark基准测试(目前仅在AMD显卡上完成)。
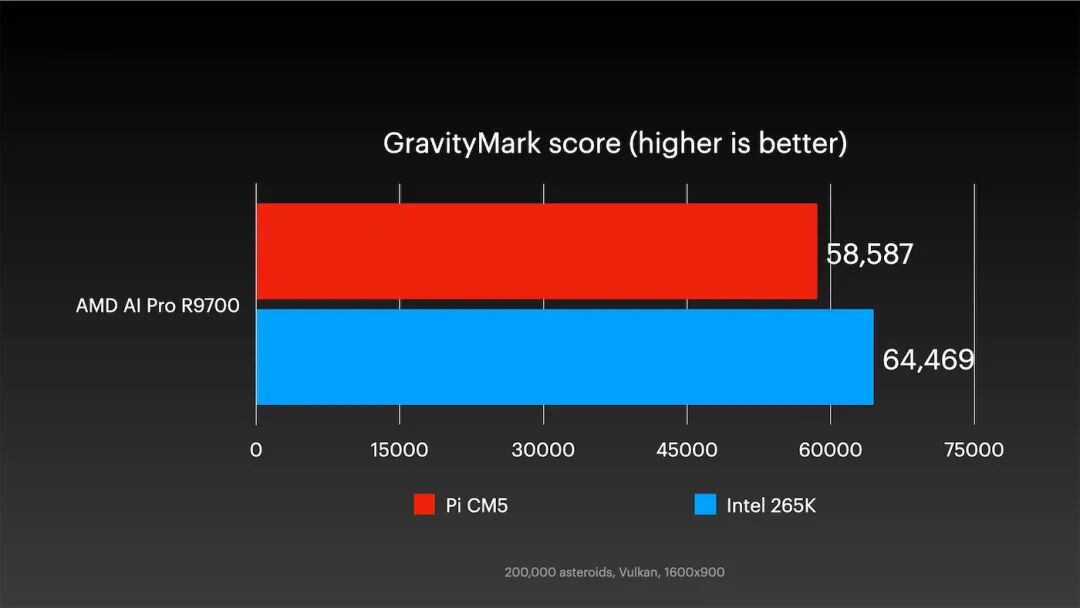
PC速度更快,但优势微弱。渲染工作完全由GPU承担,不依赖树莓派CPU或PCIe通道,因此性能得以较好发挥。
更令人惊讶的是在老款AMD RX 460显卡上的测试结果:
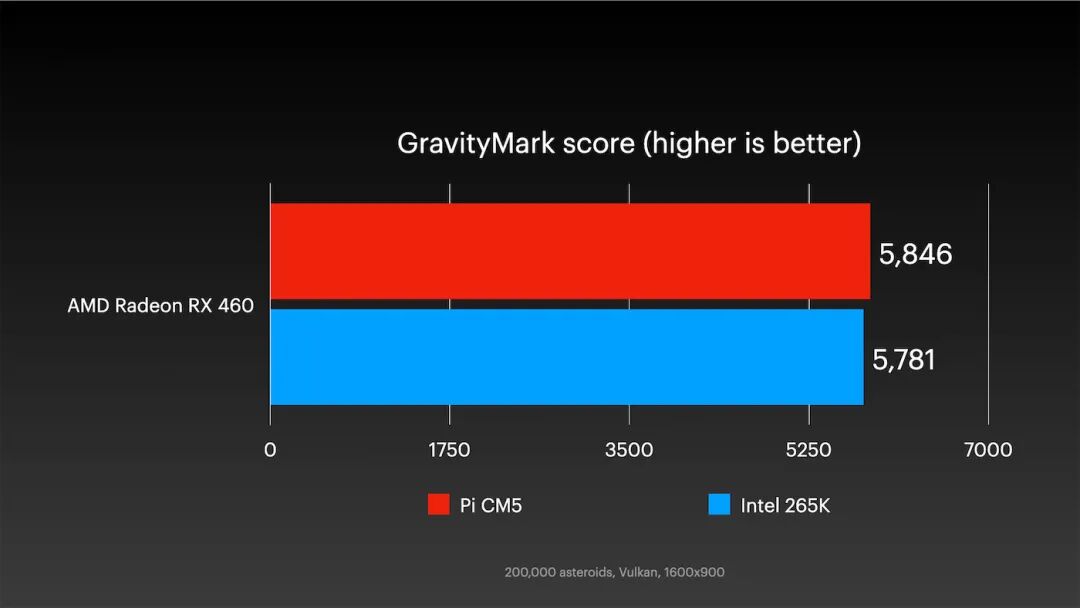
这款老显卡运行在PCIe Gen 3上,与树莓派带宽匹配,树莓派性能甚至略微反超PC。但真正突出的是每瓦性能得分:
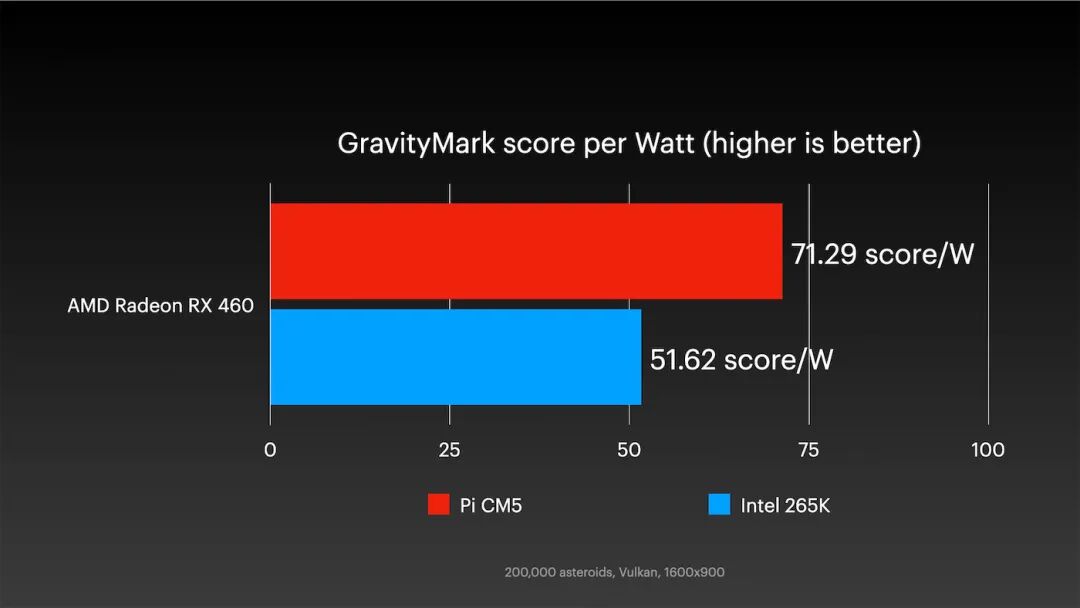
该得分衡量系统整体能效,树莓派在此展现了明显优势。
基准测试结果:人工智能与大语言模型
我们测试了多款显卡的AI性能。以拥有32GB显存的AMD Radeon AI Pro R9700为例,预期适合运行大模型,但实际在树莓派上表现未达预期,可能与驱动或内存支持有关。
转而测试经典的英伟达RTX 3060 12GB显卡,结果更符合预期:
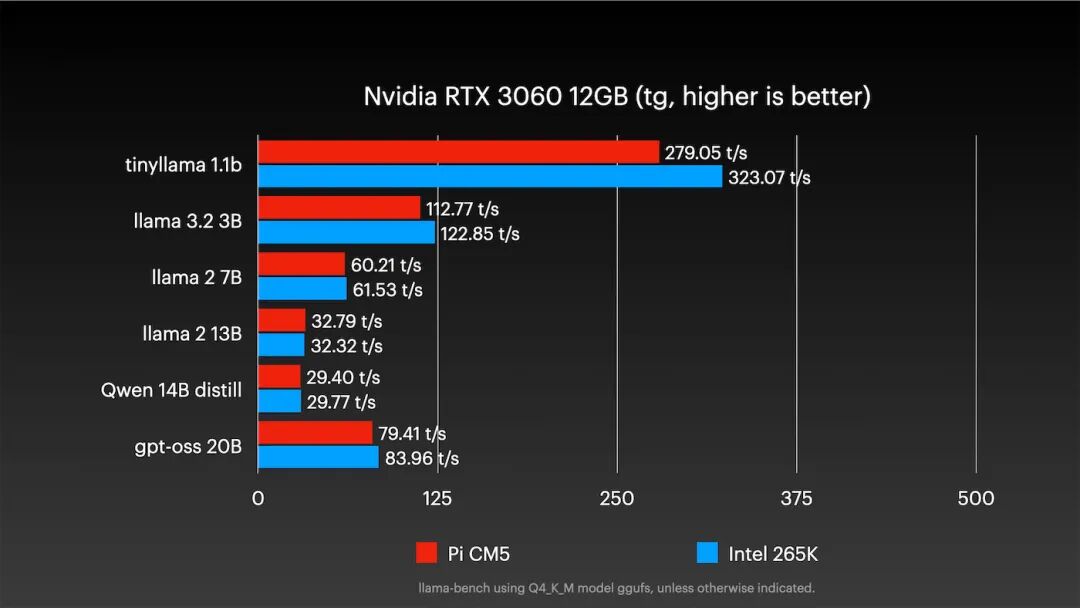
树莓派表现良好。对于部分中型模型,性能与PC相差无几,甚至在Llama 2 13B模型上实现反超。更令人惊讶的是能效对比:
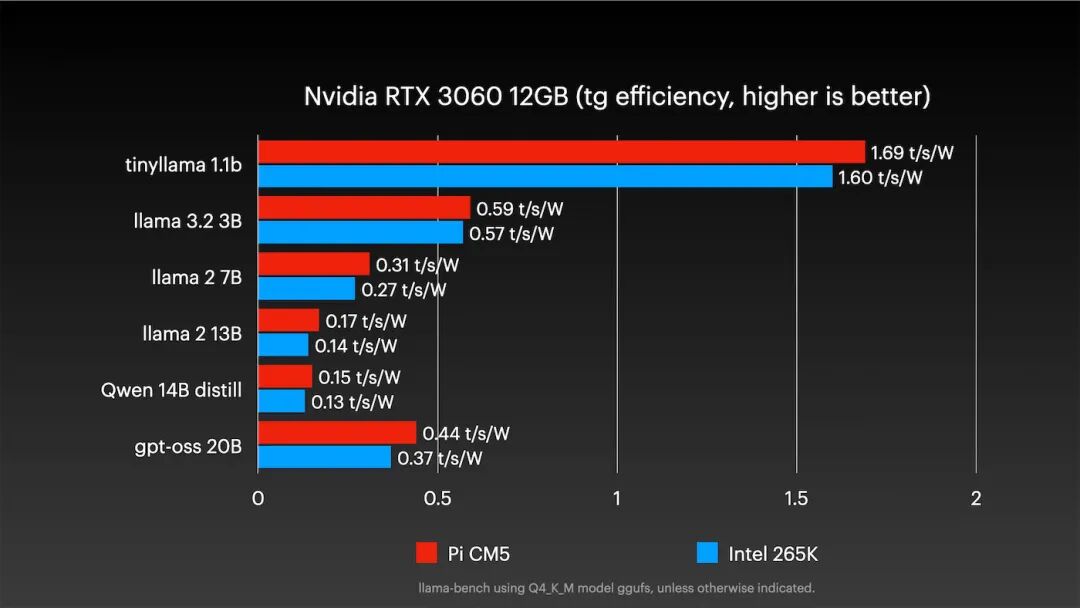
在几乎达到同等性能的同时,树莓派的能效更高。
那么,更大、更新的显卡呢?以顶级的RTX 4090为例:

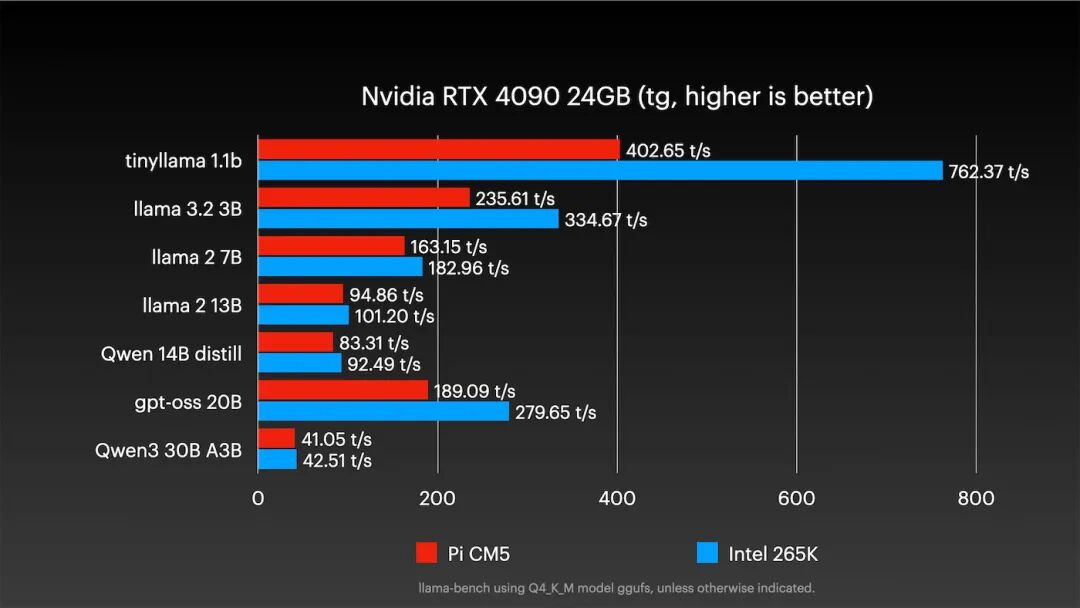
对于大多数模型,树莓派依然能应对,例如Qwen3 30B模型速度慢不到5%。能效方面:
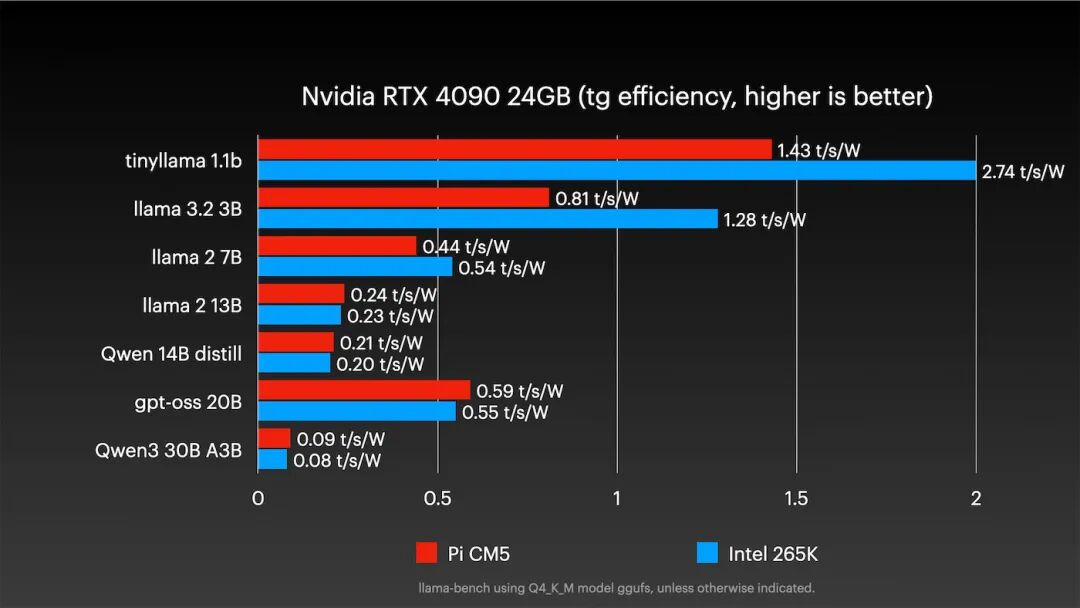
对于大多数大型模型测试,树莓派能效依然略微领先。
双显卡测试
我们使用Dolphin PCIe互连板测试了双显卡配置。理想情况下,PCIe的P2P(点对点)通信功能可让显卡直接交换数据,绕过CPU和树莓派的带宽瓶颈。但此功能通常需要相同型号的显卡。
使用不同型号显卡(如RTX 4070 Ti和RTX A4000)时,虽无法池化显存,但仍可通过llama.cpp等工具利用多显卡运行更大模型。

双卡并行并未提升小模型的速度(因存在数据搬运开销),但允许运行单卡显存无法容纳的更大模型,例如约18GB的Qwen 3 30B模型。
在PC上运行相同的双卡测试,性能自然更快,但树莓派在部分场景下仍展现了竞争力。
最终结论
那么,谁是赢家?
- 追求极致性能与简易设置:传统PC是明确选择。
- 关注能效与特定负载:如果你并非持续满负荷运行,且工作负载主要由GPU驱动(如AI推理、利用NVENC进行媒体转码),那么树莓派eGPU配置是一个高能效、低成本的替代方案,其空闲功耗始终比PC低20-30瓦。
最终,探索树莓派的极限、GPU计算和PCIe技术本身充满了乐趣与启发,这或许就是最大的意义所在。
 发表于 2025-12-25 17:59:39
|
查看: 436|
回复: 0
发表于 2025-12-25 17:59:39
|
查看: 436|
回复: 0
