在日常开发中,处理文本是绕不开的任务。无论是验证用户输入的邮箱格式、从海量日志中提取关键信息,还是替换字符串中的特定内容,正则表达式都是提升效率的强大工具。C++自C++11标准起,便在标准库中集成了<regex>,为开发者提供了原生的正则表达式支持,无需额外依赖第三方库,极大地方便了项目开发。
正则表达式的语法规则相对复杂,涉及各种元字符和修饰符,本文不再展开详述。我们将聚焦于如何在C++中,通过标准库的regex模块来应用这些规则。
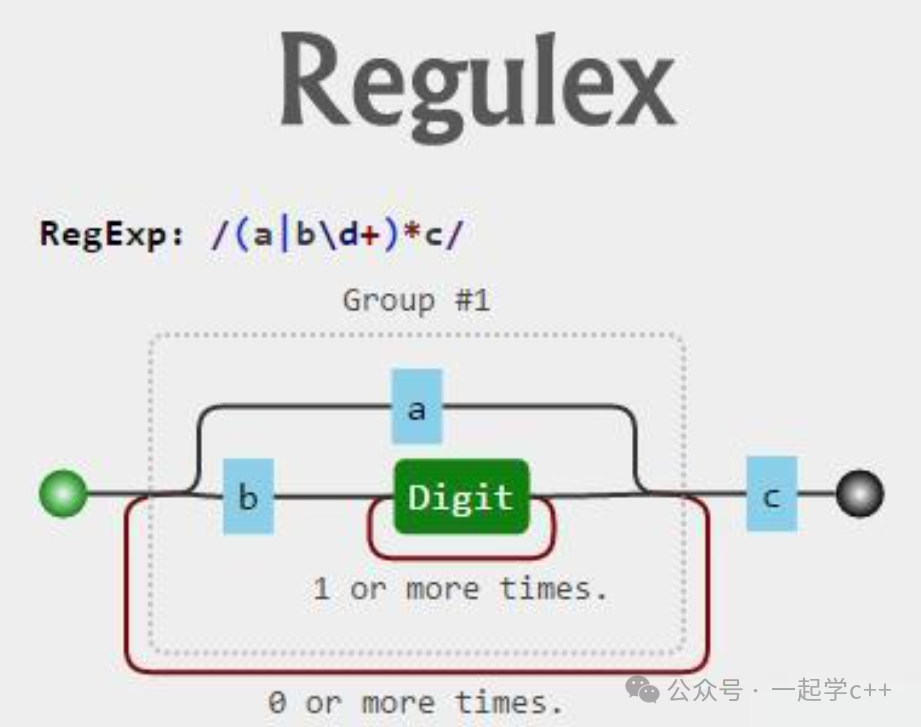
图1:正则表达式结构示例,展示字符、数字、量词和分组匹配
C++ regex库:核心用法解析
C++11标准首次引入了<regex>库,后续的C++14、C++17、C++20标准对其进行了小幅优化与功能补充。目前主流编译器(如GCC 5+、Clang 3.3+、MSVC 2015+)均已完整支持。
该库主要提供三类核心操作:匹配(match)、搜索(search) 和 替换(replace)。其核心组件包括正则表达式对象(std::regex)、匹配结果容器(std::match_results)以及一系列算法函数。
1. 核心组件:regex 与 match_results
std::regex类用于表示一个编译后的正则表达式对象。我们可以通过字符串构造它,并可选择指定匹配标志(如忽略大小写)。
#include <regex>
#include <iostream>
#include <string>
using namespace std;
int main()
{
// 构造一个匹配一个或多个数字的正则表达式
regex reg("\\d+"); // 注意:C++字符串中\需转义,故用\\d
// 构造时指定忽略大小写模式(匹配a-z或A-Z)
regex reg2("[a-z]+", regex_constants::icase);
return 0;
}
这里需要注意转义问题:正则中的\d在C++字符串字面量中需写作\\d。若想避免双重转义,可以使用C++11的原始字符串字面量:
regex reg(R"(\d+)"); // 原始字符串,无需转义
std::match_results类用于存储匹配结果。你可以将其视为一个“结果容器”,它包含了匹配到的完整子串及各括号捕获组的内容。其模板参数常为string::const_iterator,实践中用auto推导更为便捷。
2. 三大核心函数:匹配、查找与替换
regex_match:完全匹配
regex_match用于判断整个字符串是否完全符合正则表达式的模式,适用于格式验证(如手机号、邮箱)。
#include <regex>
#include <iostream>
#include <string>
using namespace std;
bool is_valid_phone(const string& phone)
{
// 正则模式:以1开头,后跟10位数字
regex reg("^1\\d{10}$");
// 完全匹配
return regex_match(phone, reg);
}
int main()
{
string phone1 = "13812345678";
string phone2 = "1381234567"; // 只有10位
string phone3 = "23812345678"; // 不以1开头
cout << is_valid_phone(phone1) << endl; // 输出1(true)
cout << is_valid_phone(phone2) << endl; // 输出0(false)
cout << is_valid_phone(phone3) << endl; // 输出0(false)
return 0;
}
模式中的^和$分别匹配字符串的开头和结尾,确保是“完全匹配”。若需提取捕获组内容,可使用match_results:
void extract_phone_segments(const string& phone)
{
// 分组:第一组是前3位,第二组是后8位
regex reg("^(1\\d{2})(\\d{8})$");
smatch result; // match_results<string::const_iterator> 的别名
if (regex_match(phone, result, reg))
{
cout << "手机号:" << result.str() << endl; // 整个匹配结果
cout << "号段:" << result.str(1) << endl; // 第一组(索引1)
cout << "后8位:" << result.str(2) << endl; // 第二组(索引2)
}
else
{
cout << "无效手机号" << endl;
}
}
注意:match_results的索引0对应整个匹配字符串,索引1、2...依次对应正则中的第1、2...个捕获组。
regex_search:部分匹配(查找)
regex_search用于在字符串中查找第一个匹配正则模式的子串,适用于信息提取(如从日志中提取IP)。
void extract_ip(const string& log)
{
// 简化的IPv4正则模式
regex reg("\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}");
smatch result;
if (regex_search(log, result, reg))
{
cout << "提取到的IP地址:" << result.str() << endl;
}
else
{
cout << "未找到IP地址" << endl;
}
}
若要查找所有匹配,需使用std::sregex_iterator:
void extract_all_numbers(const string& text)
{
regex reg("\\d+");
// sregex_iterator用于遍历所有匹配
sregex_iterator it(text.begin(), text.end(), reg);
sregex_iterator end;
cout << "提取到的所有数字:" << endl;
while (it != end)
{
cout << it->str() << endl;
++it;
}
}
regex_replace:替换匹配内容
regex_replace将字符串中匹配正则模式的子串替换为指定内容,返回新字符串,原串不变。适用于文本清洗和格式化。
string remove_spaces(const string& text)
{
regex reg("\\s+"); // \\s匹配任意空白字符,+表示一个或多个
// 将所有空白字符替换为空字符串
return regex_replace(text, reg, "");
}
替换字符串中可使用$1、$2...引用捕获组,实现智能替换:
string format_date(const string& date)
{
// 分组:年、月、日
regex reg("^(\\d{4})-(\\d{2})-(\\d{2})$");
// $1表示年,$2表示月,$3表示日
return regex_replace(date, reg, "$1年$2月$3日");
}
与第三方库(如PCRE)的对比优势
提到正则库,PCRE功能强大且应用广泛。但C++标准库的regex与之相比,优势明显:
- 原生支持,无额外依赖:作为标准库一部分,只要编译器支持C++11及以上即可使用,无需单独编译链接第三方库,简化了项目构建和跨平台部署。
- 与STL无缝集成:其API设计与标准库的
string、迭代器、算法等组件高度契合。例如,你可以轻松地将regex与std::count_if等算法结合使用,这种与STL的深度集成是原生库的一大优势。
std::vector<std::string> texts = {"user@example.com", "invalid-email"};
std::regex emailPattern(R"(\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b)");
auto count = std::count_if(texts.begin(), texts.end(),
[&](const std::string& s) { return std::regex_match(s, emailPattern); });
对于大多数日常开发场景(格式验证、信息提取、简单替换),std::regex的功能已足够完备。除非你需要极为复杂的正则特性(如某些特定预查),否则引入第三方库的收益有限。
易错点与性能优化:避开常见坑
1. 转义字符:双重转义问题
在C++字符串中,\是转义字符;正则表达式中,\也常用作元字符前缀(如\d, \s)。因此,构造regex对象时常需双重转义。
- 错误示例:
regex reg("\d+"); // \d在C++字符串中是无效转义
- 正确示例:
regex reg("\\d+"); // C++字符串解析为\d,正则引擎识别为“数字”
- 推荐:使用原始字符串字面量
R"(\d+)"避免此问题。
2. 贪婪匹配与非贪婪匹配
regex默认采用贪婪模式,会匹配尽可能长的字符串。例如,用<.*>匹配<div>content</div>会得到整个字符串。若要非贪婪匹配(最短匹配),需在量词后加?。
std::regex greedy("<.*>"); // 贪婪匹配整个标签对
std::regex nonGreedy("<.*?>"); // 非贪婪匹配,只到第一个`>`
3. 线程安全注意事项
std::regex对象本身是不可变且线程安全的。但std::match_results、std::regex_iterator等结果对象非线程安全。多线程环境下,应确保每个线程使用自己独立的结果对象。
// 线程安全的做法:每个线程创建局部的match_results对象
bool threadSafeMatch(const std::string& s, const std::regex& re) {
std::smatch m; // 局部变量,线程私有
return std::regex_match(s, m, re);
}
4. 异常处理:无效正则表达式
如果构造regex时传入的表达式语法无效(如括号不匹配),会抛出std::regex_error异常。建议进行异常处理。
try {
std::regex invalidReg("(\\d+"); // 括号不匹配
}
catch (const std::regex_error& e) {
std::cout << "正则表达式无效:" << e.what() << std::endl;
}

图2:编译无效正则表达式时抛出的std::regex_error异常信息
5. 性能优化:避免频繁构造regex对象
构造(编译)regex对象是比较耗时的操作。切忌在循环内部频繁构造。
- 性能差的做法:
for (const auto& phone : phones) {
if (regex_match(phone, regex("^1\\d{10}$"))) { // 每次循环都构造
// ...
}
}
- 性能优的做法:
regex reg("^1\\d{10}$"); // 在循环外构造一次
for (const auto& phone : phones) {
if (regex_match(phone, reg)) { // 循环内复用
// ...
}
}
总结
C++标准库中的regex模块为文本处理提供了强大、便捷且跨平台的原生支持。掌握其三大核心函数——regex_match(验证)、regex_search(提取)、regex_replace(替换)——以及regex对象、match_results容器的用法,足以应对绝大多数开发场景。
关键要点在于:注意C++字符串与正则的双重转义问题;理解贪婪与非贪婪匹配的区别;在多线程环境中正确管理匹配结果对象;最重要的是,避免在性能关键路径上重复构造regex对象以提升效率。
熟练运用std::regex,能让你在处理复杂字符串逻辑时事半功倍。如果你想深入探讨更多C++标准库的实用技巧,欢迎在云栈社区与其他开发者交流学习。
 发表于 2025-12-30 06:48:05
|
查看: 340|
回复: 0
发表于 2025-12-30 06:48:05
|
查看: 340|
回复: 0
